- Logseq is great for organizing thoughts
- I discovered Logseq in mid-2022 and explored in some depth Notion, Capacities, Anytype, Affine, Gitbook, and a few others, and I’m back to Logseq. For a long time, I think.
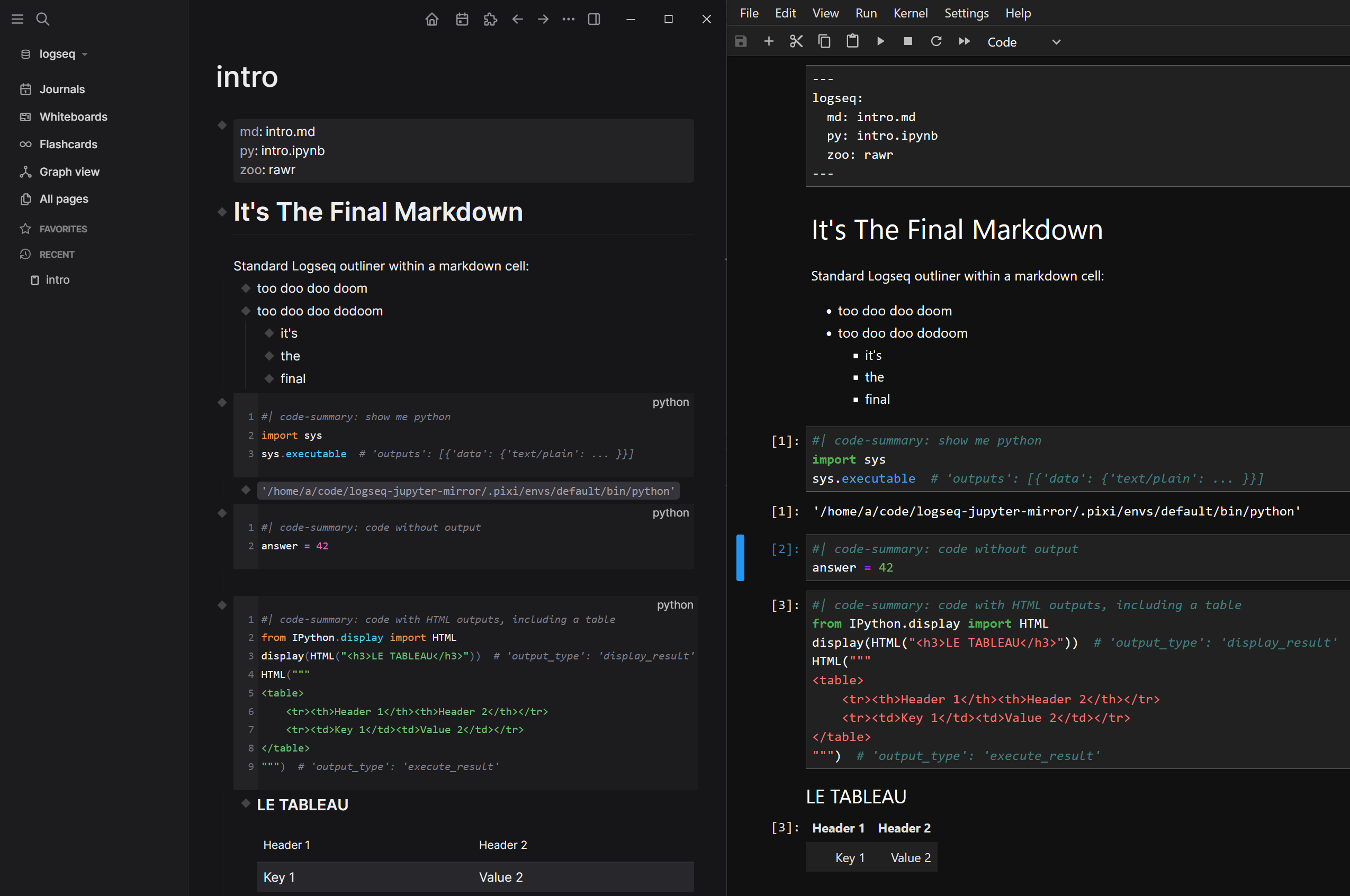
- Previously, Logseq users have built in JS and python execution (via pyodide)
- Logseq is useful for writing code, but execution options are limited (it’s not and shouldn’t be a Swiss army knife)
- Jupyter is great for running code (primarily python)
- Searching for information inside Jupyter notebooks is awkward, and retrieving text or code is worse, due to JSON structure and having to open the notebook in Jupyter
- Various issues with source control are partially addressed by converting to plain text documents, esp. markdown
- Authoring UI and UX is not as rich as in dedicated markdown editors
- Logseq combined with Jupyter is going to be great for organizing thoughts and code
I’ve been tinkering with the idea of a two-way mirror that would cast Jupyter .ipynb into Logseq .md, and vice versa. Any other markdown flavor can be supported as well. Some features I’m targeting:
- Batch conversions
 IPYNB → MD
IPYNB → MD- MD → IPYNB
- Real-time, birectional updates, should be easy enough with python’s
watchdog. I’m not well-versed in JS but probably there are options. - Support for Logseq properties block
- In addition to markdown and code inputs, it would be useful to capture certain outputs
- plain text and numbers
- HTML tables (from SQL queries via Pandas/Polars)
- images (e.g. from matplotlib/seaborn) - would be nice but not a priority for me
- Support for non-local (cloud) files and Jupyter instances (long-term vision)
- Early (static) prototype is shown here
- Development hurdles: how can one enable auto-refresh on the Logseq side? Currently, external edits to Logseq files require manual refresh, and active page is reset to today’s journal.
- How would you use it?
- If you want it, would you like to collaborate?
previous threads on the subject of jupyter+logseq: Search results for 'jupyter' - Logseq