I truly appreciate that the team has developed such a useful local application and fully support the decision to restructure using a database. However, with the test of the db version, when I tried migrating a medium-sized Logseq graph with over 700 pages to the new Logseq, I’ve noticed that the database restructuring seems to go beyond just a change in storage, it also directly modifies the usage scenarios. I wanted to share the issues I encountered during the import and usage process.
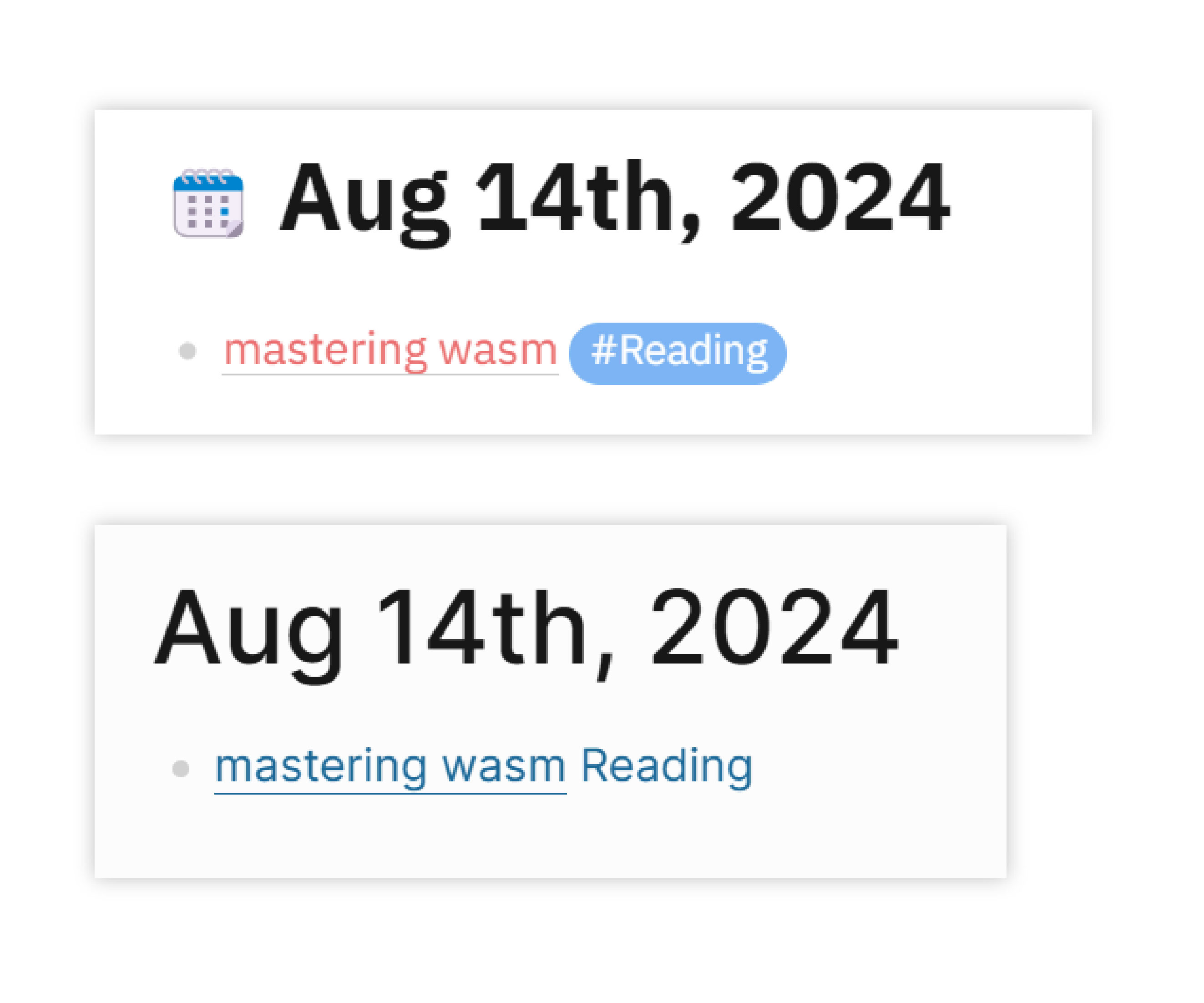
1. During Import, #tag is Automatically Changed to [[tag]]
While tags and pages were previously considered functionally similar, there are still practical differences in how they are used.
