People have brought this argument up in the past, but I don’t agree.
A relational database has tables that store relations. Data is often stored in fairly small chunks and is typed. Logseq doesn’t store tabular data, and doesn’t even support textual tables well.
A good example of a relational approach is Zotero, which allows pdf annotations just like Logseq, but stores the annotations in its SQLite database instead of in a text file. If you look at a note in Zotero, it is split into hundreds of little relations. This is not even remotely similar to Logseq.
Logseq’s isn’t that great of a “graph-database”, though, because it still lacks many of the features that graph databases (such as Neo4j or TypeDB) have:
- named relationships
- undirected edges,n-ary edges
- clear definition of concepts
- edges can have properties
- graph search, functions for graph traversal
- nested relations
- hierarchies
- search integrated with visualization
- inheritance of properties for subtypes
Adding any of these features doesn’t make Logseq a relational database, if anything, it would make it a better graph storage.
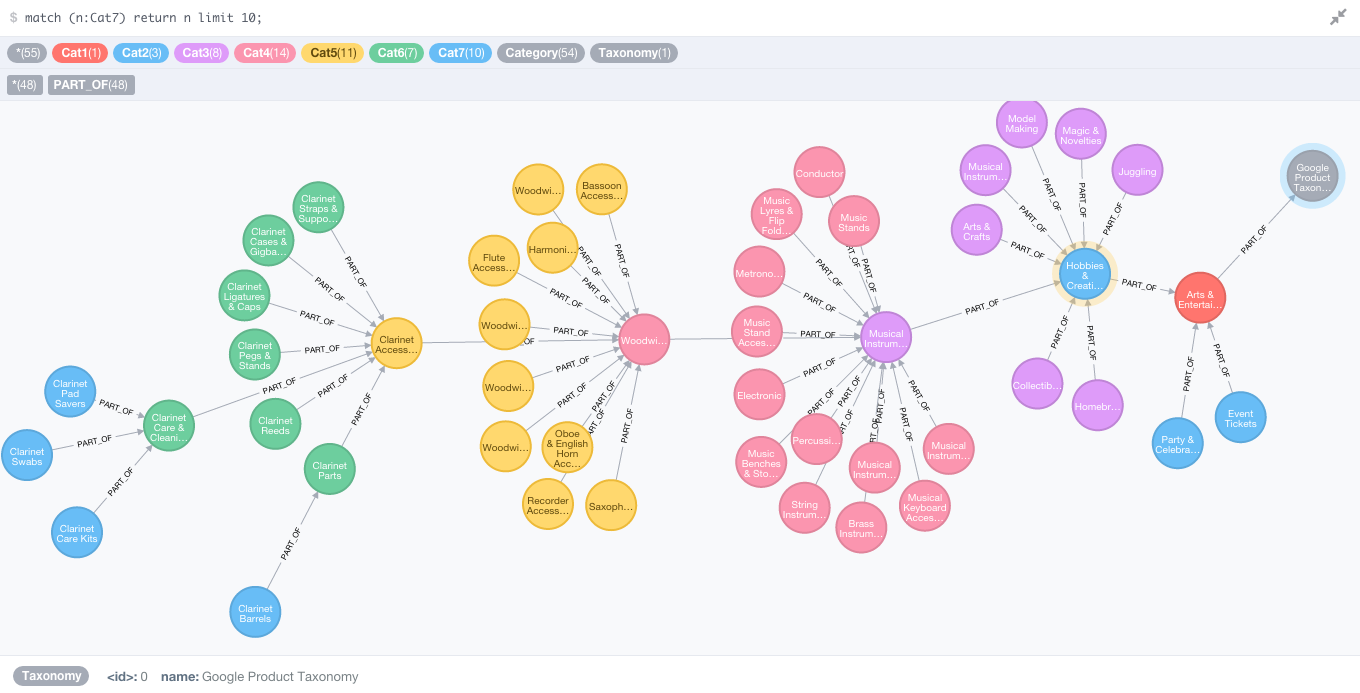
Here is an example that shows that hierarchies are no stranger to graph databases:
So it should be pretty clear by now that HIERARCHIES ARE GRAPHS right? I think so
…
Bruggen Blog: Hierarchies and the Google Product Taxonomy in Neo4j
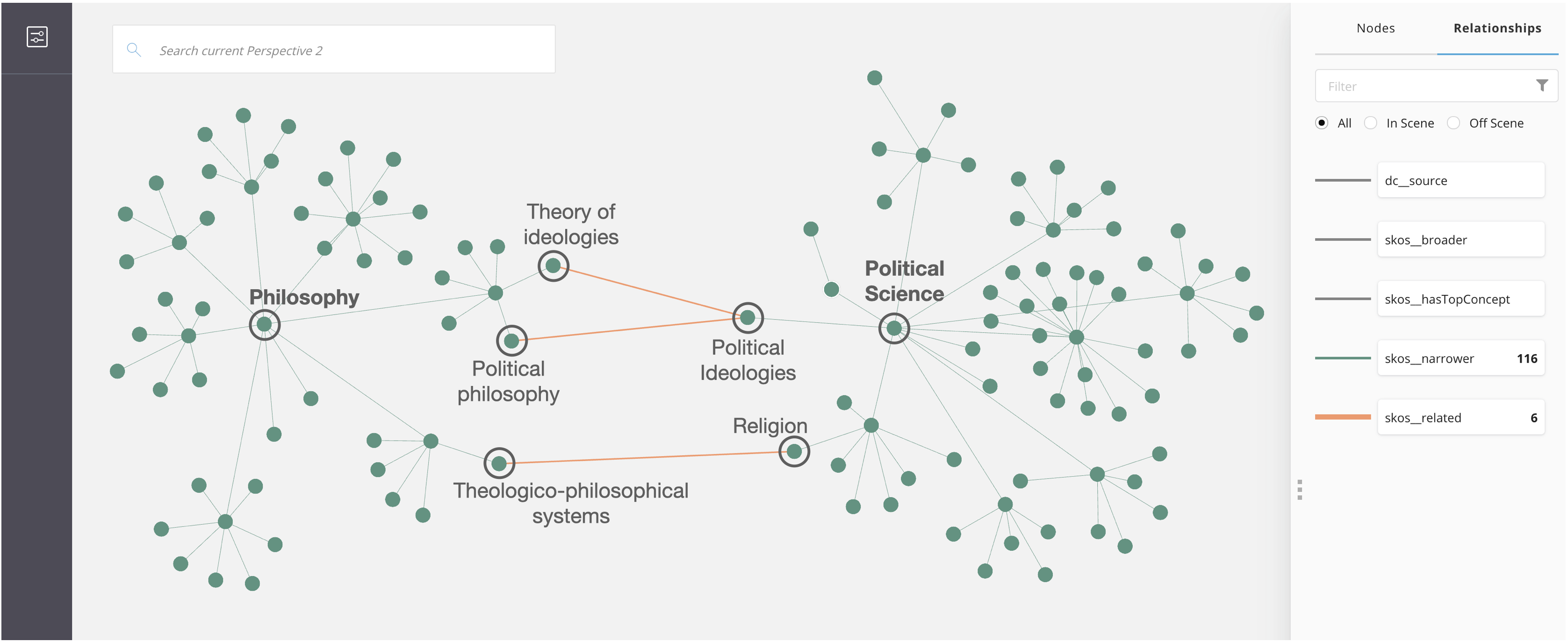
