In case we get the ability to choose the value of a specific property from a dropdown menu, I have an idea to populate that with dynamic contextual options.
Let’s say the user adopt a property like status::. In the [[status]] page they could set a special property, let’s say options:: (or whatever the devs prefer):
status.md
options:: [[todo]] [[doing]] [[done]]
In the example above the user set those three options manually, that appear in the dropdown menu for each status:: property.
Now what if we have a property like author:: that should list a lot of options and the user doesn’t want to type each of them manually?
The syntax of Simple Queries could be used to specify those options:
author.md
options:: (property class [[person/author]])
That query syntax returns all pages & blocks that have as property class:: [[person/author]]. The idea is that those pages & blocks are listed as options in the dropdown menu of each author:: property.
If the user choose a page from the dropdown menu the value of the property becomes a [[page reference]], if it’s a block it becomes a ((block reference)).
@futurized I don’t know if this has been proposed before but I hope you and the rest of the team could take this in consideration.
It doesn’t sound like the inverse as you are dropping the idea of using the query syntax. It would be way more limiting than my idea, where the query can be anything that fits the user needs, including AND & OR operators to respectively exclude/include sets of values:
Inverse in respect of explicit “is (something)” instead of explicit “(something has) options”.
Dropping the query, but actually making it built-in, which is the inverse of what you said next:
Being a developer, I can assure that developers like:
queries
It is the simple users that are allergic to them and want/need the right query already available.
operators (AND, OR etc.)
queries have operators (see previous point)
It is the simple users that don’t properly understand them (even NOT) and wish for/need something simpler.
explicitly directing the machine
It is the simple users that expect/need the machine to guess their intentions.
So what are we after?
Do we want to please the simple users?
Actually the simplest of users would like neither options:: nor is::. If they use author:: someone inside e.g. a book, they want someone to appear in the dropdown of author:: anywhere else, without any further action (like in browser inputs). In other words, if the user ignores the dropdown and enters a new value, that value should automatically appear in the next similar dropdrown (even in a recent section). If they have used status todo/doing/done in the past, they want these values to appear in the dropdown to be reused, without explicitly defining them anywhere. This covers the vast majority of cases. EDIT : This is already implemented.
Do we want to please the advanced users?
For the remaining cases, a predefined custom query is of course handy, but we don’t forget that a dropdown is already a query, no matter if it is built on top of other queries. If we want the most dynamic and less limiting approach, should have the option to customize every single drop-down, with the system caching the custom queries per property to be reused. So these queries are not saved in the graph, but in the user’s configuration. And this is where they most probably belong to (unless if we reach the point that the configuration is implemented as a graph).
Do we want to please both?
In principle, should always begin with the majority cases for the simple users, then build the rest on top of them.
I don’t think it does, what if one tags blocks with #person like in Tana and wants those as options for the author:: property?
You are imposing a structure to the user i.e. using specific properties for pages/blocks that will be the dropdown menu options.
What if current users already have a structure that doesn’t use properties at all or not the specific propery is:: but something like class::? What if the user is using propery names in their native language? Would you really force a is:: property everywhere for them instead of just going with a options:: property only on pages of properties?
With your method, I already know that I would need to refactor my graph. With mine, not.
Also, with my method I can test the query syntax as a query to check that outputs the desired pages/blocks. Maybe I need to modify the query to exclude the templates page as I already do with my queries.
How would you exclude templates with your method? I mean blocks with the is:: something property meant to be a template.
Even if templates were excluded by a hardcoded rule, what if I want to exclude blocks from a certain page?
And what if I want to use as possible values all the pages of a namespace? With my method it’s easy, with yours I would need to edit every single page and remember to do so when I add a new page to the namespace.
My approach seems easy to integrate with existing structures, I think it requires less maintainance and is more powerful.
You are framing the situation differently to make an argument
I don’t know what makes a graph problematic to you, but for me it is more convenient to have a single options:: property in each property page than is:: properties everywhere.
The dropdown menu could still be useful if it lists the most used options first.
I understand that you solution sounds simpler to you, but it sounds to me more complex to maintain and to explain to new users.
