This one is for the historians out there.
Logseq offers a lot of support, right out of the box, for querying and sorting journal entries by date. But for many users it’s their notes they will want to query and sort by date, not their journal entries. This is especially true for historians, who would typically use Logseq to keep track of the many primary documents they’ve read. They might find it very helpful, as I do, to later be able to sort their notes by keyword and the date of the source material on which those notes draw. In this way you get a kind of running commentary by contemporaries on the events of the day.
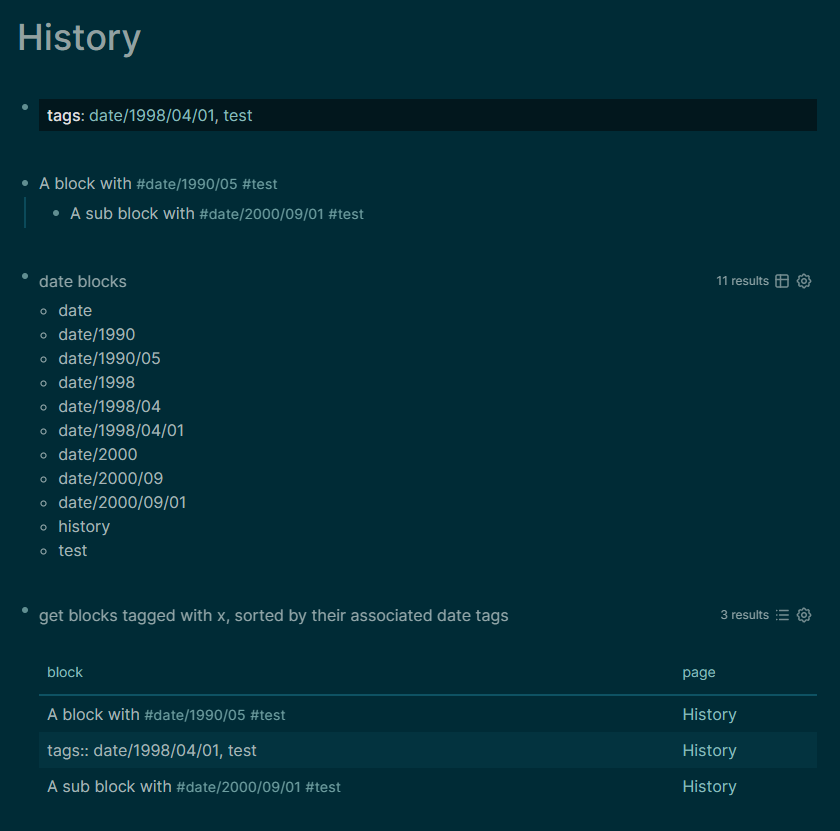
I had long been tagging my extensive notes on eighteenth-century money, banking and public finance, with the dates of the primary source materials (or, in the case of secondary sources, of the periods/events) to which they referred. I had hoped that the move to Logseq (from Roam Research) would provide me with a proper date type into which these tags could be converted. But I quickly discovered that Logseq’s built-in use of date fields, and the query machinery built around them, is confined to its journalling system. So I settled instead on custom hierarchical date tags of the general form #date/yyyy/mm/dd (with month and days optional, and with dashes instead of digits to indicate approximate dates (e.g. 178- to refer to anything in the 1780s).
Since in Logseq child blocks inherit tags from their parents, I could stick with my existing system of assigning only a relatively few date tags, each at some relatively high level in my notes (e.g. a chapter heading) and covering all the children beneath them. As I worked my way through a given source, I might have to update the associated date tag as the source material moved into later time periods. Even so, there aren’t many date tags in my notes; they’re not nearly as numerous as my keyword tags. Sometimes I need only a single date tag for an entire document, in which case I just add it to the tags:: property for that page.
