After experimenting with LogSeq for quite some time, I would now like to use it more frequently and regularly. When using unordered and ordered lists, I am unsure how they should be used.
If I understand the documentation correctly, there are two options:
- Use a separate block for each entry
- Use the Markdown approach with a block of entries
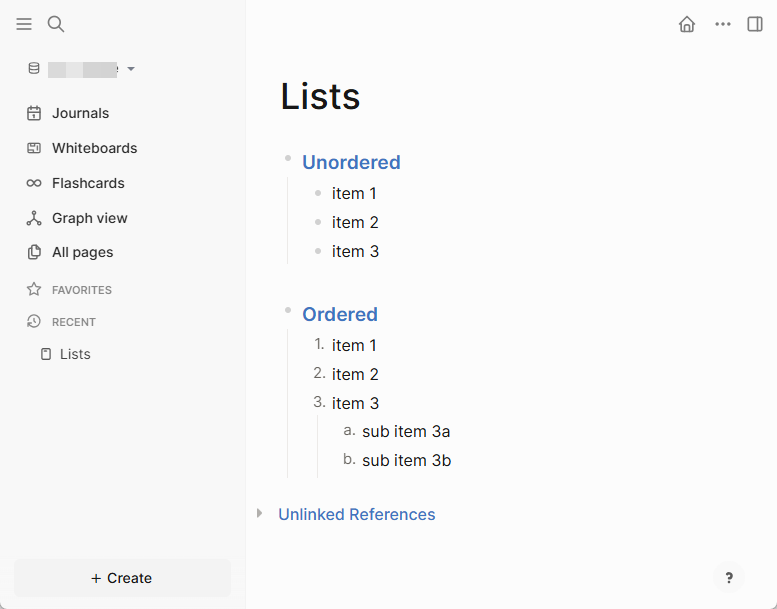
To illustrate what I mean, here is an example of a separate block for each entry
- Unsorted list
- Entry 1
- Entry 2
- Entry 3
-
- Sorted list
- 1. Entry 1
- 2. Entry 2
- 3. Entry 3
And here is an example of the Markdown approach with a block of entries
- Unsorted list
* Entry 1
* Entry 2
* Entry 3
-
- Sorted list
1. Entry 1
2. Entry 2
3. Entry 3
The advantages of the first option are:
- Multiple levels are possible.
- It corresponds to the typical structure of LogSeq.
- It is easier to write.
The disadvantages are:
- It is not always clear, especially with multiple levels, where the list begins and where it ends.
The advantages of the second option are:
- The relationship between the individual entries and the list itself is clear.
Disadvantages:
- Only one outline level is possible
- More time-consuming to write
My questions, which I have not yet been able to answer:
- Which option should I prefer?
- Which option do you use and why?
- Does one or the other variant have advantages in terms of
- using the md or DB version
- printing
- exporting to html and pdf format