Continuing the discussion from Option to propagate updates of templates to existing copies:
Edges as nodes on another graph. That’s the link between graphs in the same meta-graph.
Does it sound suggestive to you?
Continuing the discussion from Option to propagate updates of templates to existing copies:
Edges as nodes on another graph. That’s the link between graphs in the same meta-graph.
Does it sound suggestive to you?
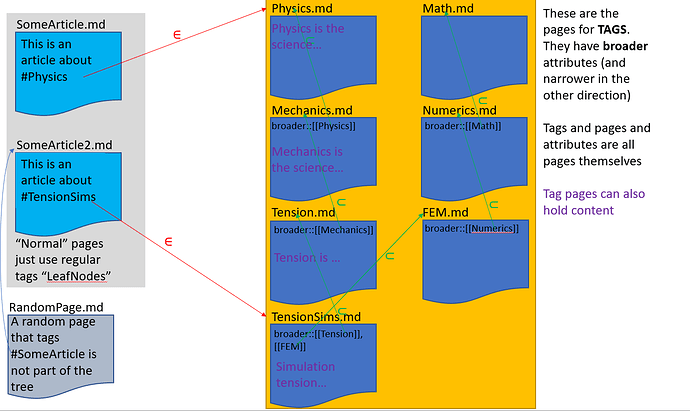
I am not suggesting to have a typed-Logseq, and I am not even suggesting that it would be a good idea (I don’t know if it is a bad idea either), but one design choice in Logseq is to have everything as pages. Pages are pages, tags are pages, and even attributes are pages.
Fundamentally, we have types for pages “p”, and recursively for every type a new type of
attr a:a → attribute_value
tag a:a → tag_name
This gives us attributes, of type attr p, tags, of type tag p, attributes of tags, tags of attributes etc. We don’t have relations.
All of these should probably live in different namespaces to keep them apart, e.g. we can have pages tagged “numerical” (for example ideas about numerics) and attributes tagged “numerical” (for example attributes that have numerical values).
Logseq doesn’t make that distinction, and all of them are represented as pages.
Should Logseq make this distinction? In principle, it could do so, by adding an additional attribute to each page, which says if it is a page, a tag of a page, a tag of a tag etc.
This is where your automatic inheritance would come in handy.
Would it be beneficial to do so? I don’t know. For me, the biggest issue is that Logseq’s model of namespaces is fundamentally broken (see Knowledge management for tags discussion), but higher order tags are not going to help, and “is a subclass of” can already be modeled by setting attributes on tags, the problem is the lack of a search to browse through the resulting graphs. A more formal approach would make things neater and give better autocomplete, but I don’t see any other advantages, at least for now.
Would it help to propagate template updates? Maybe it could reduce bugs, in that it could propagate template updates only to the right type of tags, but that seems to be a minor issue.
From a categorical point of view, there are also ologs.
I am not suggesting to have a typed-Logseq, and I am not even suggesting that it would be a good idea (I don’t know if it is a bad idea either),
Me too!
but one design choice in Logseq is to have everything as pages. Pages are pages, tags are pages, and even attributes are pages.
Just an observation here.
Today, in Logseq, everything is a block, not a page.
Although a block is displayed as a page with only one block, a block is a block. Or even as a page without any blocks, it will also be a block, a block representing an empty page.
Since the last refactoring of Logseq done in April 2021:
Therefore, as I understand it, the graph can only be made up of a bounded set of block types. Pages being one type of those, of course, but, then, despite the circumstantial “graph view” visualization, the real graph is another, since in that visualization the nodes are pages and all types of blocks should be represented , which are the ones that effectively form the graph. I’m not saying that the current visualization doesn’t have its advantages (or disadvantages), nor am I proposing that all blocks be displayed (there’s enough spaghetti already), but it would be worth bearing in mind.
I found an interesting paper that takes this to the extreme.
A Type-Theoretical Approach for Ontologies:
the Case of Roles.
Honestly, I have no idea if such theory contributes anything useful, my guess is not. The Olog
I find the different types in Def. 4 interesting. They also implement relations.
Overall, the Olog paper by Spivak seems to be much more useful. I remember reading a paper on CQL, a categorical query language for databases, they had some categorical constructions that go beyond relational databases, but I don’t remember the details.
