I love logseq, however I find myself context switching a lot as I jump across pages when looking at references. Open in sidebar reduces context switching here a bit, but it is one level deep so it’s utility is very shallow.
It would be amazing if logseq took some inspiration from Andy Matuschak’s notes which reduces context switching even in a very deep rabbit holes by:
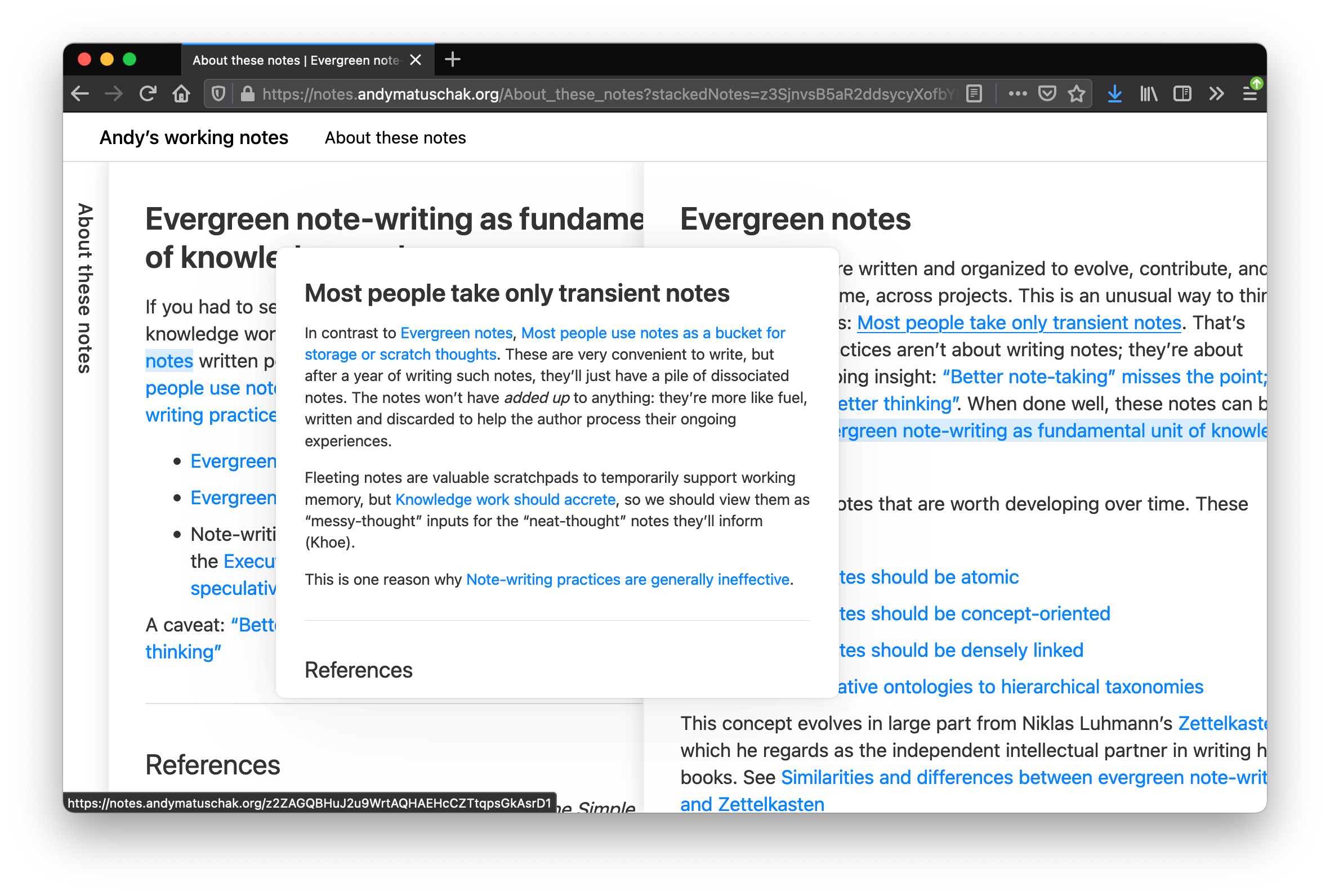
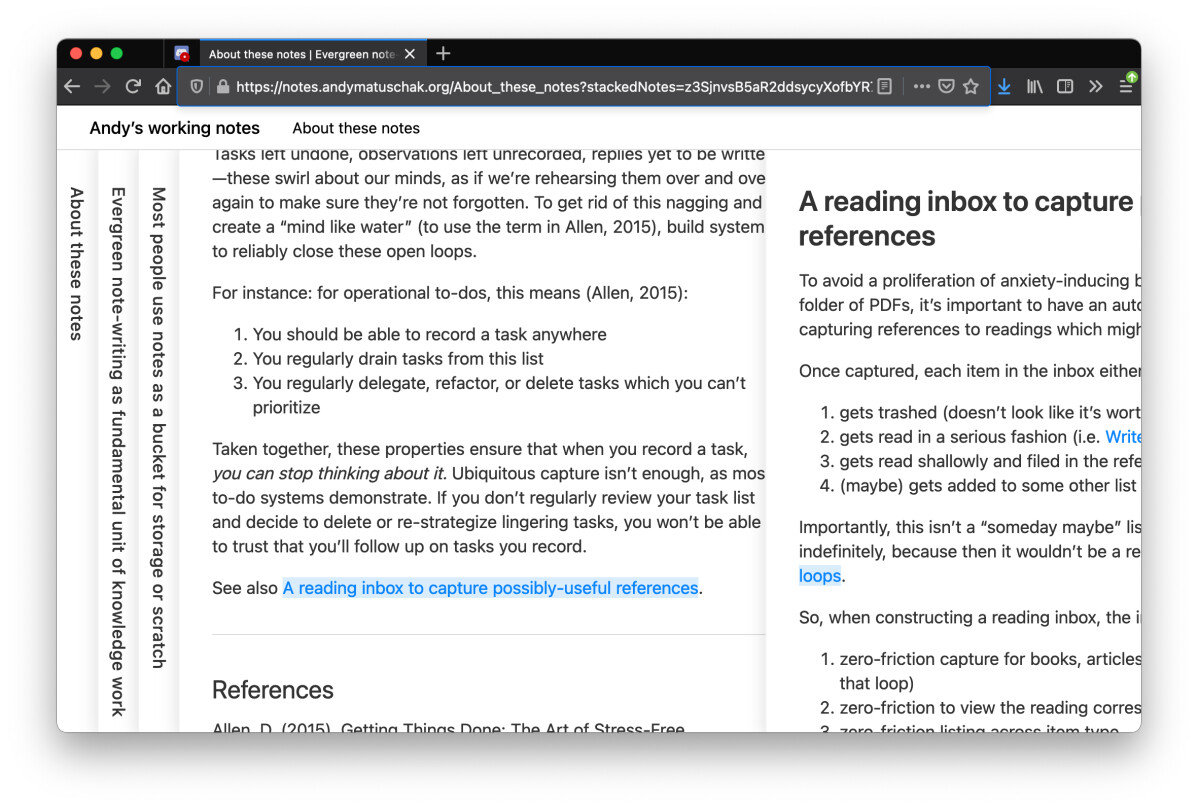
Using providing quick previews when hovering a reference via tooltip style overlay
It also hooks into (I think) wheel events so you can slide pages in the stack to peek at things as you need (although I think this part can could use a lot more improvements e.g. clicking a header in the stacked could slide it into the view and doing swipes over the title should probably interact with the page under the cursor as opposed to the the one on right side)
I think all these pieces together help retain a context. Furthermore pages/headers provide a trail that help you contextualize how you end up where you are and from where without cognitive effort that would go into recalling and may lead to loosing a context.
P.S.: This was prompted by discussion regarding left vs right sidebars, I believe there is some overlap between two and I believe that continues stack of pages could provide much better experience than sidebars one has to manage. E.g. one could allow pinning specific pages that would effectively provide a sidebar functionality.
I’ve also in the past worked on the research project that identified navigation trails (think page stacks) as way of enhancing our cognitive process as opposed to loading it. You may find our post about it quite relevant Lossless Web Navigation with Trails even though it is in a different context I think most findings still apply.
Through that research we also found that spacial interfaces really help with this and our post about it might be useful resource here A Spacial Model for Lossless Web Navigation
Interesting article - and interesting approach to solve that issue also.
I think the basical problem behind all that is that we simply cant enough screen space to keep all the lookups we need in sight together. Even 4,5 or 8 screens like in obsidian is often not enough.
I’m a professional writer and journalist. Connecting (and interpreting) a lot of little facts is my daily bread. And for a single sentence like, let’s say, “elelctric cars are not zero emission in fact because of the carbon footprint of the electricity they use” will need up to seven single facts if you would want to state how much all cars in your country would emit still altogether.
