Hi,
Page references and tags are “inherited” by children blocks, this way you can use Linked References and Simple Queries to retrieve blocks according to references in their parent blocks.
The idea is that you just type notes, indent them as it make sense to you and turn some words into page references or tags. It’s a natural workflow but it also populates Linked References sections and Simple Queries in a meaningful way.
You have not to think much about it, but with this in mind you can write a single page reference in some blocks and write stuff in children: those blocks will inherit the references, resulting in a hierarchical organization that resembles files and folders.
For more read this:
Notice that block properties (probably what you call metadata) are not inherited, so you can use queries like (property key value) to retrieve specific blocks and not their children. So you can use properties to complement the structure given by references and tags.
A graph view like that is in general used to see how nodes aggregate. It works well with a lot of data, like the one from social networks i.e. a so called social graph.
As it is now the graph view in Logseq is not much more than a toy, but you can use the Graph Analysis plugin to get a graph like this:
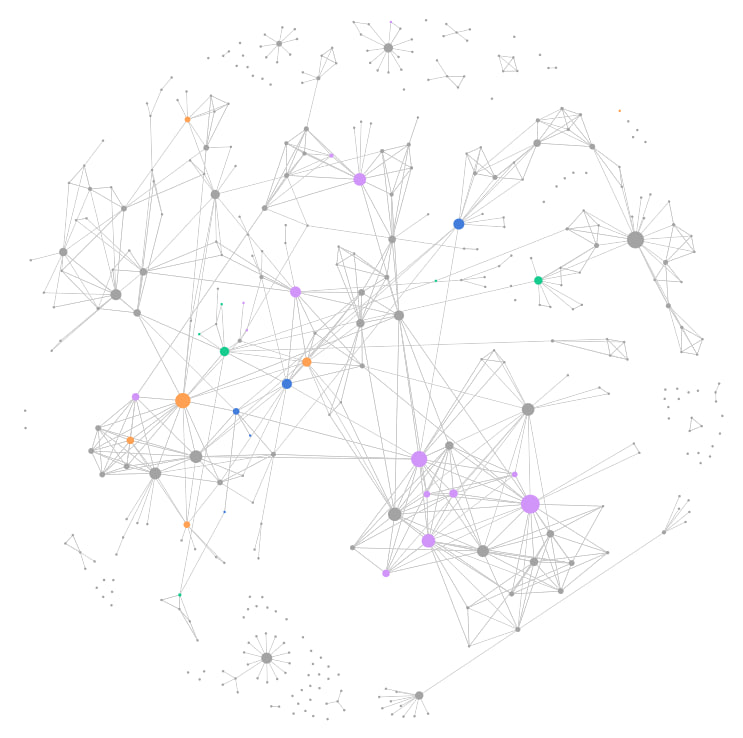
It also lets you color nodes using Simple Queries syntax. This feature makes it actually useful to find specific pages.