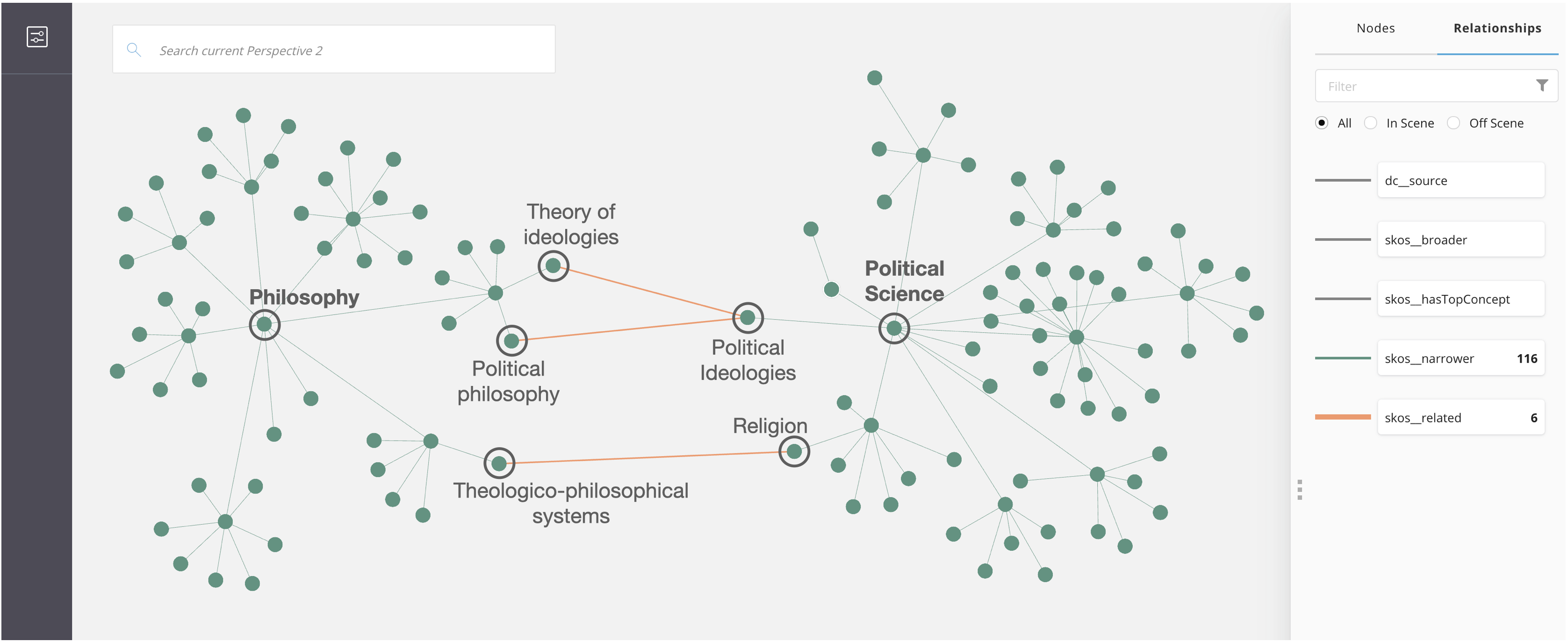
Wikipedia puts categories into their own namespace, so that is one fundamental difference to the Logseq model.
You are right about the blocks, of course!
Well, meanwhile (I have a lot of material to digest), perhaps it would be convenient to make a disquisition of what we already have implemented in Logseq. A more or less rigorous examination, considering each of its parts regarding this topic.
I hope you can help me to solve some doubts that I have and that this can also help others.
One issue that I think creates confusion is related to terminology. That’s why I think we could specify (or agree) what exactly we mean when we use certain words.
my thoughts exactly! I wish we had an information architect as part of the discussion (for real IA, not academic paperwriting). Many of these issues have been worked out a long long time ago, but there is a reluctance in the community to accept the solutions instead of reinventing an inferior solution.
It has occurred to me that, for the discussion of terminology, we could start by defining what we could call ‘local variables’, to understand each other here, without having to worry about whether or not that definition would be convenient at a ‘global’ level.
