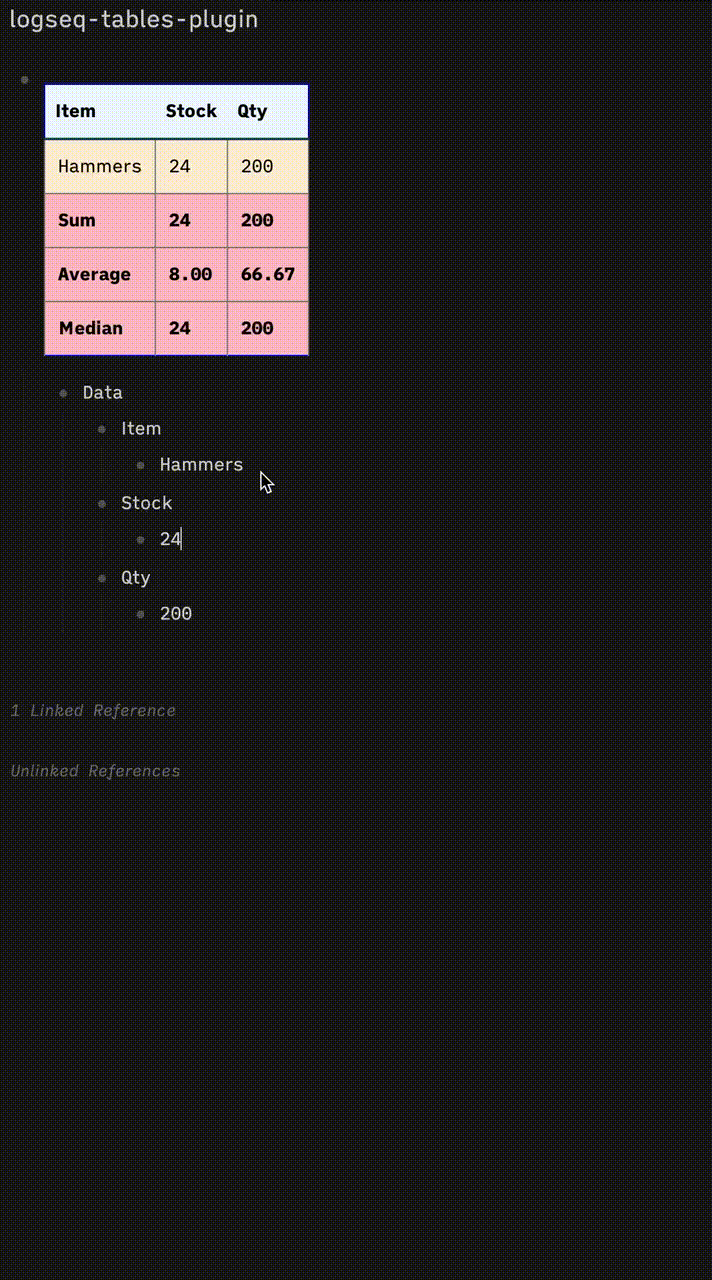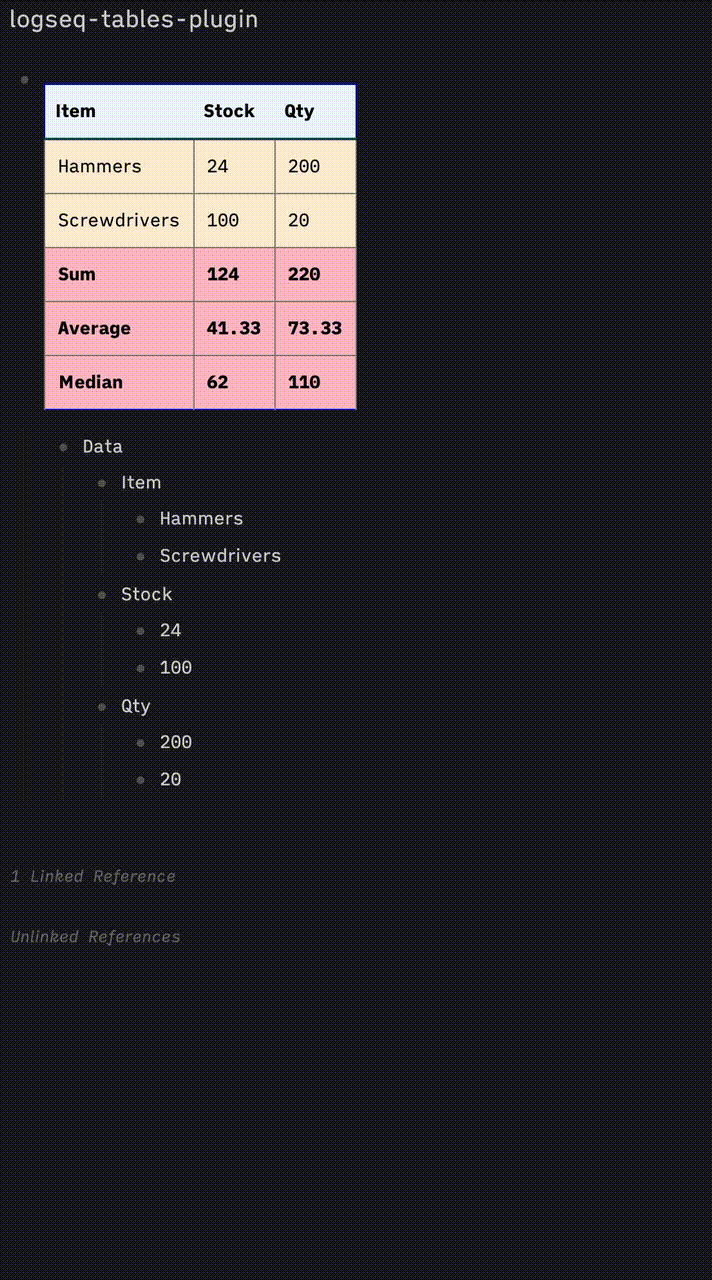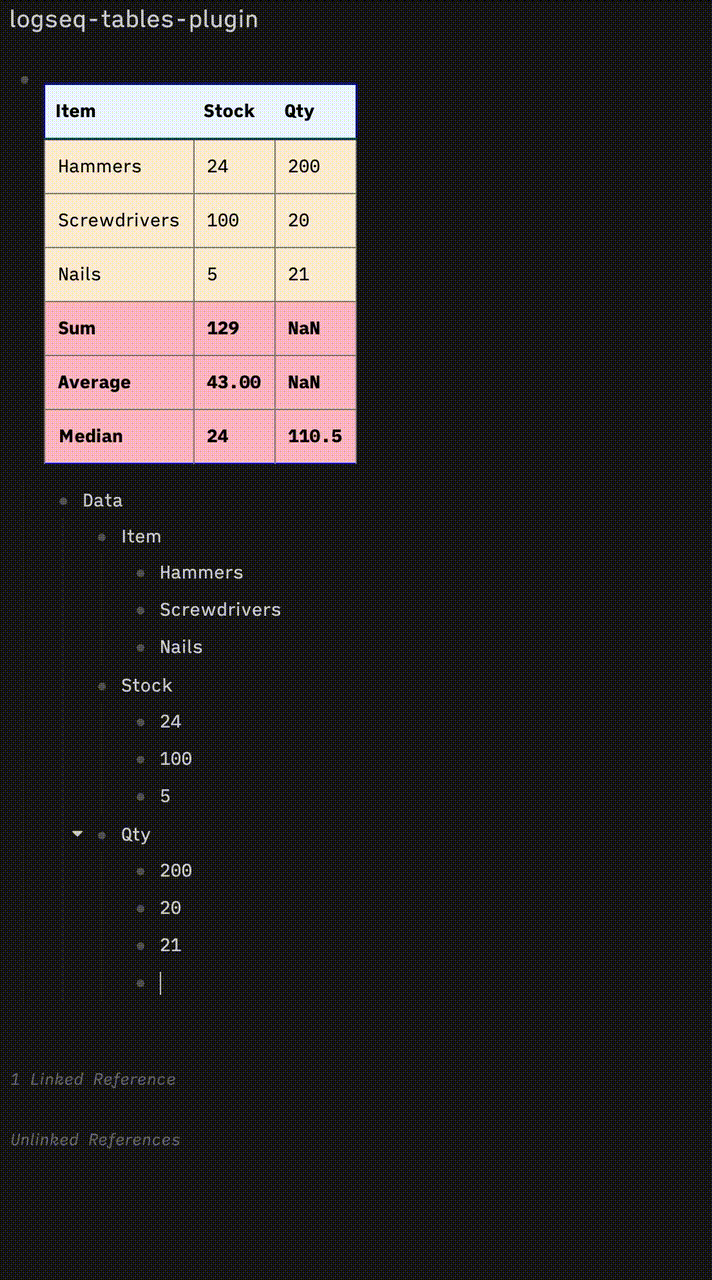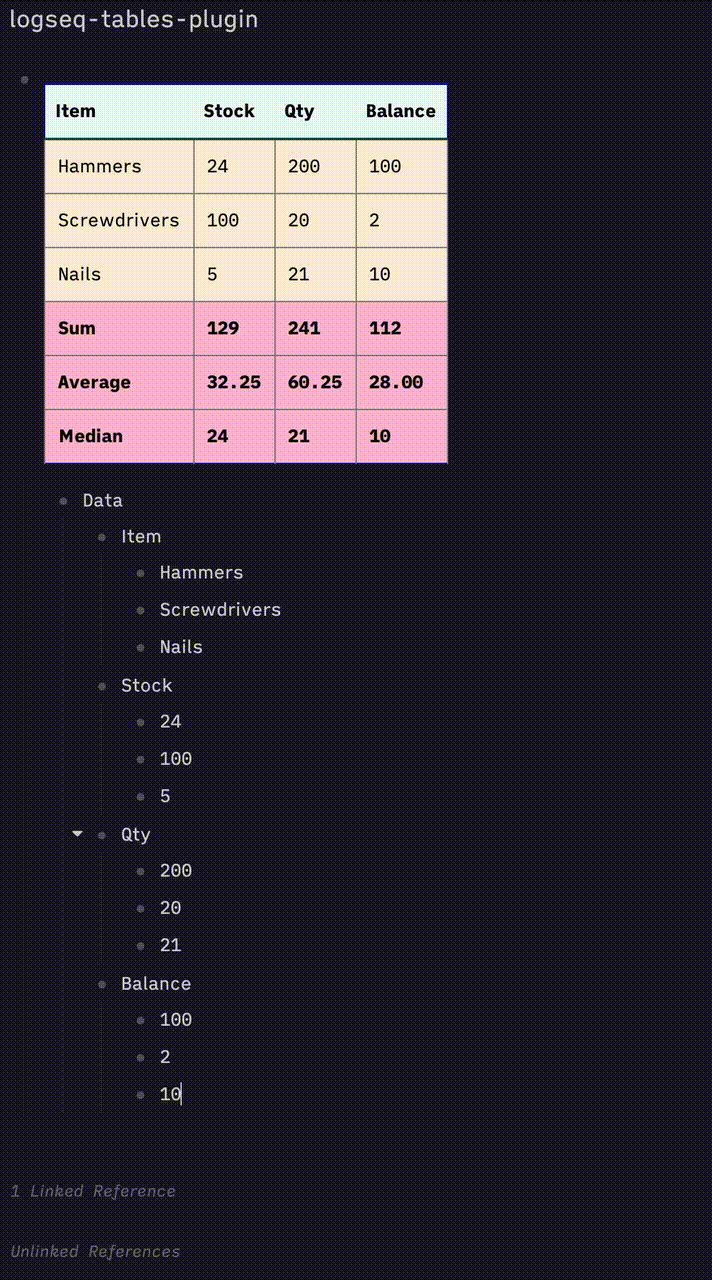
I’m also interested in this but with a completely different take.
Logseq uses a graph database and pretty much any and all data can be expressed as a graph.
For example, if I have a task and that task has sub tasks and belongs to a project with a given due date, all of these can be specified as relationships in a graph.
We might choose to represent this data in log seq in outline form by creating a project page and then adding the task as a child of that page and its subtasks as children of that task and the due date as as a property and status as a checkbox.
It is easy to take a csv with a row of tasks and a column for project and due date and relabel them as “parent” and “property” …
But do you really want to create your data in table form?
What if we could do the reverse and label blocks as task and then relabel the parent as “project” or perhaps label a block as a “project node and then infer that all “children” with a status are tasks.
Once we have relabeled these relationships to something meaningful then perhaps we could create alternative views from these relationships, eg table, kanban, or simply change the outline structure to group tasks by status or due date instead of project labelling project as a property rather than a parent and instead of being some read-only view might be able to change due date by moving the block from one parent to another or simply changing the value of the due date block — bulk edit made easy — and then perhaps change the view back to project view.
I love how notion allows tabular data to be visualized in many different ways, but I think logseq graph db has even more possibilities than notion.
Its already possible to add custom properties that could indicate a block type and then write queries to navigate relations to build new views of data, but Im not really sure yet how to make this configuration more user defined and dynamic if you want to change relationship structure to have it update config and/or data.
I also wonder if logseq might be too flexible where it is hard to enforce modeling constraints such as due date must be a date and what do you do with invalid data or extra or invalid data when you want to use a different representation where you don’t want that data displayed. Perhaps logseq could support some sort of hidden block attribute for plugins to use or maybe the plugin store extra data externally and link with block id.
Not sure all the details, but Im really curious to explore the multiple representations of a graph rather than just visualizing a table