So far so good, and relatively straightforward (though very labour intensive if you’re adding date tags after the fact). And to pull a list of blocks for any one keyword tag, or some combination of them, Logseq’s basic queries will work just fine, which is nice since the GUI tool makes that sort of thing easy.
But a real problem arises if you want to sort the blocks for a given keyword by the date tags associated with them. In that case you absolutely must use an advanced query.
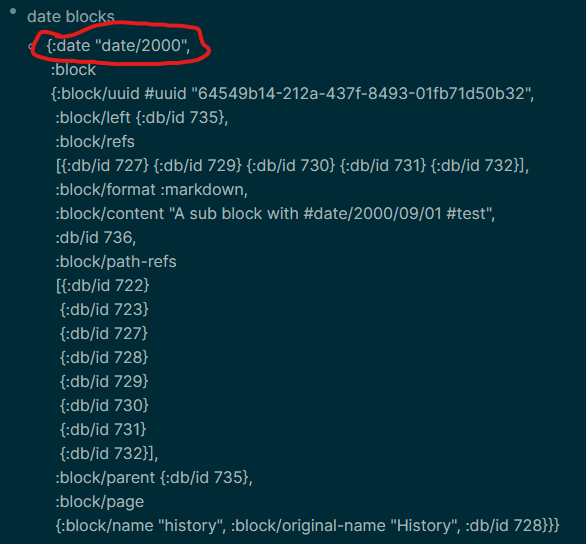
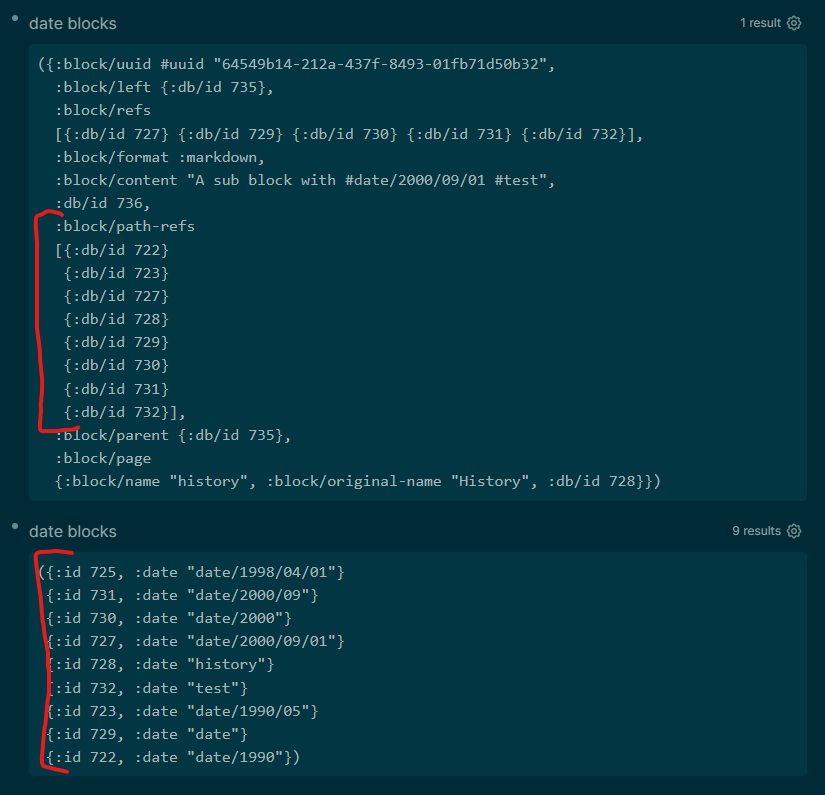
The first step was to make sure that the names of the associated date tags were included in my query result set. This wasn’t exactly easy. The relevant date tags can be found at any of three places: a) on the block itself (in which case a call to block/refs will pull it in); b) on some parent of that block, perhaps several levels up (these will be found in block/path-refs); or c) in the page tags (to be found at {:block/page [:block/tags]}) I couldn’t find a way to build a series of :where clauses that would pull out those three different pieces of information and link each of them to some simple variable declared in the :find clause. So I solved the problem instead by using Datalog’s pull API, grabbing the page names of the full set of tags associated with each of the three possible locations for date tags. I also pulled in the :block/content and (the page’s) :block/original-name fields, to allow Logseq to work its default table-view magic with the eventual result set. It took some work to figure out how to get the desired output, since the Datalog/Datomic documentation isn’t exactly generous in its coverage of hierarchical/namespaced keywords, which of course are rampant in Logseq’s database schema. In any case, the raw query result set is a pretty ugly mishmash of vectors and maps, some of them nested several layers deep. But this approach gets you all the information you need to solve the date sorting problem and display the results.