Yes, the concept is that, to build taxonomic structures from categories and properties. And then draw other maps with the relationships between those concepts and operate in that abstraction layer defining a data model.
However, as a starting point I would propose going deeper.
Personally, I mostly have questions, I am learning as I go. And the questions I ask myself, right now, have to do with Logseq’s architecture, whether or not it would be convenient to adopt a Three-schema approach [0] model, or to differentiate each external/conceptual/internal schema, also in the terminology.
[0]:Three-schema approach - Three-schema approach - Wikipedia
I didn’t want to talk about the taxonomy, I just wanted to use this sketch to illustrate the kinds of relationships that Logseq can encode and give names to the the concepts.
I wonder the same thing. I don’t know, because I’m still not clear about what parallels are convenient between the conceptual model and the physical model.
From what I see, we have here an apparent dilemma between two types of approach. One from the perspective of relational databases vs. the graph database approach. And it turns out that both approaches make sense if you think about each from the perspective of their results. However, it is a fact that the logseq database is a graph, so doing a relational approach would require a middle layer. Same happens at the file level, where possible solutions are tied to the file storage model.
Without going into assessing which model would be preferable at the user interface level, if such a dichotomy really existed in that layer, I think that perhaps it would be convenient to separate three types of schemas in the Logseq architecture:
If I’m not mistaken, this model is not implemented, so it would be part of a hypothetical next Logseq refactoring and this debate would be part of the discussion regarding its suitability and the possible feasibility of its development.
People have brought this argument up in the past, but I don’t agree.
A relational database has tables that store relations. Data is often stored in fairly small chunks and is typed. Logseq doesn’t store tabular data, and doesn’t even support textual tables well.
A good example of a relational approach is Zotero, which allows pdf annotations just like Logseq, but stores the annotations in its SQLite database instead of in a text file. If you look at a note in Zotero, it is split into hundreds of little relations. This is not even remotely similar to Logseq.
Logseq’s isn’t that great of a “graph-database”, though, because it still lacks many of the features that graph databases (such as Neo4j or TypeDB) have:
Adding any of these features doesn’t make Logseq a relational database, if anything, it would make it a better graph storage.
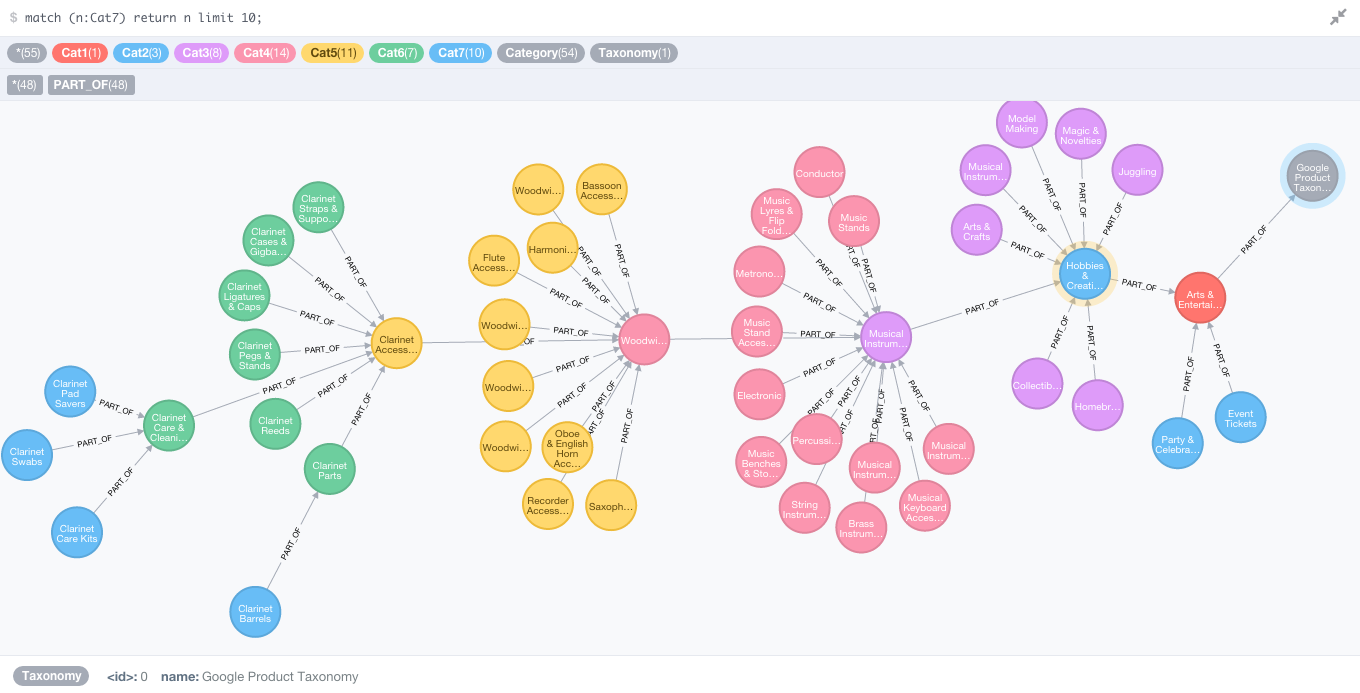
Here is an example that shows that hierarchies are no stranger to graph databases:
So it should be pretty clear by now that HIERARCHIES ARE GRAPHS right? I think so
…
Bruggen Blog: Hierarchies and the Google Product Taxonomy in Neo4j
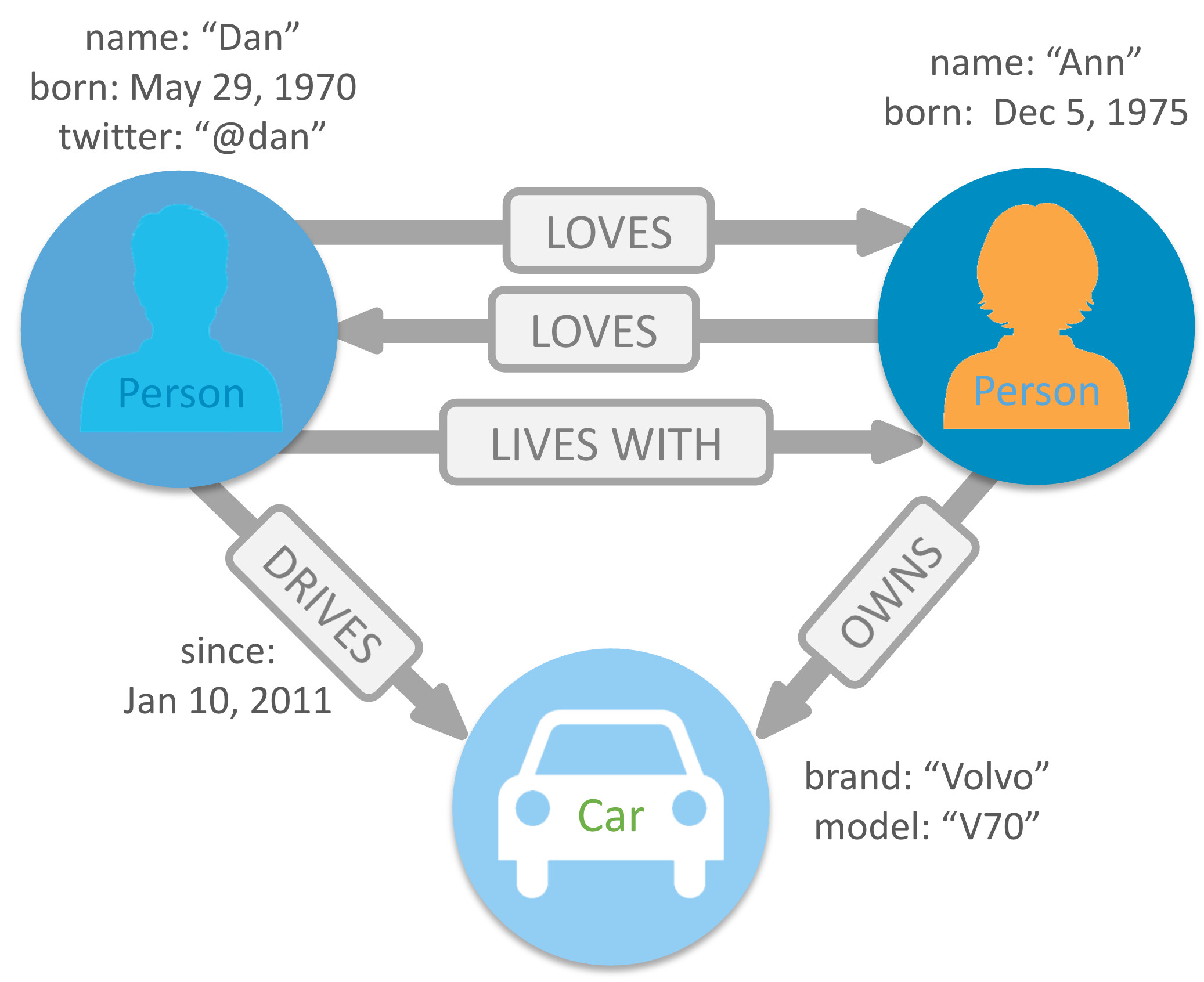
Here is a Neo4j example of with an edge, DRIVES, which itself has an attribute. Unfortunately these kinds of relationships can’t be represented cleanly in Logseq.