I proposed that the options:: property accepts page references as possible values and I see myself more prone to type options:: [[todo]] [[doing]] [[done]] once instead of going to each of those pages and add a is:: property.
The idea of using queries builds on top of this simple approach, extending it in a way that sounds natural to me.
Instead presenting your approach to the user through the UI looks harder to me. I think one would need to read the documentation, a thing that I hate about Logseq and that concur to make Logseq more like a framework (for software developers) than an app.
I think thought that we both understand each-other’s suggestion, no need to repeat ourselves. Let others decide which is more convenient between queried options and cached property values. Let them also decide whether Logseq should be the dream application for a particular group of users, or a framework for just about everything and everyone.
As about documentation, it is a graph itself. Hating it doesn’t help, it needs fixing. It should both:
be updated regularly to provide all the needed info
advertise by itself what is possible with Logseq
I don’t intend to change the topic, I use it only as an example to point that graphs need thought. They should not be treated like a bin to throw notes in. An advanced bin still contains waste (some of them valuable, but still unattractive). One criterion is whether a third person (including my future self) can use my graph without needing medicines. If I am the only person, I do it wrongly. It still serves me, but not the way it could.
Logseq should encourage good practices. Hacking should not be the first option. Instead of running a custom query every time you open a dropdown, run it only once and mass-apply some property to its results. This adds value to the content. But this is again for another thread.
I hate that I need to constantly check the documentation like I’d do with a software development framework. Logseq is the only application where I had to read the documentation to use it. For me this is a failure from a UI/UX point of view.