The final step, sorting the results by date tag, was by far the hardest. It took me ten or so days to sew that part up, though in fairness this was largely because I am a complete noob when it comes to Clojure and to the result-transform component of Logseq’s advanced queries. It didn’t help that Logseq’s documentation doesn’t provide an actual specification of the result-transform (or either for that matter of the view) clause, just a set of examples. And the real work for me came from the fact that Clojure is a completely different kind of programming language than any I’ve encountered before. It took quite a while to wrap my head around its function-centric design and its insistence upon destructuring any data that gets passed to functions. Thank god for the REPL that comes with Clojure’s clj terminal tool, which facilitates trial-and-error learning. But I worked out a solution in the end. Someone who knows Clojure better could surely write up my formulation more elegantly. Suggestions welcome.
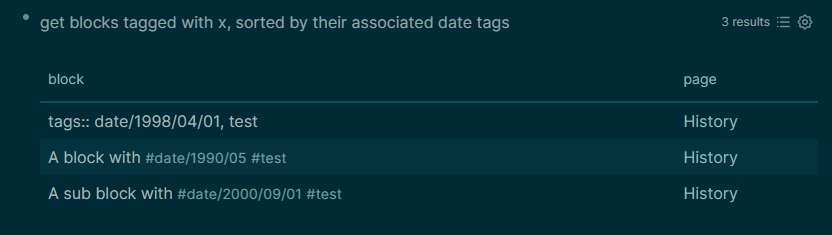
In list view, the query generates nothing more than an long, ugly set of text fields, arranged as vectors and nested maps. I suppose I could try to write up a corresponding view that would present this information in a much more orderly fashion, ideally including the breadcrumbs that come with Logseq’s default list view. But you can get a reasonably serviceable view without all that work just by setting the query results to table view and then left-clicking on any blocks that looks interesting; this will open the standard Logseq query result view for those blocks in the right panel.
Notice that the query results are sorted by the most appropriate date tag: the one closest to the block tagged with a given keyword (in order of priority, on the block itself, on a parent of the block, or on the page as a whole)
I’m sharing the whole query below, in case anyone else has been looking for a solution to this problem – to spare you the work I had to go through to figure it out myself.
#+BEGIN_QUERY
{
:title ["get blocks tagged with x, sorted by their associated date tags"]
:query [
:find (pull ?b [:block/content
{:block/refs [:block/name]}
{:block/path-refs [:block/name]}
{:block/page [:block/original-name {:block/tags [:block/name]}]}])
:in $ ?tag
:where
[?t :block/name ?tag]
[?b :block/refs ?t]
]
:inputs ["chosen keyword"]
:result-transform
(fn [result]
(defn get-date [refs]
(for [elem refs
:let [tag (get-in elem [:block/name])]
:when (clojure.string/includes? tag "date/")]
(subs tag 5)))
(sort-by (fn [row]
(let [{:keys [block/refs block/path-refs block/page] {:keys [block/tags]} :block/page} row]
(or (first (get-date refs)) (first (get-date path-refs)) (first (get-date tags)))))
result))
:group-by-page? false
}
#+END_QUERY