I want a better way to discover more logseq public graphs.
I’m proposing some simple namespaced page properties to help us find eachother.
I want a better way to discover more logseq public graphs.
I’m proposing some simple namespaced page properties to help us find eachother.
Am I missing something or you can’t actually “follow” someone in the sense you can’t see what’s new from them?
Can’t one just list interesting other graphs in their public graph? What’s the point of standardize if there is no communication (if I understand it correctly)?
All the rest still needs to be build: How to follow a graph, how to see if somebody links to your graph, etc. But to build tooling you need some standard. This is a first (possible) step. Building in public is a good way to get feedback, and see what works.
The problem is that on static websites you can’t do much and I don’t see what’s the advantage of this compared to just lists public graphs somewhere.
When it comes to decentralized social networks there are the ActivityPub-based ones like Mastodon and there is also Matrix as a powerful protocol to build all sort of decentralized apps.
You are comparing apples to oranges here. For now Logseq export is just a static website. We hope to make it more dynamic in the future, the indieweb direction is promising. ActivityPub albeit very nice, is not something even in the picture.
The goal of Logseq is not a twitter wannabe, it is to use, and later share knowledge, not as short-term chat, but as long term collaboration. Mastedon and Twitter have there place, but neither are suited for long-term knowledge work. Best would be a semi-static setup. Static so people can depend on it staying in place, being able to link to it, semi- for cooperation and backlinking.
I am not the one using the term “decentralized social network” here ![]()
Again, how do you implement any “social” feature on a static website? Here there is a major design issue, not something you can put under a “let’s see in the future”.
IndieWeb has existed for a while now but the only protocols that got to the masses are ActivityPub and Matrix, both usable for any kind of decentralized communication, not only social networks and instant messaging.
Maybe what you are looking for is something like WebMention i.e. get a backlink when someone link a public page of yours in their public graph?
Webmention is indeed something I’ve been looking into. It depends on the multi-user implementation what we will have to do to cooperate with other graphs.
These are all really good questions and expected to get comments like these when I’m calling it a “distributed social network” ![]() (but maybe you wouldn’t have looked at this post otherwise?)
(but maybe you wouldn’t have looked at this post otherwise?)
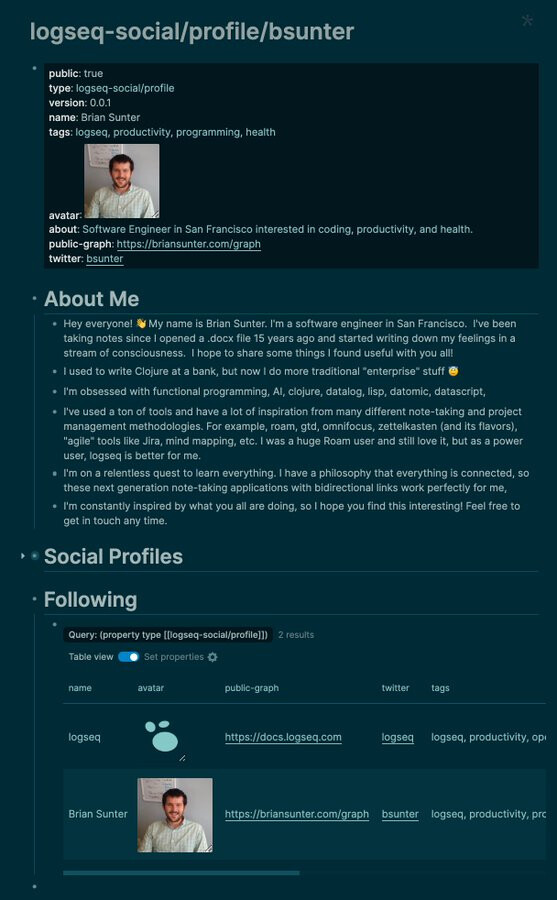
Really it’s just a self hosted “profile” page thats slightly smarter via logseq properties.
My thought process is this
Im self hosting my own graph, so I probably want an “about me page”
Instead of just writing it as pure plain text, I add a tiny bit of structure for my name and graph link.
I want to discover other graphs and build a link ring. Having other profiles in this format lets me organize them more easily than just plain text anyway.
As for all the features and protocols you mentioned,
People are already building tools to query remote graphs or multiple graphs. A recent development that opens a lot of possibilities is self hosting your graph and querying it programmatically.
I could imagine building a lot of the features you mentioned like webmention by querying your friends graph for mentions of yourself.
Or transforming the output of your graph into a form thats compatible with other protocols.
Theres a really good hackernews thread about logseq-social and other protocols like the ones you mentioned here Let's build a decentralized social network together with Logseq | Hacker News
Step 1 for every future social idea is convincing people to share their graph publicly with a simple profile page.
I still say even the simple link ring without anything fancy is still useful today. Seems like every other social else can be built on top of the profile page and friends list later on now that we can query multiple graphs programmatically.
