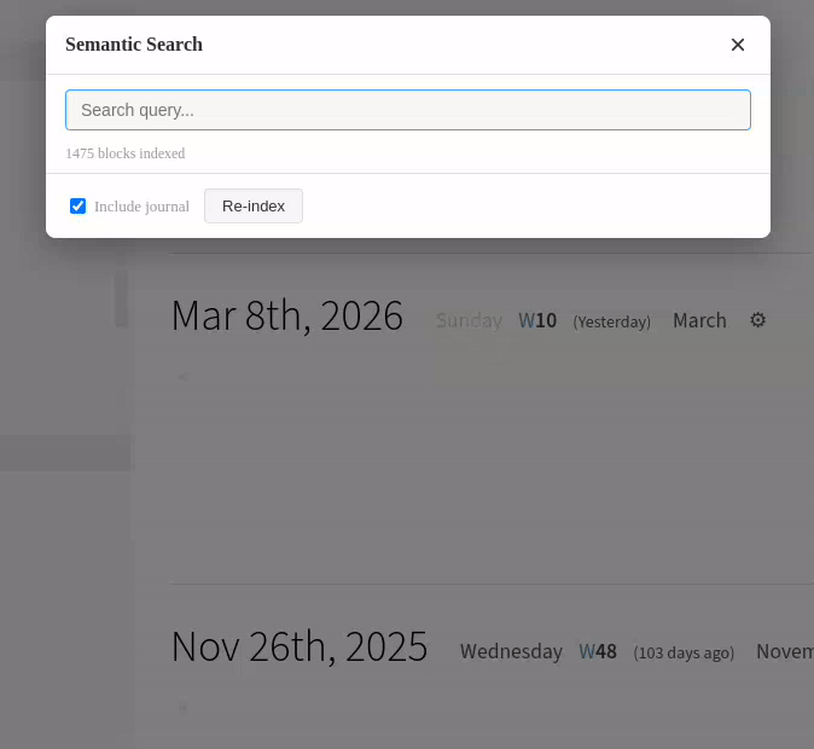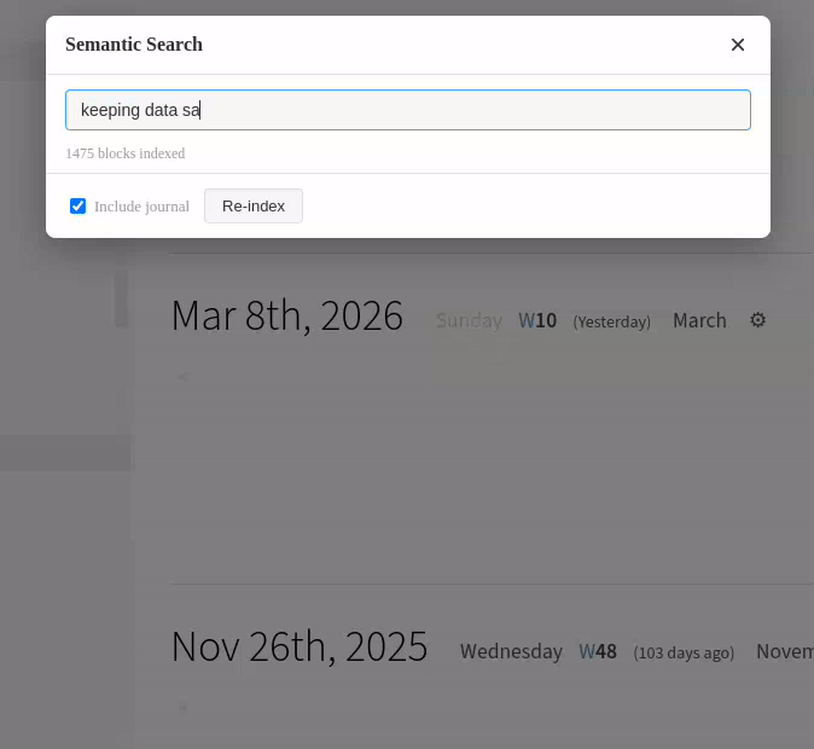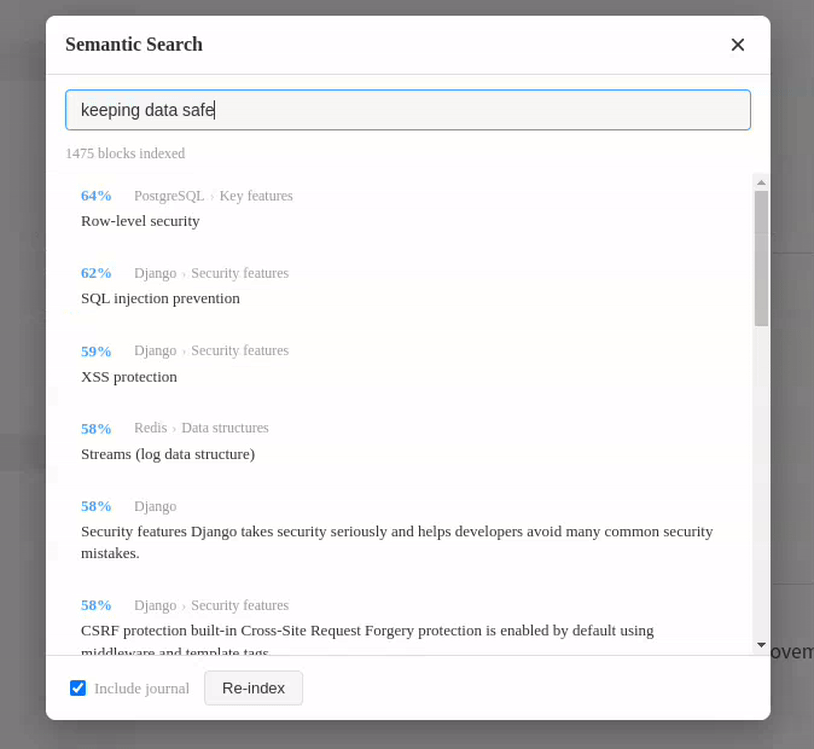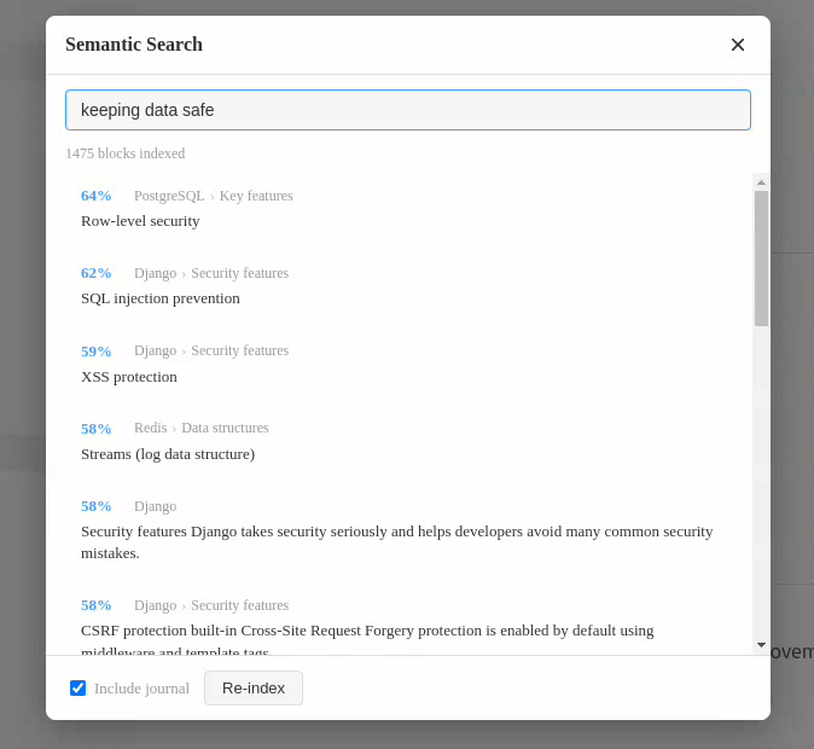
I made a plugin to search for blocks with similar meaning to the search query. Although the Logseq DB version has something like this, I wanted to use it in my Markdown-based daily workflow on a rock solid version.
It doesn’t need a GPU, although for large graphs you’ll find it speeds up the initial indexing process. For searching, though, and catch-up indexing as you make edits, CPU is definitely fast enough. This demo is CPU only:
It’s not using a full LLM, just a text embedding model. It runs locally, using ollama.
I’ve been finding it incredibly useful, since my graph is over a year old and full of things I’ve already forgotten.
I didn’t need to do anything with permissions except expose the port from the container I was running ollama in. I described it here but it’s basically:
podman run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama docker.io/ollama/ollama
The -p option is what does it. (If you want to let the container use a local GPU you need to pass some additional options, depending on your OS, GPU and container runtime.)
I did that and I can access the server with CURL. But if I start the plugin, I get “Cannot reach embedding server. Is Ollama running?” and the log says: