Testing the DB version, I have noticed that “pages” and “classes” are different concepts, but seem to be the same entity. When you configure a #class, you will see it shows two sections of properties: as a page, and as class.
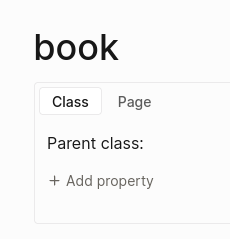
This perpetuates a problem that already exists in the current Logseq, when you want to use the same name for a concept and for a class (or type of entity). For example, I want to be able to:
- Use #book class for a block or a page that represents a specific book, as in: “Alice in Wonderland #book”
- Use [[book]] page for the general concept of books, as in: “I’m thinking of writing a [[book]]” or “The best gift I got today is a [[book]]”
The problem comes when I want to see all the references to the concept, but not all the entities classified as books. Or vice versa. It’s not possible: they all appear mixed in the “linked references” section and in the queries.
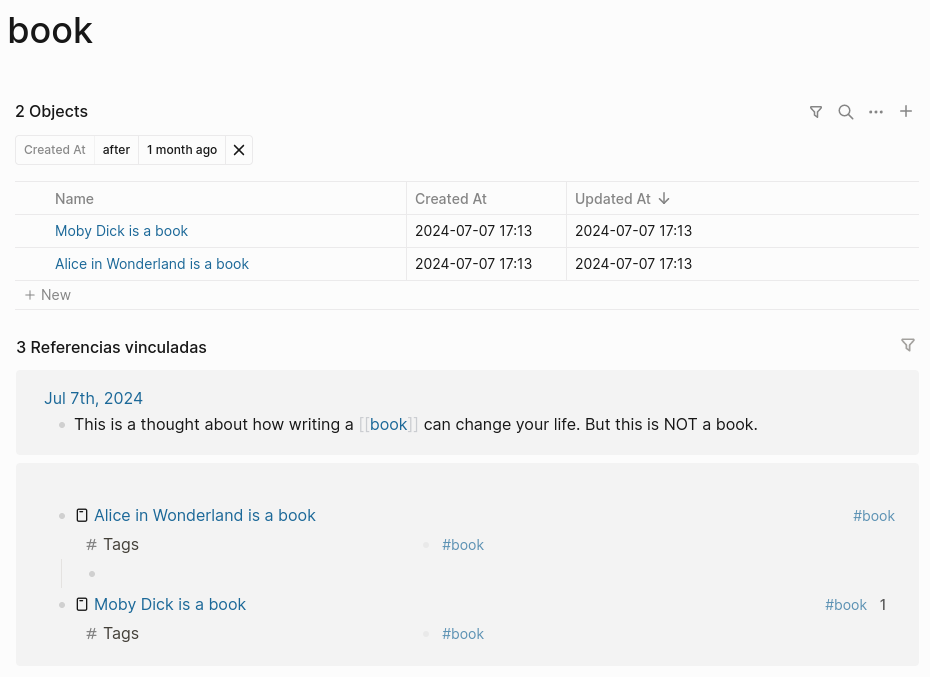
As I said, this is issue is already present in the current version of Logseq. As #this and [[this]] are the same, whenever I want to differentiate something as a class, I need to do things like #book (for the general concept) and #book-class (for the class or object type). Ugly stuff.
This is what comes to mind as possible solutions:
- Allow classes and pages to co-exist as totally different entities, so they can even have the same name without conflict.
- Just add a way to filter by “classes only” and “pages only” (and “both / no filter”) in the linked references section and in queries.
Have you found this limitation? Is there another way of solving it?