Good catch. You’re right. I think @pihentagy made a mistake in his example there.
ok : ) this solves part of my initial confusion as you both seemed to agree on the output.
Why two tabs? Because that defines a 3rd level “-” block in Logseq. Also I wanted to see what Logseq do with it after a # block (…) Also because GFM Markdown specs specifically allow such markup and describe how it should be rendered.
thanks I was wondering what was the expected output, in fact this markup is working but it’s rendered as a code block in most md editors
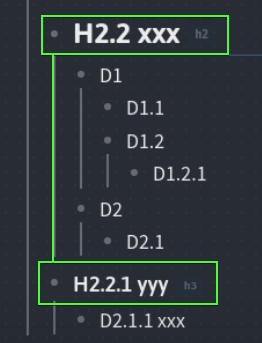
. I’ve tested in Logseq v0.2.5 and found that it treats ### H2.2.1 as top-level, and make - D2.2.1 as 2nd level (not 3rd).
The simplest is just literally enter all those markdown formatting on input, just storing them as is. That seems to be what current Logseq do.
as you noted in current logseq, there are currently two behaviors for headings:
- top levels headings are treated as a new section (bullet), disregarding the actual number of
#
- headings in sub levels are just a display style, they do not impact the hierarchy
- in current logseq, hierarchy is based on the absolute indentation : no tab = root level, 1 tab=level 1, 2 tabs = level 2, etc (I use tab for convenience, it can apply to 2 spaces or 4spaces too)
the request to have headings acting as hierarchical markers too (as in most markdown editors) would alter the paradigm as it implies that - dashes and tabs become relative indentations (relative tio their heading’s own indentation), as highlighted in your examples.
so in this case :
## H2.2 xxx < lv1
- D1 < lv2
- D1.1 < lv3
- D1.2 < lv3
- D1.2.1 < lv4
but if we add a new heading on top , all levels are offset
# new heading < lv1
## H2.2 xxx < lv2 , level is offset
- D1 < lv3, level is offset
- D1.1 < lv4, level is offset
- D1.2 < lv4, level is offset
- D1.2.1 < lv5, level is offset
so the level of indentation of the raw file (tabs) doesn’t match the ‘actual’ level of of the tree structure (and this is disregarding more complex cases with ### h3 in the middle etc… which is one of the issue mentionned by @ChrisVn :
> It becomes problematic when we try to render an outline in such a way,
> that it is no longer obvious which blocks are on which level.
just to make it clear : I’m not trying to embarrass with trick questions, I’m genuinely wondering what is the expected behavior and how this should be solved.
is the heading structure more important than the indentation ? (which goes againsht the concept of an outliner imo) or what rules should apply ?
@ChrisVn
What I don’t want is for Logseq to lose its outline capabilities in favour of free text. But a clever combination of both capabilities would be interesting
my feelings exactly.