In this case, Logseq would do something like providing a “add options” button in pages that are used as property key. The button would add a options:: property. And next to that there would be a button that triggers the query builder, that would fill the property with the right query syntax. A progressive discovery of functionalities in context, instead of studying the whole documentation and checking for updates to it later.
But it is what Logseq encourages for the purpose of freeing the user from structuring while taking notes. In the documentation it is even mentioned to write everything in the journal and let the structure emerge.
Those queries expose to the user the graph DB queries that Logseq performs anyway to do basically everything. Caching can be done in both cases if it is convenient (I don’t think it is); I don’t understand why you considered your approarch caching.
I’m not sure what you describe here, as I don’t get any values when I add an existing property. Could you write the steps that I should follow in an empty graph, so as to check for it?
Avoid structure while taking notes, not indefinitely. You may still choose to avoid structure, but not the consequences of its lack. Unless you never intend to turn your notes into knowledge.
Caching is useful when the query is fixed. Every time you customize a query, you reset its cache.
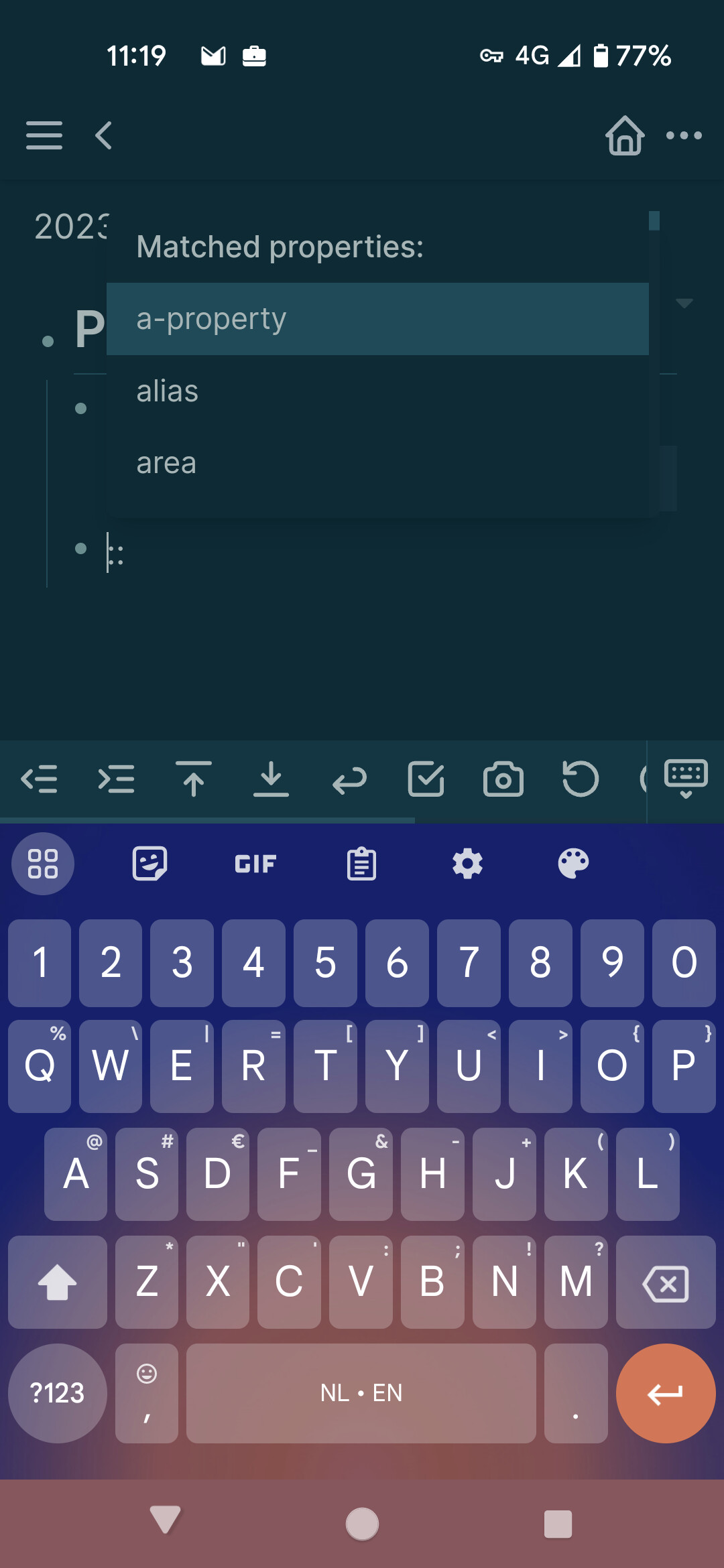
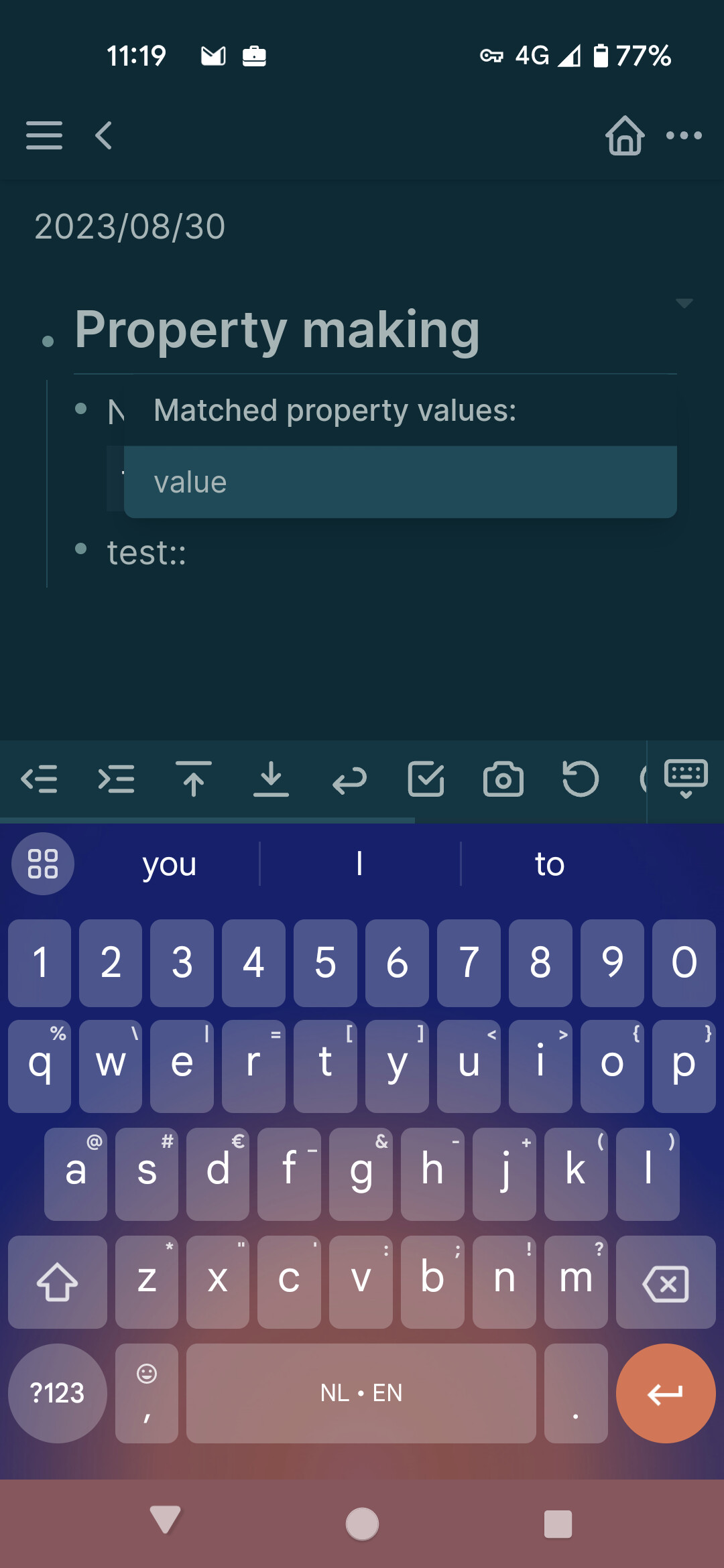
Sure. If we assume you make a note with: test:: value
And we make a new note where we also want the test property.
We will type :: to get a list of properties in the graph. We can then select test and should then get a list of values associated with this property. (eg. value)
That was the missing part. I never got this functionality, because I type the properties myself (much faster than choosing them). Thank you, I’m preparing a feature request.
I moved from class:: value properties for blocks to #value and it was a good decision for my use case. I woundn’t go back to is:: or whatever everywhere.
I still don’t see why you consider your approach cached. Both approaches imply querying the graph DB, something Logseq does tons of times continously.
You can still then type the property name afterward, but you start with :: first.
The only downside is that you then have to click on the name to open up the second dropdown.