In some cases, a block might be related to a keyword without directly containing it. In such scenarios, I would add a tag at the end of the text. Since tags are rendered differently from links, I didn’t consider tags as part of the natural language. However, after #tag was changed to [[tag]], the tag, which was previously more like a block property, now integrates into the natural language text, making it looks weird.
Logseq does offer an option to fill in keywords for tag pages, which is helpful. However, this brings up another concern… I have dozens of tag keywords, each linked to a page with its own content. It’s not clear how I would get all these keywords these keywords efficiently.
Another point related to tags is their backlinks. In the earlier version of Logseq, the backlinks for tags and pages were functionally identical, with only a visual distinction. Now, when a tag and a page share the same name, it will be treated as a tag page. Tag pages default to showing a list of blocks rather than a description of the tag itself. This change requires users to rethink how they organize content related to tags—tags are now primarily treated as properties. For instance, I used to have a [[algorithm]] page, which I also frequently used as a tag. With this change, I now have to scroll through a long list of blocks before reaching the description of #algorithm. On the other hand, if algorithm remains a page, I run into the issue mentioned at the start of this section.
In summary, the current methods for importing tags and displaying pages don’t fully align with how tags were previously used and organized. In the earlier Logseq version, creating a db-style tag page was simply a matter of writing a query, which allowed users to manage the associated block list as needed.
Possible solution: while parsing tags in block, set them as tags. Then in tag page, put the tag block table after “Note”, and make the tag block list able to be folded.
2. Deprecated Namespace
In my view, the namespace feature is quite important, as it effectively addresses a common challenge in wiki-style note-taking—disambiguation.
For example, different programming languages may share common concepts, such as classes and interfaces, but the way these concepts are treated can vary significantly between languages. Having separate pages for [[golang/class]] and [[javascript/class]] makes sense, as they can be automatically linked to the relevant programming languages. The namespace functionality helps to manage this distinction effectively.
In the db version, Logseq deprecates the namespace feature and suggests using tags instead. However, tags cannot fully replace the functionality of namespaces, especially when considering the specific examples mentioned in Problem 3. In short, using tags instead of namespaces would require a significant amount of manual restructuring for the imported DB graph, and it still wouldn’t achieve the same presentation as a File graph. I started using Logseq three and a half years ago when namespaces weren’t available. At that time, I used tags to organize pages, creating [[golang class]] and [[javascript class]] and tagging them accordingly. Later, when the namespace feature was introduced, I fully transitioned to using namespaces.
In the new db version, I could revert to creating [[golang class]] and [[javascript class]] pages and manually tagging them as I did three years ago. However, with hundreds of pages utilizing namespaces, migrating to the db version now would require a significant amount of work and be very challenging.
