Below is just my personal humble opinion.
I’m an Obsidian user and I was introduced to Logseq just recently. Yesterday I found out about the database version and it was a disappointment for me.
I went to see a few videos about this DB version and my major fears were confirmed.
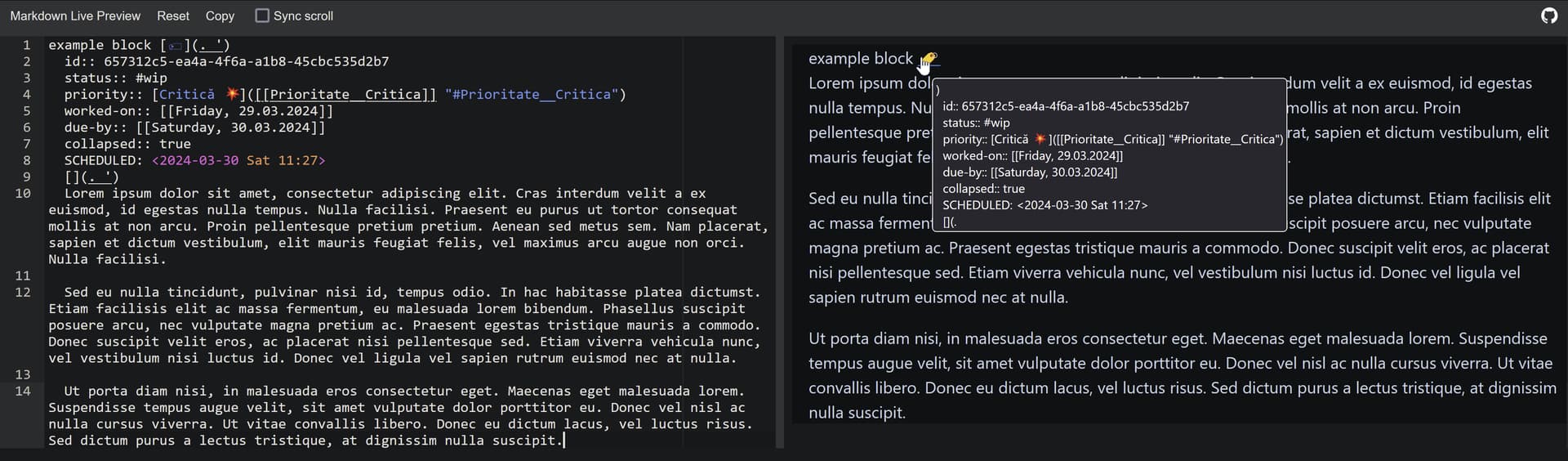
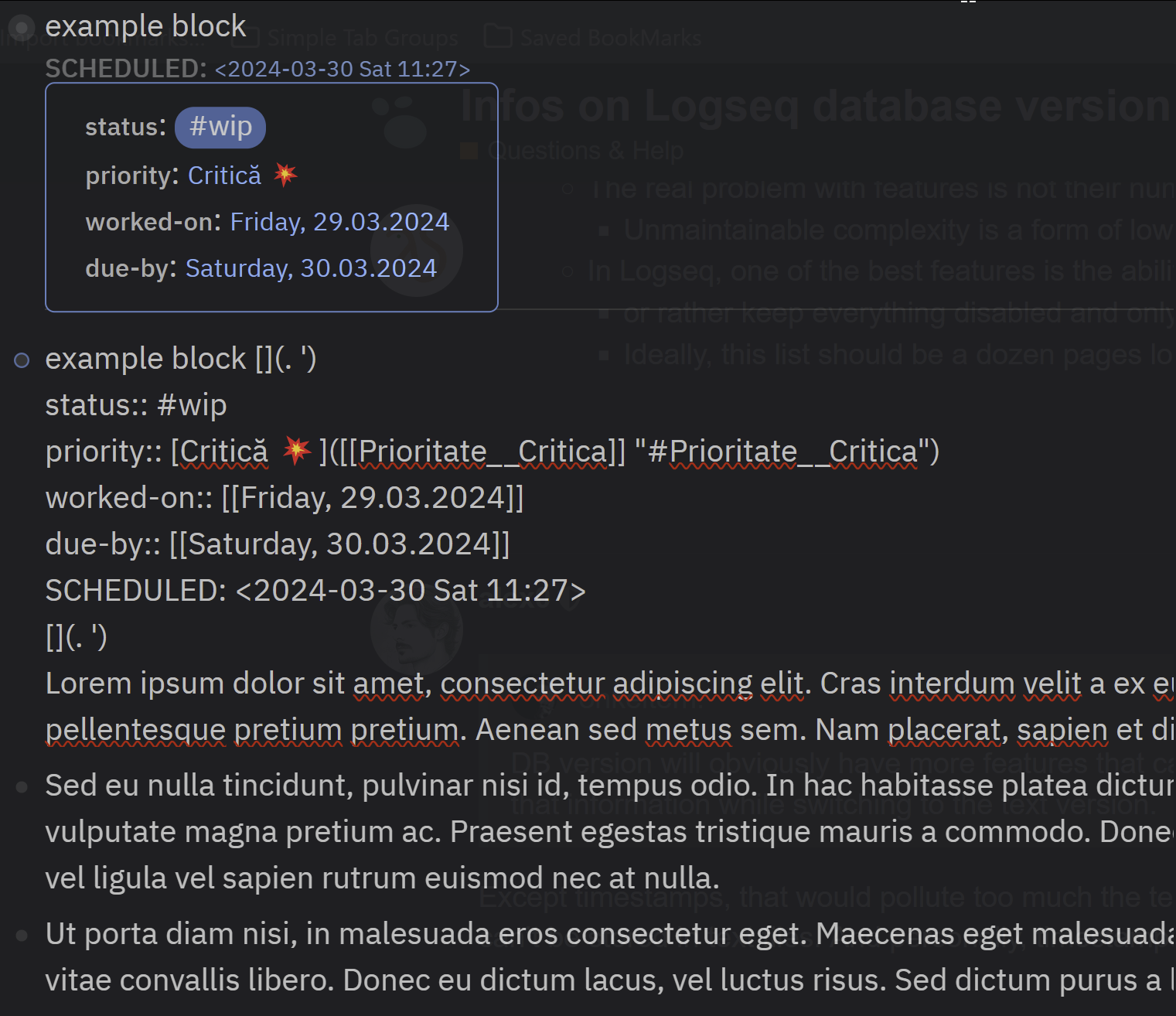
They started with adding meta information like fields, that can be attached to items. Which brings types and a whole set of problems that a regular person just cannot handle: types incompatibility, types conversion, old entities maintaining, data migrations.
What about references? Now you can reference just anything, but in the database version we can have a field of that type, like a reference to a page. Which looks sweet but… prevents us from changing our mind in the future. Will we able to change that too? How it’s gonna reflect on the rest of our data?
To address all problems that brings inventing fields, one needs to build a very complex system. The team can be spending years on this. And the more they add, the more users will request. There are no objectively limits when to stop. You will find yourself building not a PKM-system, but an application prototyping tool instead.
I remember CCK fields in Drupal. It’s one of the most flexible ui-driven user-defined fields building system I even seen. It took years and years of thousands of people to keep system shining. And yet, it was incredibly difficult for professional programmers to support and use it.
I realize it’s not necessary to go into all the complexities right away. But you will be asked to expose this in the API to allow for user plugins. So complexity will come from that side first. You’re opening pandora’s box. It’s happening with Obsidian now, where people just can’t stop making plugins (and it’s considered a good thing!), but users get constantly disoriented and get pushed away from building a solid PKM-database towards making ugly poorly maintainable app similarities.
In the end, one needs to ask themselves: what I want to build? An app prototyping tool or a good, stable and feature-rich PKM system?
