(v0.3.3, Desktop, Windows)
Hi,
I already postet some bug reports regarding namespace pages.
For this one I wanted to give you a specific bug report because it seems that Logseq is storing wrong informations from which you can’t even recover with a re-index and clearing the cache.
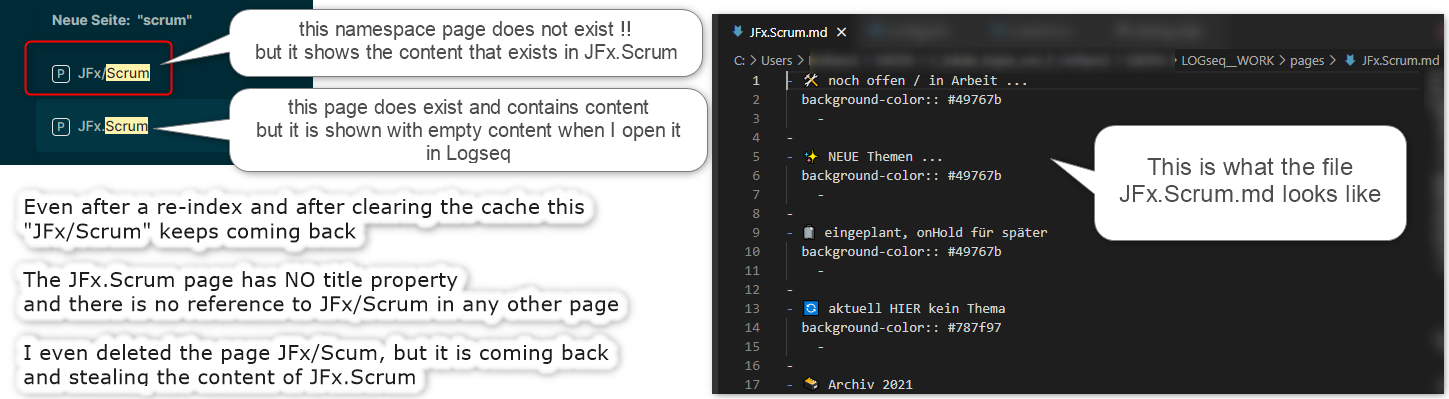
When I started to give namespace pages a try I created pages like JFx/Scrum but soon notices that I get into big troubles because I alread had pages like JFx.Scrum.
So I wanted to return to the state where I am NOT using namespace pages until those problems got solved. (Don’t try this - you are losing content!!)
The problem now is that:
- I delete the JFx/Scrum namespace page
- I clear the cache
- I do a re-index
- I close Logseq
- now I recreate the page JFx.Scrum.md (simple markdown, nothing special, not title/alias property)
- now I restart Logseq and …
…
- on the file system I only have the file JFx.Scum.md with the content
- in Logseq I see two pages “JFx.Scrum” (which is emtpy) and “JFx/Scrum” (which contains the content of JFx.Scrum.md)
I don’t know how I can recover from this state - Logseq must store the namespace page information somewhere - but I can’t get rid of this information.
Here is a screenshot too…
 and don’t know how many there are.
and don’t know how many there are.