3. Pages Tagged with “Keyword” Are Now Removed
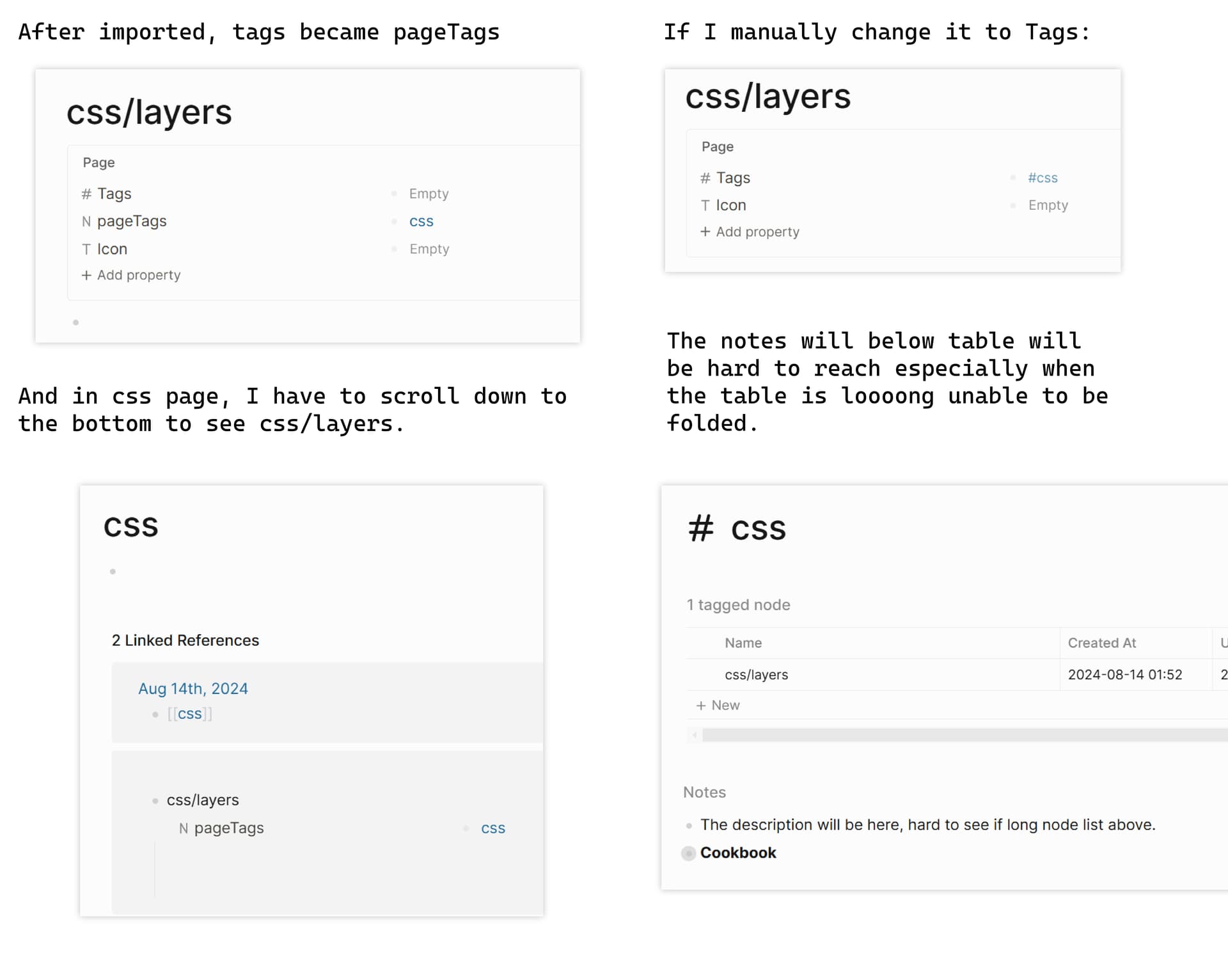
I noticed that in the current version, the tags in the original page properties are imported as pageTags, but the corresponding pages no longer have the page tagged with “keyword” feature. I have many related pages that were organized in this way, for example:
# Store your data in browser
- tags:: browser, localstorage, cache, indexedDB
Why use so many page-tags when bi-directional links are available? Because the priority of this page is very high, I want it to appear at the top of the backlinks for the browser, localstorage, and cache pages. However, this feature has been removed. In the db version, the imported format looks like this:
# Store your data in browser
- pageTags:: browser, localstorage, cache, indexedDB
In the db version, the browser and localstorage pages do not prioritize showing the page tagged with “keyword.” Although this can be achieved through queries, it would require me to modify hundreds of pages. I’m wondering if it’s possible to configure Logseq to automatically execute a query before each backlink, or more generally, to allow each page to insert a specific query block at a designated section?
As mentioned in point 2, Logseq recommends using tags in the db version. However, the tagged pages are not the same as page [[keyword]], but rather tag #keyword. Beyond the massive workload required to restructure the page logic, the new tags cannot replace namespaces, nor can they fully replace the tags in existing page properties.
In conclusion, the changes to tags and namespaces have led to shifts in usage scenarios. As a long-time Logseq user, I find it challenging to migrate my current file system-based graph to the new db version.