Hi Logseq community!
Like many of you, I love using Logseq as my sovereign Second Brain. But recently, I hit a massive wall when trying to build local AI/RAG tools on top of my notes. Standard Markdown chunkers (like the ones in LangChain) just cut text blindly. They completely destroy Logseq’s outliner structure, losing the parent-child context of the bullet points.
I wanted an engine that respects our thought hierarchy, so I built the Logseq Matryca Parser (The Logos Protocol).
 1. The 60FPS Visualizer (LENS)
1. The 60FPS Visualizer (LENS)
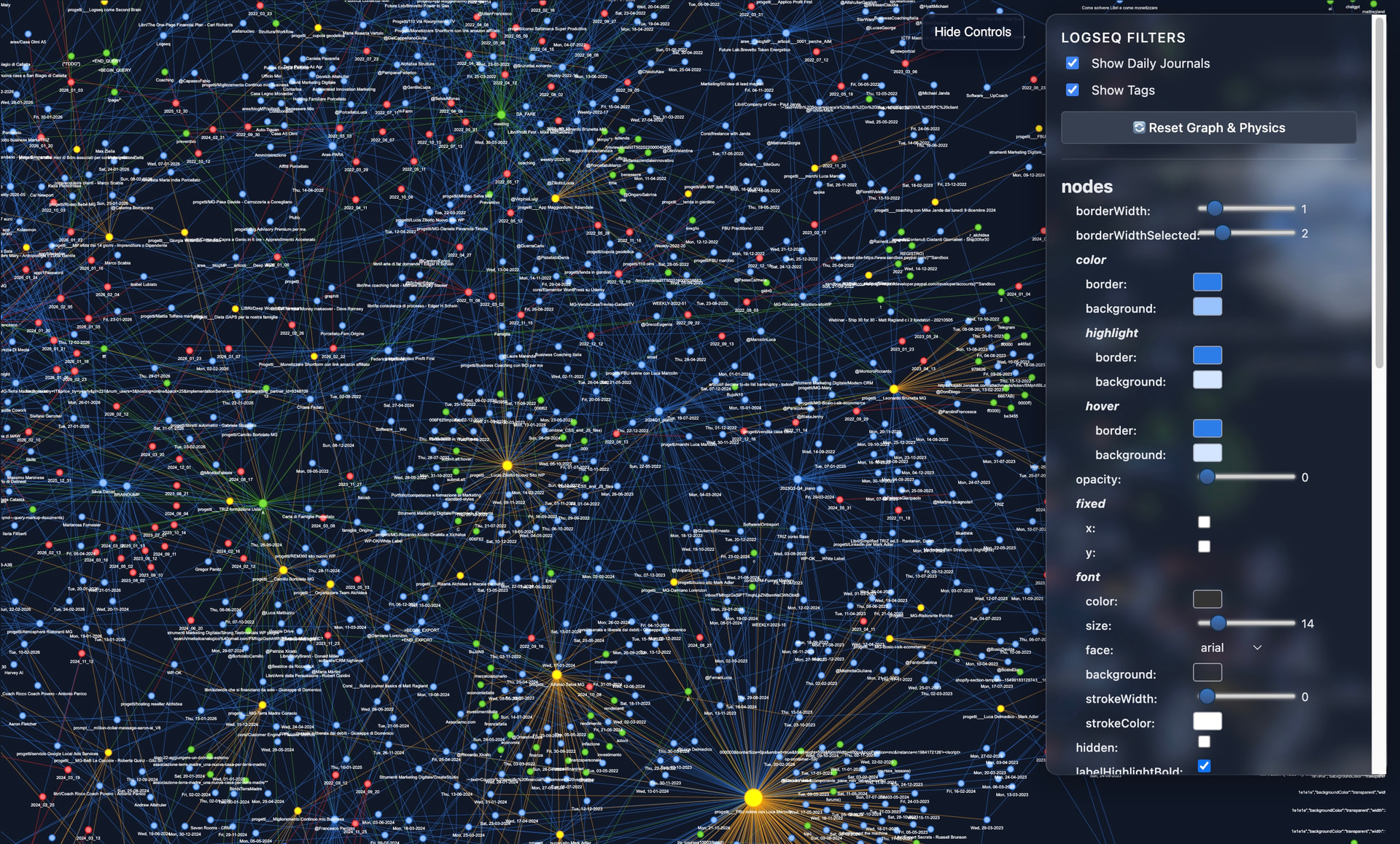
First, because visualizing the graph is vital, I built a highly optimized NetworkX/PyVis pipeline. It easily handles 7,000+ nodes smoothly. I also injected a custom Glassmorphism HUD to instantly toggle Daily Journals and Tags. Watch the 15-second demo of the graph exploding and the filters in action: > ![]() https://github.com/user-attachments/assets/24f73c6d-3eca-4adb-8442-981f2ba4cccd
https://github.com/user-attachments/assets/24f73c6d-3eca-4adb-8442-981f2ba4cccd
 2. AI & RAG Ready (SYNAPSE)
2. AI & RAG Ready (SYNAPSE)
The core of the tool is a deterministic Stack-Machine parser written in Python.
-
It reads your graph and understands spatial indentation, block references
((uuid)), properties, and temporal journals. -
It exports directly into LangChain
Documentor LlamaIndexTextNodeformats. -
The Magic: It injects the hierarchical relationships directly into the metadata. When you feed this to your local LLM, it finally understands the context of a nested bullet point!
 3. Sovereign & Local
3. Sovereign & Local
Everything runs OFFLINE. Zero telemetry, zero cloud parsing.
Links:
-
Try the Live HTML Demo directly: https://marcoporcellato.github.io/logseq-matryca-parser/
The codebase is fully open-source, strictly typed with mypy, and well-tested. I built it to scratch my own itch, but I’m releasing it today because I think this community needs a robust way to bridge Logseq and local AI.
Let me know what you think! PRs and feedback are highly welcome.