running snippets from a code box would be already useful I think
btw you can embed any of examples from PyScript demo in an iframe to test Piodide and PyScript
running snippets from a code box would be already useful I think
btw you can embed any of examples from PyScript demo in an iframe to test Piodide and PyScript
Relevant: feat: WIP native cli command support by tiensonqin · Pull Request #7465 · logseq/logseq · GitHub
There is work in progress to let plugins (and eventually user directly) exec native commands that are in a whitelist specified in config.edn.
In the attached videos you can see a code block whose content is passed to a native command.
Maybe we will be able to add a command like python in config.edn whitelist and run snippets written in code blocks, hopefully displaying the output in a block too.
The first step is done with Pyodide in Edit and run python code inside Logseq itself
Any progress with R anyone know? Would love to be able to use quarto in LogSeq.
Quarto may need more effort, but R has landed: Edit and run R code inside Logseq itself
The next step is done with Jupyter-like evaluation:
Thanks for the guidance. I’ve implemented your custom.js, custom.css and macro buttons to good effect and now have a number of custom calculators in my graphs without the need for plugins so they work on Desktop and Android.
I effectively now have Jupyter style functionailty built in including carryover of variable values from code block to code block.
Great work.
It should be possible.
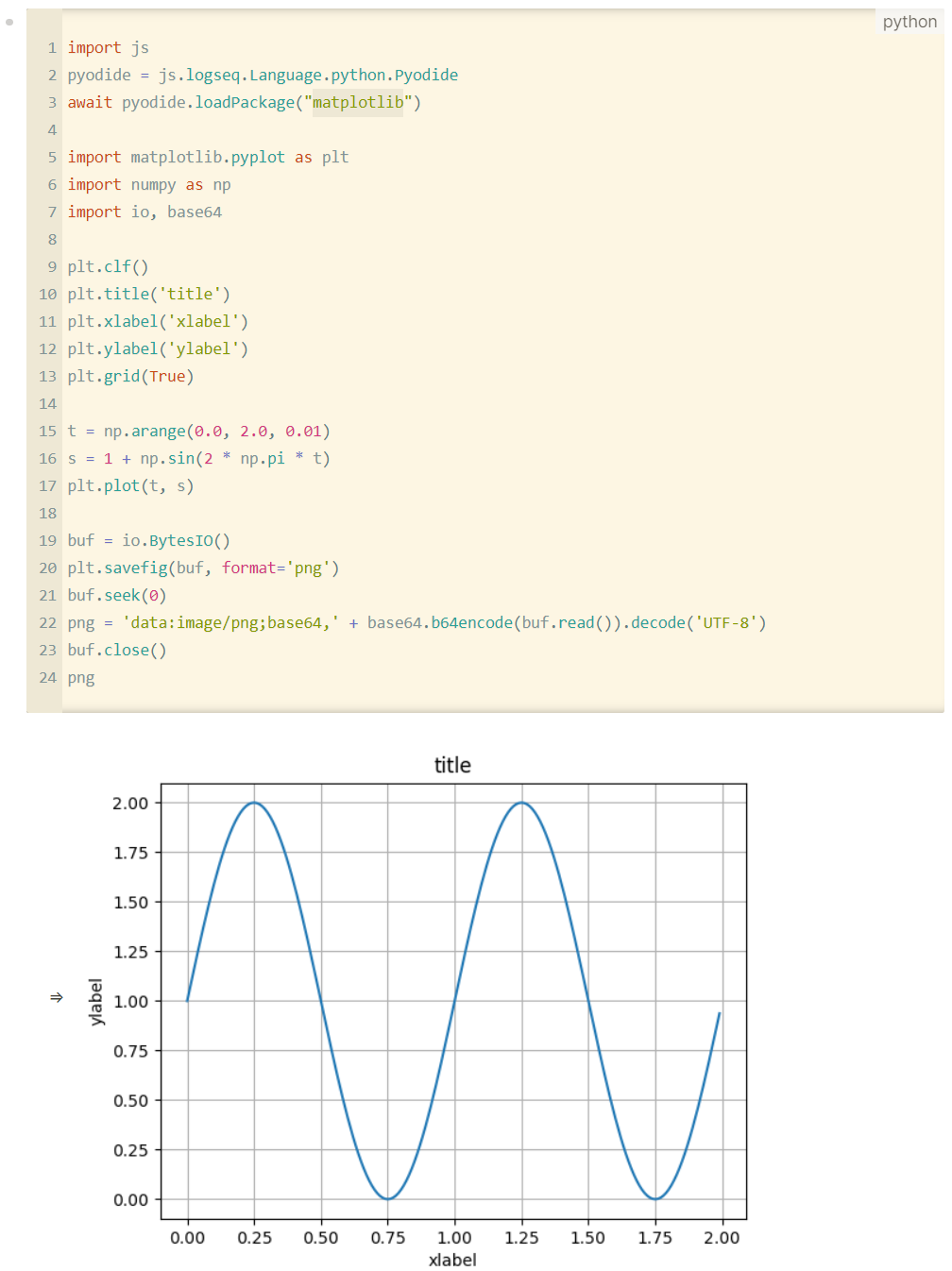
I wanted to test this out so I asked ChatGPT to extract the python code from the picture. Here it is
import js
pyodide = js.logseq.Language.python.Pyodide
await pyodide.loadPackage("matplotlib")
import matplotlib.pyplot as plt
import numpy as np
import io, base64
plt.clf()
plt.title('title')
plt.xlabel('xlabel')
plt.ylabel('ylabel')
plt.grid(True)
t = np.arange(0.0, 2.0, 0.01)
s = 1 + np.sin(2 * np.pi * t)
plt.plot(t, s)
buf = io.BytesIO()
plt.savefig(buf, format='png')
buf.seek(0)
png = 'data:image/png;base64,' + base64.b64encode(buf.read()).decode('UTF-8')
buf.close()
png
@mentaloid I hope you don’t mind.
Out of natural pessimism had little hope it would work but it did!
I love the whole running of python within logseq. Brilliant stuff.
I don’t own that code, but I don’t mind either way.