I am running Logseq on an M1-powered iMac running the latest Ventura beta. I have Logseq always on, as it is my goto app for note-taking, todo lists and time-tracking. I have noticed that the longer I keep Logseq running, the more CPU time it seems to consume. After a few days, CPU load creeps up to 100% for minutes on end, even when Logseq is just sitting idle in the background and hasn’t been touched by me for hours.
I have discovered that - apart from closing and restarting Logseq - the best (and relatively painless) way of getting Logseq to calm down is to re-index my graph. For some reason, that dramatically reduces the CPU time being consumed going forward.
While it is good to know this trick, I wonder what exactly could be causing this behaviour? Could it be a matter of cleaning up the in-memory database Logseq uses that so dramatically improves its performance after a re-index? Or could there be some rogue processes spinning up over time that are not properly stopped until a re-index is executed?
It would be nice to know the underlying reasons for this behaviour, so I can better manage Logseq’s load on my system. Also, if we know what is causing it, maybe future versions can have inbuilt load-management features. I wouldn’t mind, for instance, if rising CPU usage while being idle would trigger Logseq to do a re-index automatically in the background, as a kind of garbage collection, similar to what we used to have in the programming environments I used to work in (I haven’t done any programming in a long, long time, so I don’t know if garbage collection is still a thing).
I would love to know the answer to this. I too find the logseq renderer suddenly becomes unresponsive; usually after I’m switching windows (i.e. working in Logseq, switching to a Chrome website to read an email, and then switching back to Logseq). When I then check activity monitor the renderer is 90-130%, the memory profile isn’t changing. Its very frustrating.
I just recently started using LogSeq 0.9.8, have less than 10 pages with not much content, and I’m seeing high CPU/GPU usage even if LogSeq has been untouched for hours.
I see LogSeq using a constant ~30% CPU + ~25% GPU across 4 processes.
When restarted it goes down to about 2% CPU - but even that should be 0%!
Then some hours later I realize it’s once again the app using the most resources in my computer - way more than a video editor or Firefox with over 100 tabs open. Bit crazy!
Based on my research, I believe lazy-loading feature to be the cause.
The bug have reported in this closed issue still persists. There’s a suspicion that retrieval through lazy-loading feature is happening incessantly. This might lead to unnecessary resource loading, constant page refreshing, and potential consumption of CPU resources. Ideally, the lazy-loading feature should execute only once upon opening the page.
FWIW, I opened some days ago a Github issue about this, and posted there a few profile recordings where Logseq was supposed to be idling but its processes were using a notable amount of CPU/GPU.
Recording a profile is very easy, maybe others could do the same. Figma published Instructions here and they apply almost the same (the “toggle developer tools” option is in the View menu in Mac):
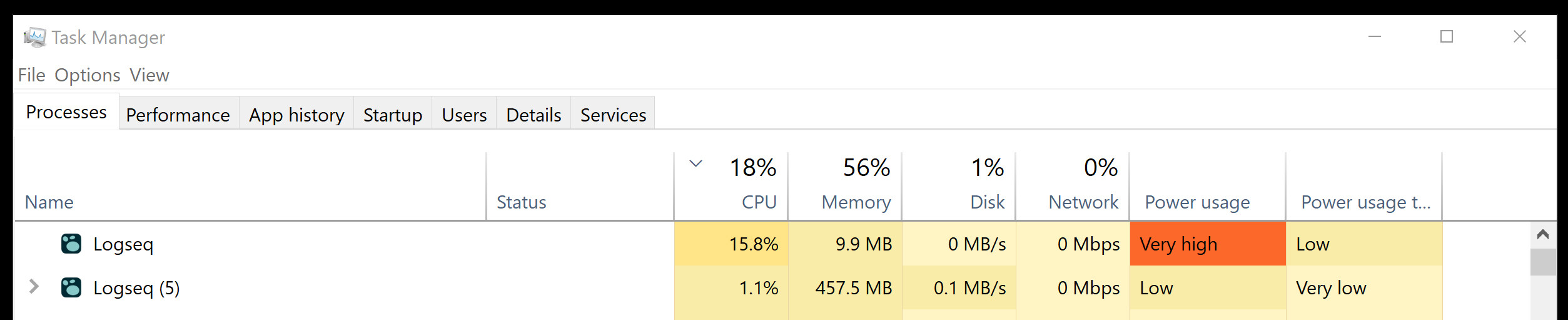
I think I accidently found a solution (at least on Windows) When I was in task manager seeing what was using so much CPU (like everyone else here) I discovered it was Logseq. In trouble shooting I was closing the program from the window, but at one point I did an End Task from the task manager, and then realized that Logseq was still running. Then I noticed that there were 2 processes of Logseq. The second process would run fine all day barely using any CPU.
So you have to do it each time you start the program, but that is a small price to pay to make it functional. I am so glad because I am new to Logseq and love it, and this was almost a deal breaker.
Just in case it helps anyone, I am on Windows 10 and running Logseq from the .exe file on my C drive.
I have included a picture: End the Process of the one that is using high CPU and leave the other one alone.
This still seems to be a real issue. I think the excessive usages interfered with a video call today (which is why I looked and noticed that logseq is using quite a bit of CPU even though it should be close to idle). I did notice that if I hide the right sidebar, one of the logseq threads calms down quite a bit – however, the other one continues to burn CPU. This would be good to hunt down as it will probably turn off users when they find out about it.