You can do the lookups one after another and jot your findings down. In most cases that will happen like this.
An easier way would be if the right side would be a fully functional clone of your main page you can search in and from where you could just drag all blocks plus the needed linked resources and text resources from the pages over to the left, where they automatically turn into embedded blocks. You can bring them into sensible order then and have everything ready to start - almost painless and very frictionless research.
For myself I’ve switched to rely on my brains capacity though. Reviewing your facts in effective spaced repetition costs me 6.5 seconds (my personal average) × 5 reviews for each item I write, so roughly additional 30 seconds in the following 12 months to rely on my brain.
The speed gain in writing is enourmous then, when you can spare the whole time for typing in your query, scroll and read and then jot down the results. The initially invested 30 seconds pay off multiple times in the end, cause your brain just needs milliseconds to come up with the result, so almost in no time.
Plus you can play the wiseacre in discussions, add new facts to problemsolving, signal competence in interviews and can correct someone trying to sell you bs in interviews on the spot.
That’s why I think a simple spaced repetition function for blocks would be an invaluable gain in efficiency in Logseq.
To use and best support the much higher efficiency of brains is possibly still altogether a lot more efficient than any technical solution that tries to bring all facts in front of your eyes together. IMO that often gets too much neglected.
Plus, when you remembered things, they start to “simmer” in your brain, form connections and insights. When the facts appear on the screen you just start connecting them only the moment they appear. Databases and second brains are backup resources that add a noticeable retrieving time for information pieces - processing only happens in the first brain, and what’s already put into the working memory (RAM) has no retrieving time.
Researching things newly in browser is a totally different scenario though - and for this I find the approach with trails very interesting and definitely a great enhancement when I imagine it in action. I’m not sure though if it’d add so much efficiency gain in logseq. Dragging to embed from one side page seems more frictionless and faster, but that’s just me.