Starting with :: is like telling Logseq we’re doing properties now.
Would be nice if typing test:: had the same effect.
@Siferiax you just provided an example of what I stated above: Logseq functionalities are too hidden and one gets to know them by reading documentation or other users’ suggestions
Your use case, you workflow, your choices. There are advantages and disadvantages.
I should have clarified that, sorry. I don’t talk about caching the DB’s data (this gets cached anyway). I talk about caching the user’s input (in the application). We change a query not when the data has changed, but when we want different results. However, we have already picked values in the past. How to merge those with the new results? What to keep and what to drop? There may be a smart way, but resetting is the standard approach.
Yes, if one wants to get out of Logseq the most of what it has to offer, there is a very steep learning curve.
I instantly loved Logseq, but that was because of the plain text files and outline structure. Those are the highest level for a user to see.
Learning all the intricate possibilities took a lot longer.
I remember complaining a lot about how difficult queries were and that I just didn’t get it. And I have a technical (SQL) background.
There’s so much possible, and at the same time I see questions that sound very reasonable and/or logical to want and that aren’t possible.
So I feel there is a lot of potential for Logseq to become better in so many ways.
I don’t think that anyone defends the quality of the documentation or how easy it is to find info about Logseq. After all, every participant (up to this point) in this thread have been active answering questions of other users. Mind that the specific info exists in the documentation and I have read it, but it never stuck to me. We all want for Logseq to be more intuitive, but intuition isn’t identical for everyone.
So the functionality for the simple users is already there and covers most of what I have written in this thread. Prefilling the dropdown of a new property would be nice (although not a big gain). What to prefill it with? I still have reasons to prefer a fixed configurable query over a totally custom one, but this is of secondary importance.