Logseq
A meta-graph as a set of linked graphs
Feedback
gax
November 15, 2022, 2:39am
9
@Didac
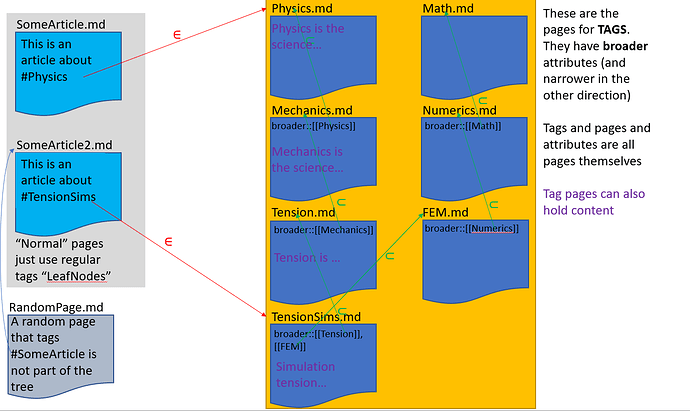
How about this diagram from the other
thread
as a starting point?
1 Like
show post in topic