The first things that come to mind are search functions for graph traversal to represent hierarchies, and the ability to give attributes to tags and properties, which would already let us express the DRIVES example above in a reasonable manner.
My intention was not to enter into the debate about whether such a dichotomy really exists or about which approach is better at the UX level, although these are topics that interest me and for which I really appreciate your comments about it and I learn a lot from them.
Actually, I was still thinking about the question of defining a terminology. And I found the three-schema approach software engineering model convenient, if only to conceptually separate a term depending on the view we’re referring to.
For example, when we are talking about the graph, there does not have to be a direct correlation between the graph as a representation at the UI level and the graph as a database in the view of the internal schema that defines the physical storage structures (in our case, in the RAM memory, in the browser, not in our file system that is an other interface).
Another example would be the concept of page. In the application, a view in which to consult and enter information does not necessarily have to correspond to the concept of a page from the point of view of the database, or to a file in our storage.
Although a file appears to correspond to a page in the DB and is viewed from the application as a page; a page in the application does not necessarily have to correspond to a page as it is defined from the point of view of the database, nor to a concrete file in our file system.
Although the use of the extrapolation of concepts based on homological parallelisms can be a useful resource as a cognitive tool or metaphor.
Now some of the features offered in graph DBs don’t make sense for Logseq, but it would be good to have a close look what could be useful.
Of course! I have yet to take a closer look at the Datascript library 0 and at the Datomic Data Model 1
The first things that come to mind are search functions for graph traversal to represent hierarchies, and the ability to give attributes to tags and properties, which would already let us express the DRIVES example above in a reasonable manner.
That would be a great advance.
In fact, my original proposal in this thread deals precisely with representing relationships in a metagraph (a dedicated branch within the graph or a namespace, i.e. a hierarchy), where the correlation is that each type of relationship is a node of the metagraph in which to define the concept and in which to list the nodes of the graph (pages or blocks) that must be linked with said relationship.
And having a visualization in the application as if it were an independent graph, I suppose it would help to see it more clearly, separating the concept of page from relation.
Absolutely agree!
I am looking for features that you listed!
I realised that properties does not solve issue of naming/coloring relationships! It has to be inline like normal links. Also directions of relation and other things! It would make life so much easier to navigate vaults for users being intense knowledge worksers ![]()
Named relationships are there through properties:: and with them you can have a storage model for everything you have listed, it’s just that there is no UI for that.
For example “edge properties” and “nested relations”[¹]:
Page.md
key:: value 1
subkey:: value 2
key.md
nested-keys:: subkey
Then with Datalog queries you can perform whatever you want including graph traversing. Everything is already in place in my opinion, what’s missing is just UI/UX so that it isn’t a pain to maintain for the user.
[1]: why do you mix so many synonyms instead of sticking to {graph, vertex, edge} or {network, node, link}?
See my previous comment above and here there is my proposal for inline properties:
Basically just [[key:: value]].
For me [[key::val]] seems good !
Even better if on backend we could extract it into triples!
Page [[person/John]], has link [[verb/likes::noun/fruit/Apple]] .
and then we have tripe: “[[person/John]] ----([[verb/likes]])—> [[noun/fruit/Apple]]”
ideal for further conversion e.g. for RDF triples!