–
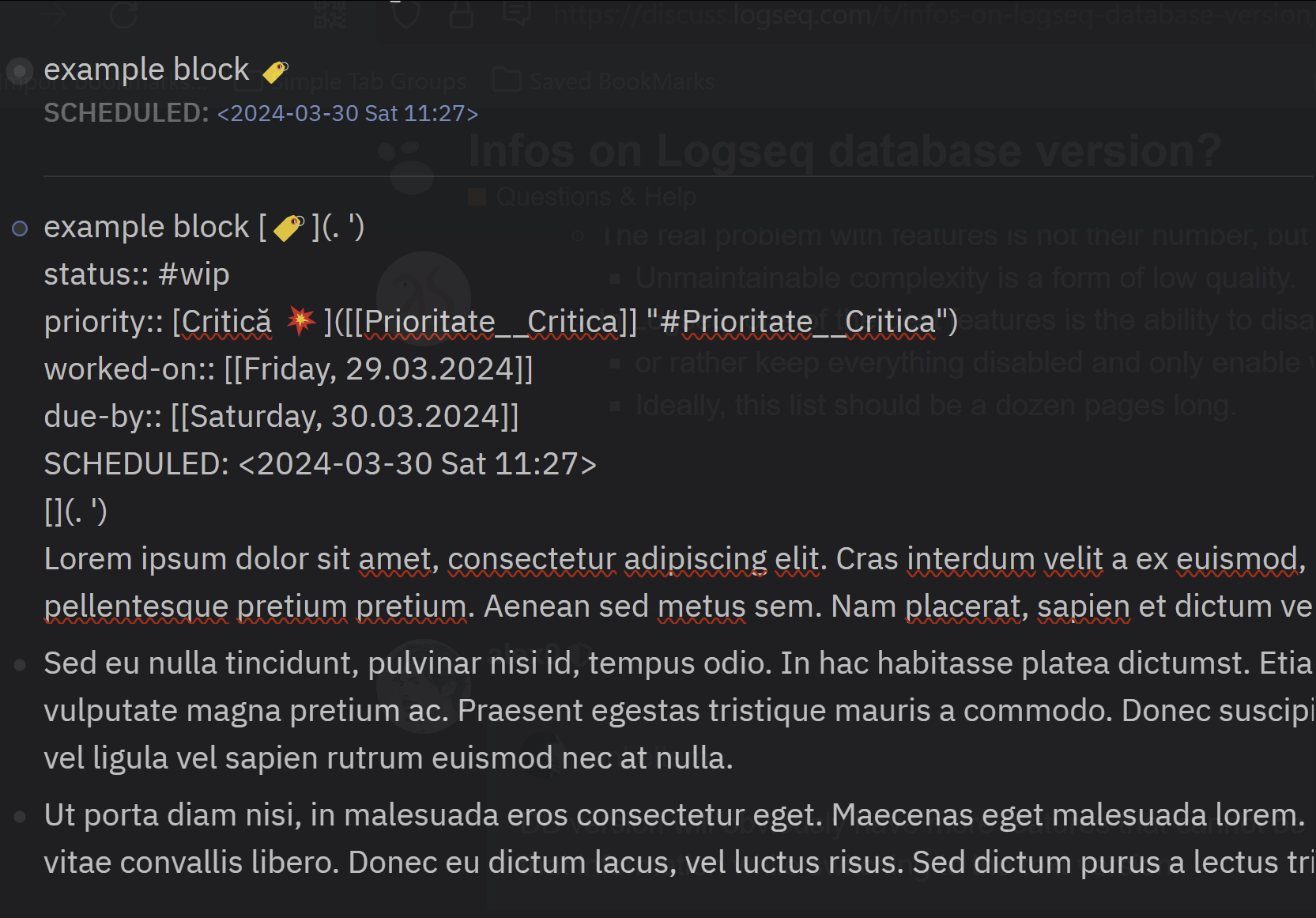
The genius of this tool I discovered so far, was that it’s able to create ad-hoc blocks: blocks are all anonymous until you start referencing them, and then they acquire UUIDs! Bravo! And it’s done in a nice way, which is compatible with Markdown. It brings great flexibility! You don’t need to worry about WHERE you created block. You don’t need a think out a storage for it.
I mean this is something unique right now. It makes Logseq differ from Notion. This is great!
With SQLite database you don’t need to be witty. You can do just anything and it will never be enough as you’re basically not limited. It’s just that your focus is straying away from the essence of PKM…
Also, a show stopper for me personally will be inability to keep my data in my git-repos and to use git for syncing.
So guys, call me outdated, but I hope DB version will never happen.