Premise
In Logseq references to pages are used to tag content.
But pages are also the “root blocks” because each block is a child of a page.
Problem
When trying to figure out if something must be a block or a page, the difference is:
- A block is placed in a context and in the outliner hierarchical structure and so it is great to organize stuff. But since they are not in the graph you would lose important connections (references in the block, in its children or its path).
- A page will be a node in the graph and every reference in it will be a connection. But a page is just a “root block” so you will lose the structure above.
Solution
Provide a way to display certain blocks in the graph as nodes and the references¹ as connections.
A way to trigger this could be to treat title:: property of blocks as special property: if present the block will be displayed in the graph with that title.
[1]: about references, at the moment blocks are tagged using references in their path; instead pages are linked (at least in the graph) to references in their children.
So which references should these titled blocks be linked to? I’m not sure, maybe all references (in path, in content, in properties and in children)?
To make it clear: I’m not looking for a way to reference those blocks by their title (so no need to make unique titles); those blocks would be referenced by IDs like the others.
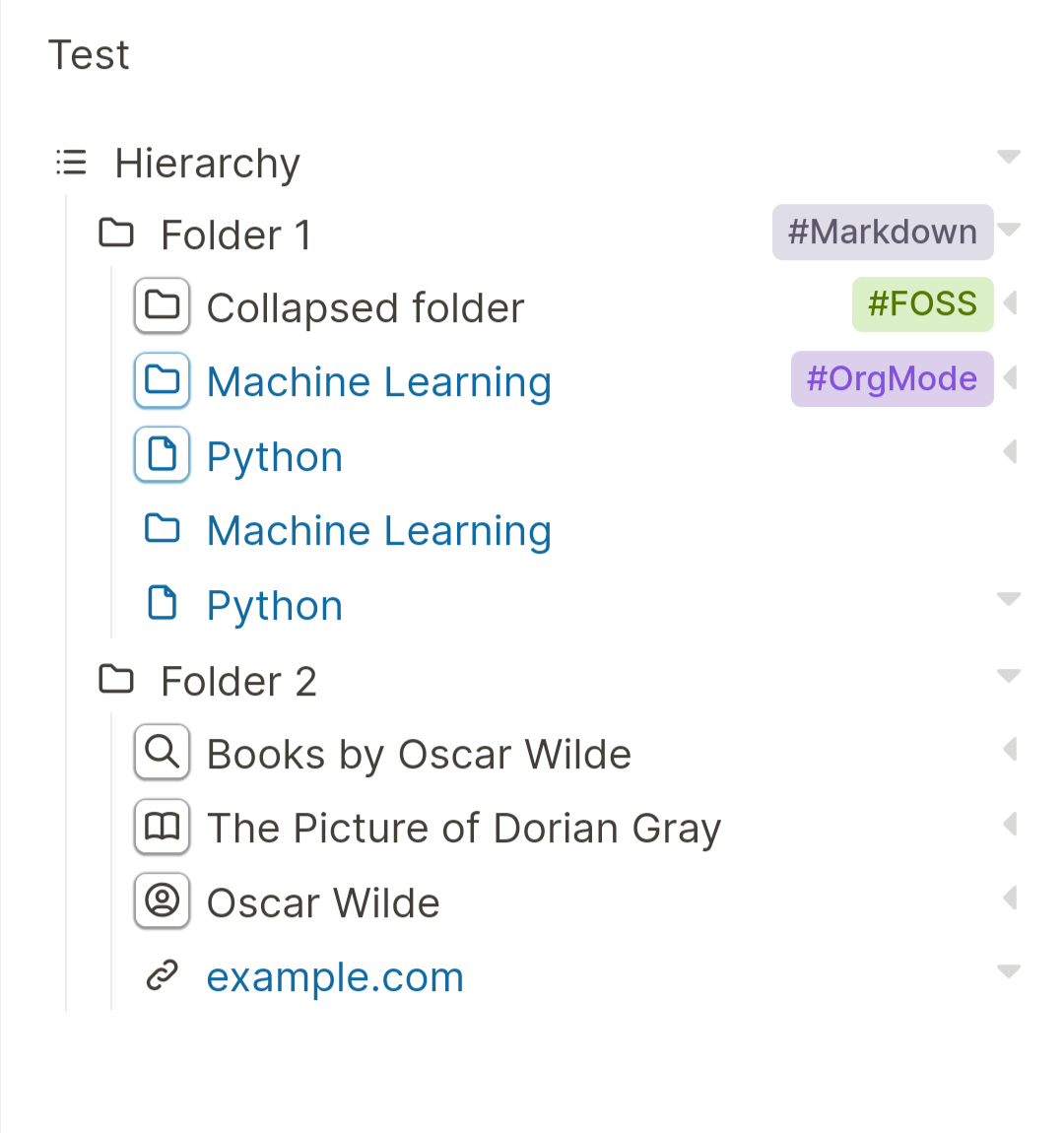
Here there is an example:
- title:: The Picture of Dorian Gray
author:: ((1234...))
- title:: Oscar Wilde
id:: 1234...
Both The Picture of Dorian Gray and Oscar Wilde would appear in the graph as nodes and linked because the latter appear in a property of the former.
Maybe when a block with a title is referenced using ((id)), it could be rendered as its title instead of its content.
I think this should be enough to let us organize the nodes of our graph freely with the outliner structure instead of being forced to introduce pages that have not that structure because they are all “root blocks”.