There could be a social plugin to run queries against public graphs and save the output in your notes, which would enable a “static” self hosted social network.
Ill update the original post since the public graph api thing is new since I wrote it.
If you don’t know it I suggest to take a look into Matrix and hope Logseq developers will built something on it.
Matrix is a set of protocols for both federated and distributed networks and it basically create a shared database where nodes can read/write using a built-in ACL mechanism (so it’s not public-first like ActivityPub, it supports private communications and has e2e encryption).
Matrix is resilient in the sense that if some nodes disconnect the others operate as nothing happened and the data in common is still available. If two networks (re)connect to each other they integrate and consistency of data is ensured.
In my opinion Matrix is the natural evolution of the IP/TCP Internet, adding a layer inspired by biological systems.
Of course when creating shared knowledge graphs one would like Matrix capabilities: you get resilience, consistency, permissions to access/edit the data, no-single point of failure, end2end encryption.
Sadly it seems Logseq developers didn’t even know most FOSS projects uses Matrix for instant messaging and they can just bridge their Discord channels into Matrix.
I think it would be awesome if there was some sort of fusion of blocks + chat
Seems like that would be the holy grail. A lot of slack messages at my work are worth a wiki page ![]()
I’ll definitely look more into matrix (I’m just a user of it) . Maybe there’s a way to integrate matrix as a plugin.
I love the idea of having a personal graph published with ability for others to accrete their reasoning on top, as part of their public personal graphs. This would allow people to collaborate and not in a throw-away message-based form, nor of that of wiki with mutable pages and fights for place, but of annotation, allowing for ever-growing graph of knowledge.
It seems to me, that one crucial for a public graph property is immutability.
It is important because:
I really hope we’ll have it, as it seems of utmost importance to me.
Perhaps hosting our graphs as part of an immutable global graph is what we want. E.g., IPFS.
It also seems very appealing to me to have a formal graph (e.g., via properties that link to other blocks) as part of free-text graph for programmatic manipulation. An example of how it could be used.
Given that our graphs are hosted as part of an immutable graph it may be pretty cost-efficient for one to grab “novel stuff of others”.
I’m thinking exactly along these lines of a “static immutable social network”
I actually think hosting individual blocks in ipfs that are content hashed and a plugin to manage them is my favorite idea.
You could imagine a “remote block ref” that pulls from ipfs.
Ha, putting a plugin to use sounds interesting.
I guess it would need to:
Publishing a block seems possible, but I’m not sure if we’ll be able to fetch it back, because logseq identifies blocks by :db/id so we won’t have a CID on our hands to fetch with…
Thinking more generically, it seems logseq has mutable design.
E.g., blocks are being updated, deleted; and as blocks are referenced by :db/id what they resolve to may vary over time.
Perhaps if we are to host our graphs as part of a public immutable graph, we better make ours immutable first. That would imply referencing entities by CID’s instead of :db/id. I see two ways it could be done; pretty but impractical, and not-that-pretty but practical:
e = (hash AVs).:block/cid, and reference them by it, via a look-up ref, e.g., [:block/cid <some-cid>].As I’m giving it more thought, having immutable graph by having entities reference each other via [:block/cid <some-cid>] is not possible, as such a reference exists only in transact time and resolves to a :db/id.
So the only option we have, it seems, is to e = (hash AVs), xtdb style.
Just a thought: we already have a history of blocks’ content in git tree (if we use it). Given a block ID, wouldn’t it be possible to reference a certain version by using both block ID by Logseq and whatever is used by Git to identify a version?
Then when referencing a block that way (i.e. graph URL + block ID + Git versioning) the UI should present the option to display the content of that precise version or the latest one. This way who references the block can decide to “freeze” the reference at a certain version or to “stay updated” to the latest one available online.
I hope I made it clear.
It’s an interesting idea.
It would be possible to uniquely identify a page by it’s git hash alone, as git uses content-addressing.
This is a solution to “how to identify a block”.
Challenges are:
So far, having (hash <block>) seems more appealing to me.
However, having it via git is an interesting solution, good to have it on the table.
As about referencing via graph + block + git hash, we’ll face the same problem of such references existing only in tx-time and being resolved and stored as :db/id, forementioned here.
As for having references “frozen”, that seems to me to be a crucial property for publicly available reasoning.
And that, in couple with fact that it is a common practice to iterate over (refine) one’s reasoning, creates an interesting problem you mention, when one would like to get the latest reasoning of another.
That problem consists of two parts:
How to express that there is a refined version of a block?
How to discover a refined version of a block?
One solution would be to assign block a name and keep versions.
E.g., having a uuid for a name (or graph id + block id)
<block 1> is <uuid>
<block 1.1> refines <block 1>
<block 1.1> is <uuid>
Then, referencing <block 1> one may discover that there is <block 1.1> and may choose to upgrade.
However, in order to discover that, it seems we don’t need to have a name, simply having
<block 1.1> refines <block 1>
would suffice.