As someone who used a lot of tables in Notion before I moved to Logseq, query tables (even after understanding the query language) have always been a little too hard to use for me to integrate them into my workflow. So, if I’m working with structured data, I’ll usually just go back to Notion, which I’d rather not have to do.
Below is mockup of a workflow that would be possible with a revamped query table feature, followed by an itemized list of potential improvements to the user experience (most but not all of which are shown in the mockup).
Hopefully the mockup also shows the benefit of each individual idea, since while some of these suggestions are small features that would hopefully have very low friction to implement, some would be larger features that would take refinement and development time.
Mockup
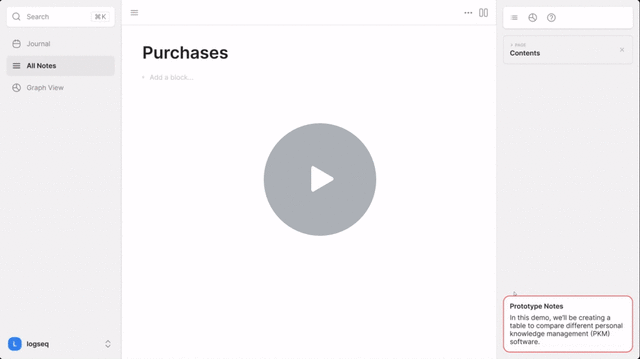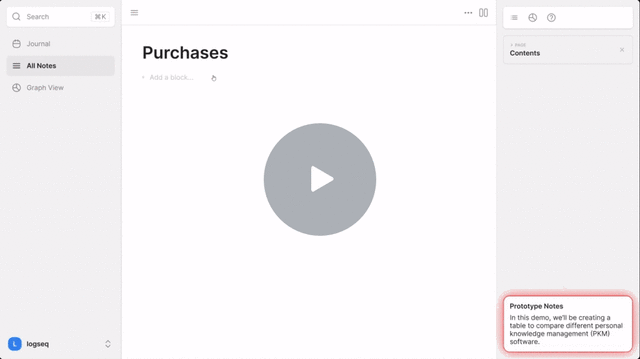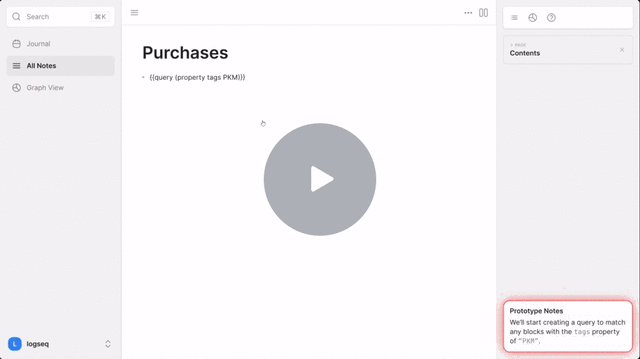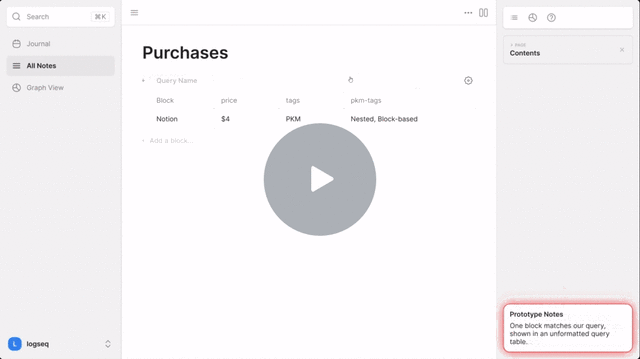
Features
1. Add ability to edit property values within the table
- I think this is the most important, and also the least friction to implement of the changes. Currently when you click on a cell in a query table, it opens that row’s block in the right sidebar, where you have to edit or add in the property you want. If instead, you could edit the property value in place (as shown in the mockup below), query tables would transform from simply a way to visualize information into a powerful editing tool as well.
- This could be integrated with the property autocomplete feature too, furthering the quality of life improvements
2. Revamp the settings popup
- Currently, the settings popup only allows you to toggle properties on and off. I think that it could serve as a home for a number of improvements to the overall experience. Most of these would be either simple UI changes or (hopefully) simple feature implementations, but establishing the settings popup as the home for table options would provide foundations for more ambitious features.
- a) Reordering properties
- As outlined in feature request #2809 (I can’t post more than two links otherwise I’d link this), the order of properties in a table is currently only based on the order in which they were created the first time.
- It would be very useful to allow for reordering of that so that users don’t have to think about that when first creating properties
- Implementation-wise, I’m not sure where the metadata is stored in Markdown for the visibility, but order could be stored along with that
- b) Table view toggle
- This would mainly be to simplify the header UI of the table, and establish the settings popup as a unified hub. I personally have never frequently toggled between the two views, so the additional click is worth the simplicity (especially on mobile devices). If people do switch often then potentially could remove this or make it optional.
- c) Query editor
- In a similar vein, the actual details of the query are not that useful for day-to-day editing. Especially if there is ever a visual query editor, it would be much more useful to give a name to a query to show as the title of the table, then edit the actual syntax of the query in the settings panel.
3. Add spreadsheet/database features
- The last major category of features I think could eventually be added would turn query tables into a spreadsheet/database competitor, similar to a Notion or an Airtable. These would obviously be far into the future and require lots of refinement and work, but would
- a) Property types
- For richer table values, it would be nice to have Notion-like property types: plain text, number (with formatting options like price), single tag, multiple tags (aka comma separated properties), checkbox, etc. I think these could be stored along with visibility and order within the query metadata in markdown. Right now, I imagine these per-table, with an error state for any values that don’t fit the type. Not really sure how it would work globally, but could be possible.
- b) Column calculations
- With property types in place, this could allow for calculations at the bottom of columns. Even without types, we could include count, empty count, not empty count, percentages, etc., but with types there are also the possibilities for sums of number types, counts of checked types, etc. These, too, could be stored in property metadata (though would need to be calculated on the fly)
- c) Formulas
- Adding formula properties would be a major upgrade to the database capabilities of query tables. I think it would be easiest to implement them on a per-table basis, and the actual formula for each formula column could be stored with the query metadata in markdown (also would need to be calculated on the fly).
- These would probably have to be block-scoped (e.g. the formula would look like
this.price - 5) - In the far future, could be global scoped values (e.g.
((1234-block-uuid-1234)).price - 5), though this would need to be per-cell and not per-column
4. Table view for block properties
- The last thing that I think would improve the table experience would be the ability to view individual block properties in a table view, rather than the current list. This would greatly improve the “put new table items in the daily journal” workflow.
- Additionally, in a world where some of the of the previous features were implemented, there could be a way to link back to a specific query in order to get the property order, property types, formula columns, etc. from it, and sync what properties are shown (including ones that the linked block doesn’t have values for yet). Also, there could be a button that links to the query to easily navigate between the individual block and its query.
Final Thoughts
There are a few other improvements that others have already suggested that I’d like to see (e.g. feature requests #2992, #7018, #7652), but I think these are all new feature ideas. Also, I put all of these in one post since I think they build off of each other, but if I should repost them as individual feature requests that can be voted on, let me know.
I think that in a world where all of these features could be implemented, Logseq would be a unique combination of structured and freeform thought, where we could put ideas into our daily journal as we have them, but still be able to analyze them in a traditional way. I’d love to hear other people’s opinions on any/all of these ideas, or potential improvements, feasibility issues, etc.