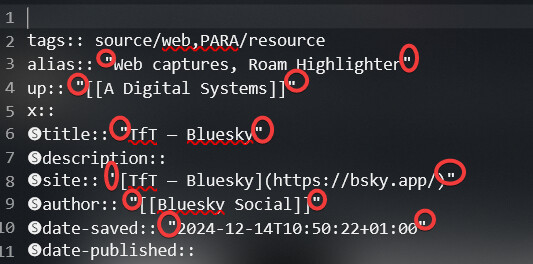
One of the solutions I’m testing out now is SingleFile, mentioned above, although I honestly haven’t tested it with paywalled content because I tend just to load those from Archive So far, it does successfully capture the web page, and since it supposedly works based on what you actually see rendered on your side, if your credentials get you through the paywall and it loads fine in your browser, it should be OK. You just have to figure out what to do with the HTML file from there.
Since it’s captured as an HTML file, I’ve been trying to use syncthing to get it onto my eInk tablet so I can read it in KOReader, the nightly release of which now has color highlighting.
The part I haven’t solved so far, though, is getting the KOReader highlights and annotations into Logseq. I think that’s what KoHighlights is for, but for the life of me, I cannot figure out how to install that tool and get it running. I’m almost 100% sure that’s my fault, and on some level that’s so basic it should be embarassing that someone has to explain it to me, but for now, that’s the missing piece for me.
There’s a KOReader plugin for Logseq, but apparently KOReader’s annotation files change quite a bit, which makes that plugin unreliable.
I’d have loved to use Zotero, which has SingleFile baked in, but Android support isn’t where I need it to be.
I don’t love having this many moving pieces, but alas, here we are.
Clippers based on Mozilla Readability (Omnivore and SingleFile are among them) are in principle able to clip what you are actually seeing, for they work with a copy of the local DOM. Check out e.g.MarkDownload if you prefer clipping in markdown format.
I am using zotero for ages, and it works well on a PC. However, a read later service must work on a smartphone imho.
I would love if the zotero webclipper would somehow be available from my android browser, but I did not find a working solution.
Did anyone succesfully use zotero as read it later or webclipper on android?
Well, not as great as Omnivore. I was actually planning on moving from Wallabag to Omnivore, essentially because of the possibility to take notes and then transport these notes automatically into Logseq. Wallabag isn’t great for note taking. It’s really about keeping stuff for later reading and maybe, for references, so, the use of tags can help put some order into this, but nothing more.
Now, I understand that it is possible to self-host Omnivore, but this means that you either need your own server or that the hosting company is equipped for people to be able to use an Omnivore instance set on their customer space. And that is far from frequent.
So far, I have been able to export my data from Omnivore using their export tool, without having to go through Obsidian, but I’m not sure what I’ll do next.
My understanding is that it’s theoretically possible, but their whole hosting system is so deeply tied to Google Cloud Storage that it’s virtually impossible to figure out. They had always promised they were working on this and would make it available, but as far as I know, it never actually happened, so it isn’t practically possible.
I lost even more respect for them because of that, since they know we can’t actually use their product anymore even though it’s open source.
Awesome that you found a way to grab paywalled content to Omnivore from mobile. I managed do it from a desktop browser, when logged into the site (New York Times, in this case) by right clicking and sharing it to Omnivore that way, but I was never able to replicate this success on a smartphone.
Thanks. I’ve been making do with the new Obsidian web clipper and syncing via Remotely Save. It works on mobile, too, which is really useful. Only bummer is that the entire vault needs to be synced, so you can’t just selectively sync the stuff you want to read on the go to your phone.
How it looks once pasted using the clipboard in Logseq
What I didn’t figure out yet is how to get the $TAGS as I have in the Logseq example. I had to manually add the [[ ]], because if you add them within the script, you end up with [[TAG1 TAG2 TAG3]]. I wrote the author, @wirtzdan . I hope he can guide us.
Does this work at all on mobile, though? That was Omnivore’s killer feature for me, that I could just snip to it from any device and read on any device. Someone had even made a version of it that could page through articles rather than scrolling, so it didn’t ghost up my eInk.
Only being able to read and process stuff on my computer doesn’t solve my problem at all.
@SpiderMatt I’ve been using the Obsidian web clipper, too, and it seems to work very well. I haven’t tried importing any clippings into Logseq, but they’re just .md files, so it should work.
Omnivore was supposedly open source, so maybe someone will fork it at some point.
One option is to create a separate Obsidian vault just for clippings and sync that to your phone.
@Synchronicity, yes, it was open source, but as far as I know, the back end support to actually self-host it was never completed. It was supposedly just around the corner, right up until they quit on us.
I lost an awful lot of respect for that team over the way they handled this. I already didn’t trust ElevenLabs, but this cements it for me.
I guess that’s always the risk when the primary copies of your data are sitting on someone else’s server.
Skiff handled it worse than Omnivore did. They shut down and blocked access to their very active Discord at the same time they first announced that they’d sold out and that everyone had to export their data within a short time or lose it.
It was easy enough to get my data out of Omnivore. That’s not my complaint. And I’m glad they backed off to 30 November instead of 14 November, which was the original announcement. I just resent having promised they were going to make it genuinely self-hostable, and quitting without ever getting there.
Skiff always required trust. But I hate Notion on an extremely visceral level (LOTS of corporate bullying to use it use it use it even though my brain does NOT work on a database model–which, yes, I know, is a problem for me if Logseq development doesn’t fork), so I’m willing to call selling out to Notion even worse than selling out to ElevenLabs.