Another example for semantic search using SKOS, which would be an amazing and natural addition to Logseq:
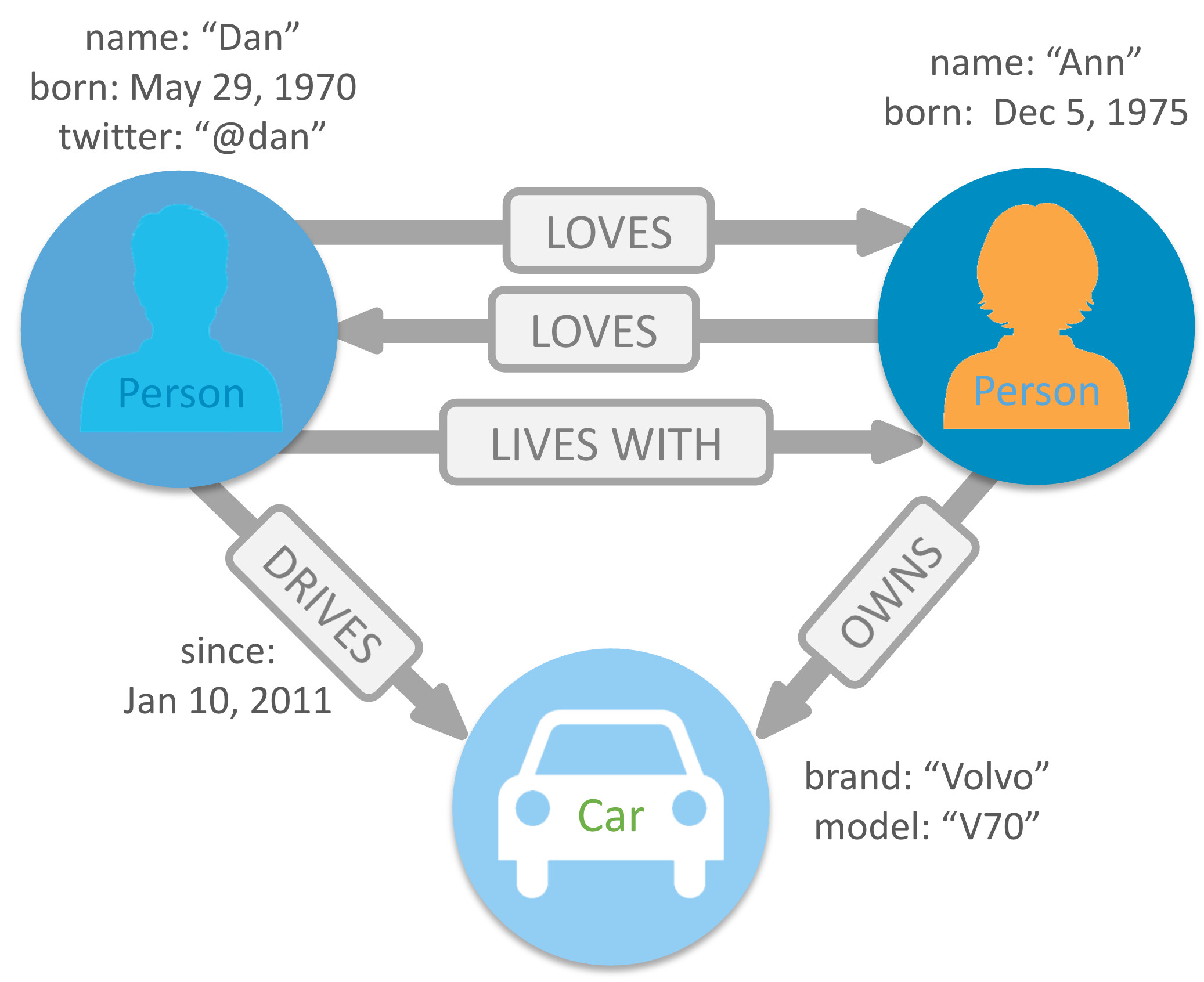
Here is a Neo4j example of with an edge, DRIVES, which itself has an attribute. Unfortunately these kinds of relationships can’t be represented cleanly in Logseq.
Now some of the features offered in graph DBs don’t make sense for Logseq, but it would be good to have a close look what could be useful.
The first things that come to mind are search functions for graph traversal to represent hierarchies, and the ability to give attributes to tags and properties, which would already let us express the DRIVES example above in a reasonable manner.