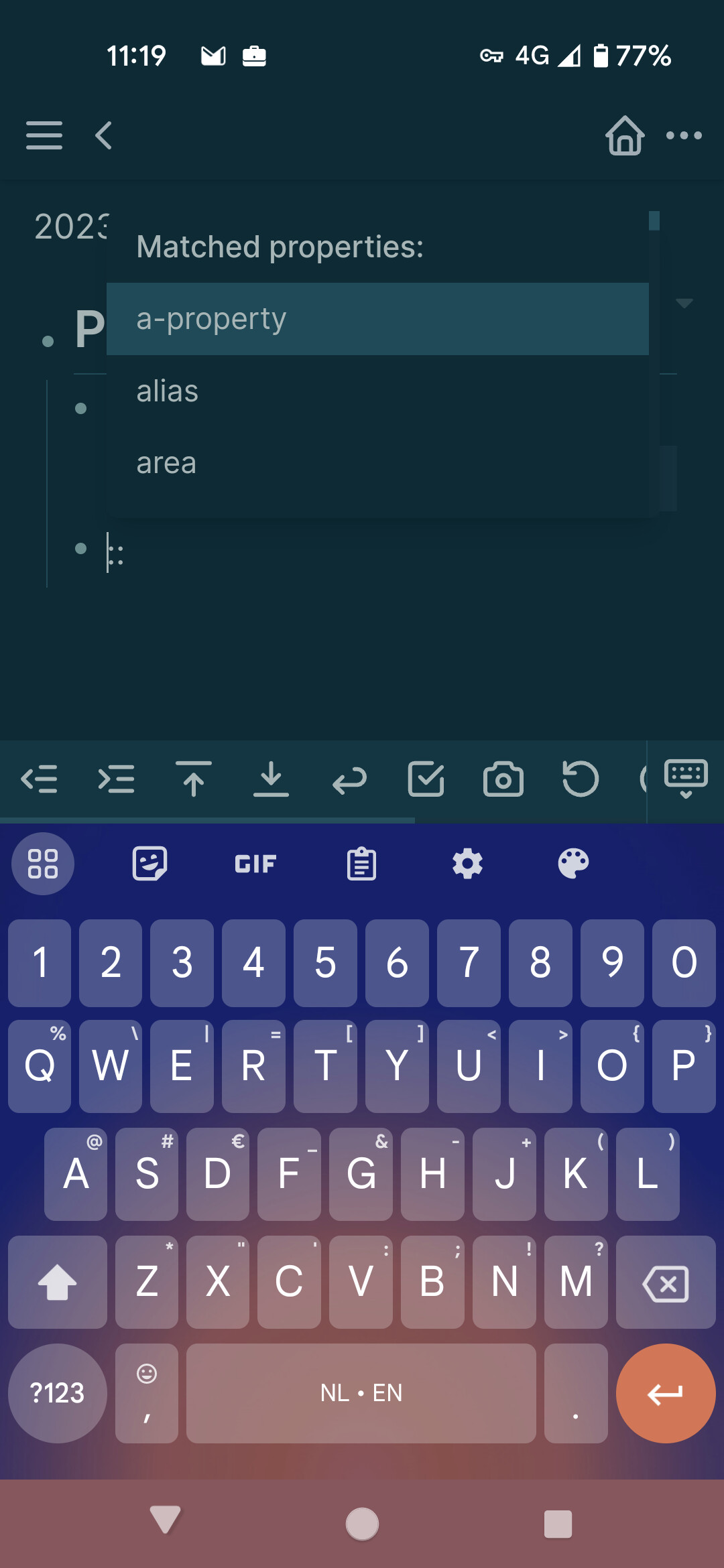
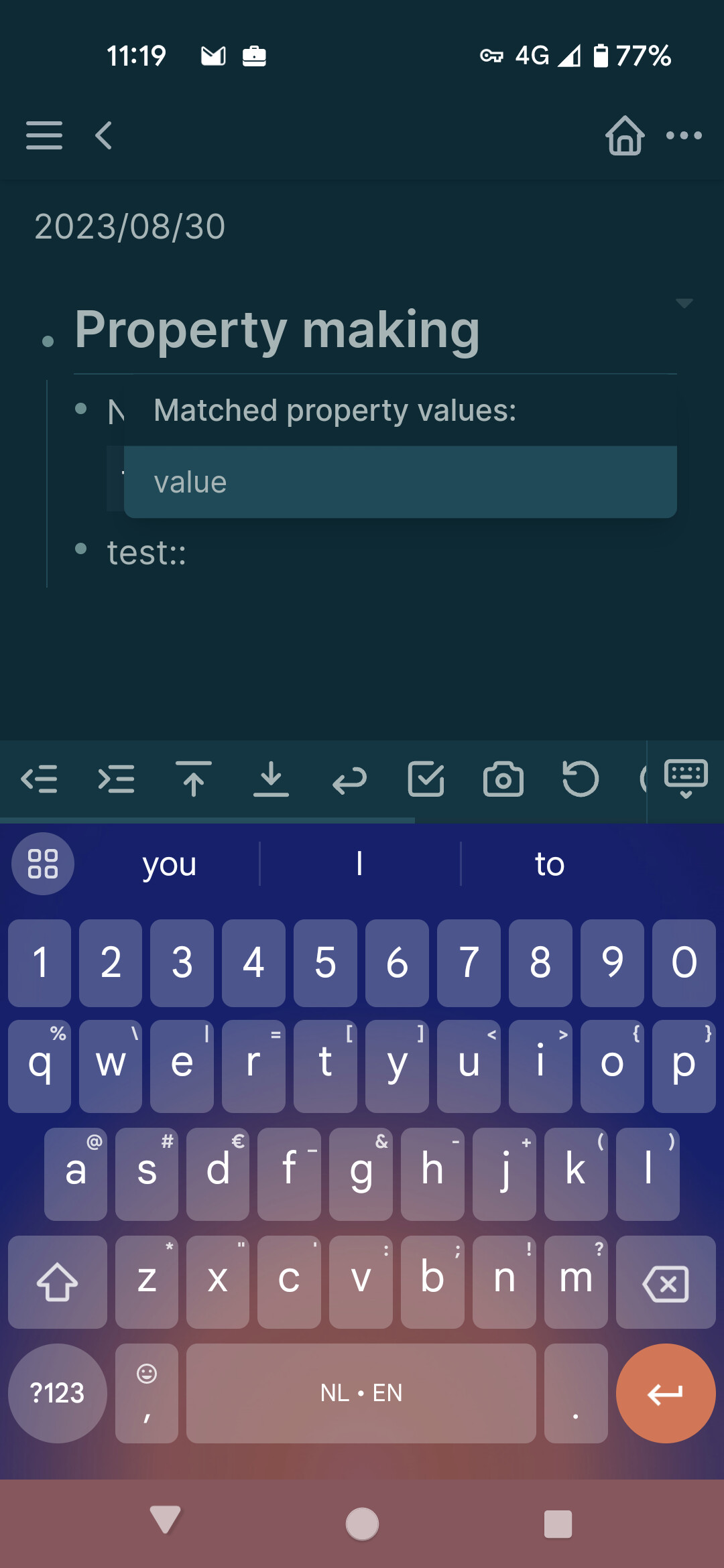
Sure. If we assume you make a note with:
test:: value
And we make a new note where we also want the test property.
We will type :: to get a list of properties in the graph. We can then select test and should then get a list of values associated with this property. (eg. value)