I’m a quite messy person, and yesterday, listening a couple of friends about obsidian, and looking information, I found this application. I’m starting to think how to use it and would like if others works in the same way.
(1) In one side, I have job. For this I want to use an exclusive graph because I don’t want to mix private things with company things. This is fine and I don’t think will change.
(2) On the other side, I have sometimes private tasks, and things about different hobbies (Chess, Go, videogames, sports…) I have. I have a couple of youtube channels and several social media for this accounts (personality disorder? )
I would like to know, about 2, if you use several graphs to separate all this different things, or use one graph and using tags mix all the information. I appreciate suggestion for organization of all of this. Just learning about tags and wikilinks no idea about other things like properties.
There are some AAR (After Action Reports) about how people use Logseq in his day by day?
I plop basically everything in 1 graph, but both are valid ways.
I dislike having to switch between graphs.
For each of my hobbies I have a seperate “landing” page.
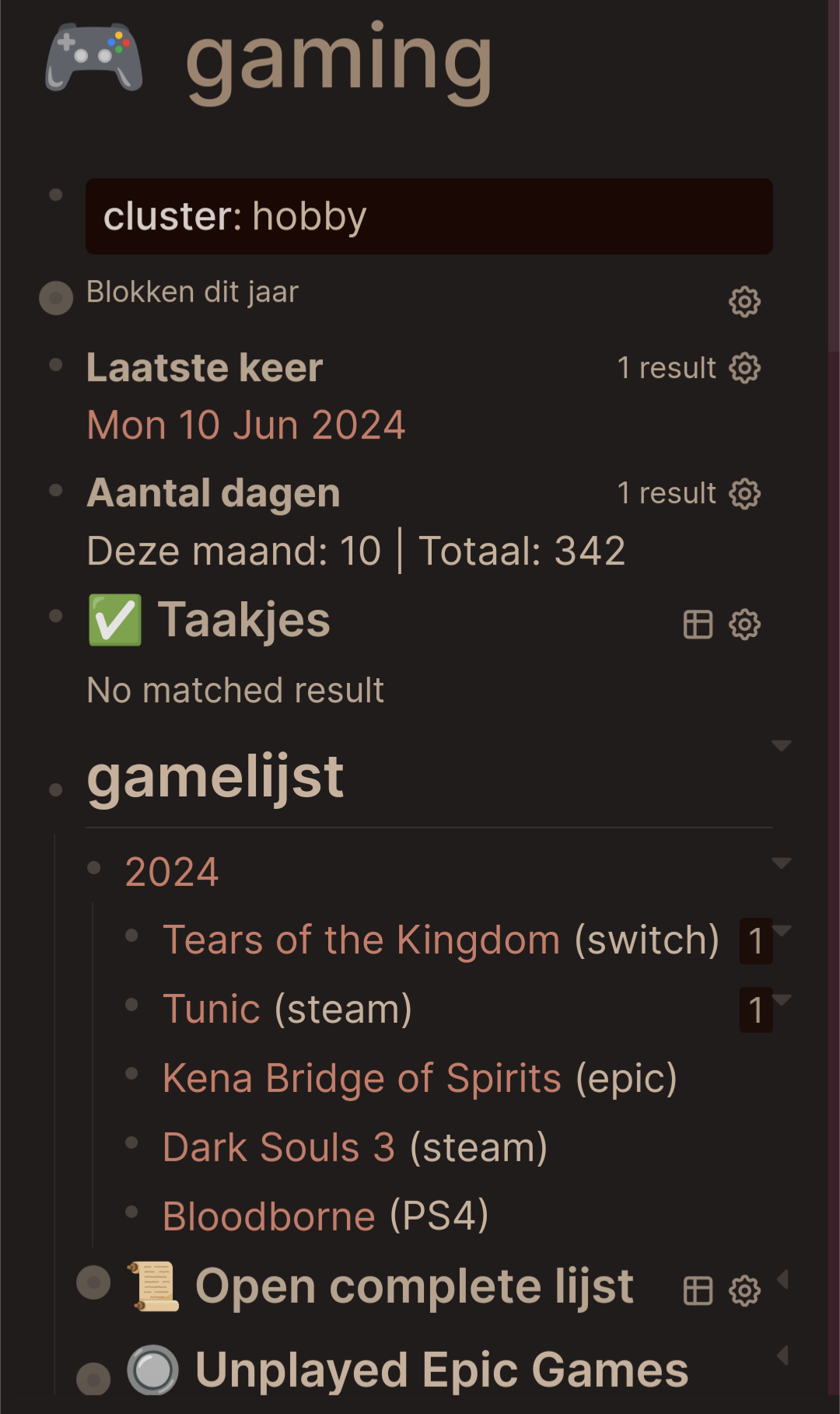
So for example I have a page gaming (I chose this specifically as a verb. But could be games, video games etc)
Which has the property cluster:: hobby (I chose cluster as in group instead of the more general type, but that’s personal preference)
Then each of my games has its own page with property hobby:: [[gaming]] to link it back to the “landing” page.
And that’s how I structured a lot of my graph.
I understand you don’t link from journal, you use directly that landing right? Sorry if it’s a silly question, but I’m still trying to acommodate my mind to this way of thinking and tool.
Only with external links (i.e. [label](url) ), which don’t participate in Logseq’s database (i.e. no backlinks etc.) The meta-graph is needed exactly to maintain proper links among the pages that represent each graph, otherwise it can be skipped.
I do link from the journal.
I do things a little bit silly to accommodate some of my own quirks.
But I would generally link to the gaming page and the specific game page whenever I play. This way I make a nice little logbook for myself.
The gaming page itself basically has an overview with games and statuses of those games through queries.
The pages for specific games have some properties for that game and whatever other info I wish to keep there.
But you should see what you like best.
I’ve changed my system many times to tweak it to better suit my needs.
Well, this is the issue. I don’t know what I like best yet lol. I just don’t totally understand if I reference from journal, what’s the point of the page more than see the references. Need to see more examples of usage cases
I am very iOS/Mac-centric so this won’t apply to everyone but,
The Mac app DevonThink uses a database model and one can have many open at once. I use it for many things: work projects (I’m freelance so it’s kind of one per client/job), a RSS type of scrapbook, receipt tracking and reporting, writing projects, document management, email archiving, journaling. Mostly there’s a different database for each purpose. There are some functions that only work within one database (replicants) and some that work across any open database.
I have one Devonthink database and one LogSeq graph for each of the major work projects I am involved in right now. I store all my docs in DevonThink and link to them from LogSeq. I do all task management and idea generation in Logseq. I can archive email in DT and link to messages in that archive from within LogSeq, which is great for chasing problems and solving them. I switch the open LogSeq graph to match the work I am doing. I use the GitHub sync and working copy to push sync to my iPhone and that works great (don’t ask me to explain how to set it up, I use the tutorial EVERY time)
It’s all doable with the current LogSeq one-graph-at-a-time model but if there was a DevonThink-like multiple databases open at a time paradigm, I could really make my system fly. I know that isn’t a priority for most people and I am not sure how it would work at the Journal level which I think is a strength of Logseq.
I too am doing this constantly and constantly finding new ways to do things. Reading this forum and the one for Devonthink is a really good way to see other peoples methodologies and how they might apply to my needs.
Two different things that. I’ll show you my example.
Here’s my gaming page. Everything that has a cogwheel () next to it on the right is a header of the query, everything indented under it is the query result. As you can see I use those quite a bit to gather info on this page.
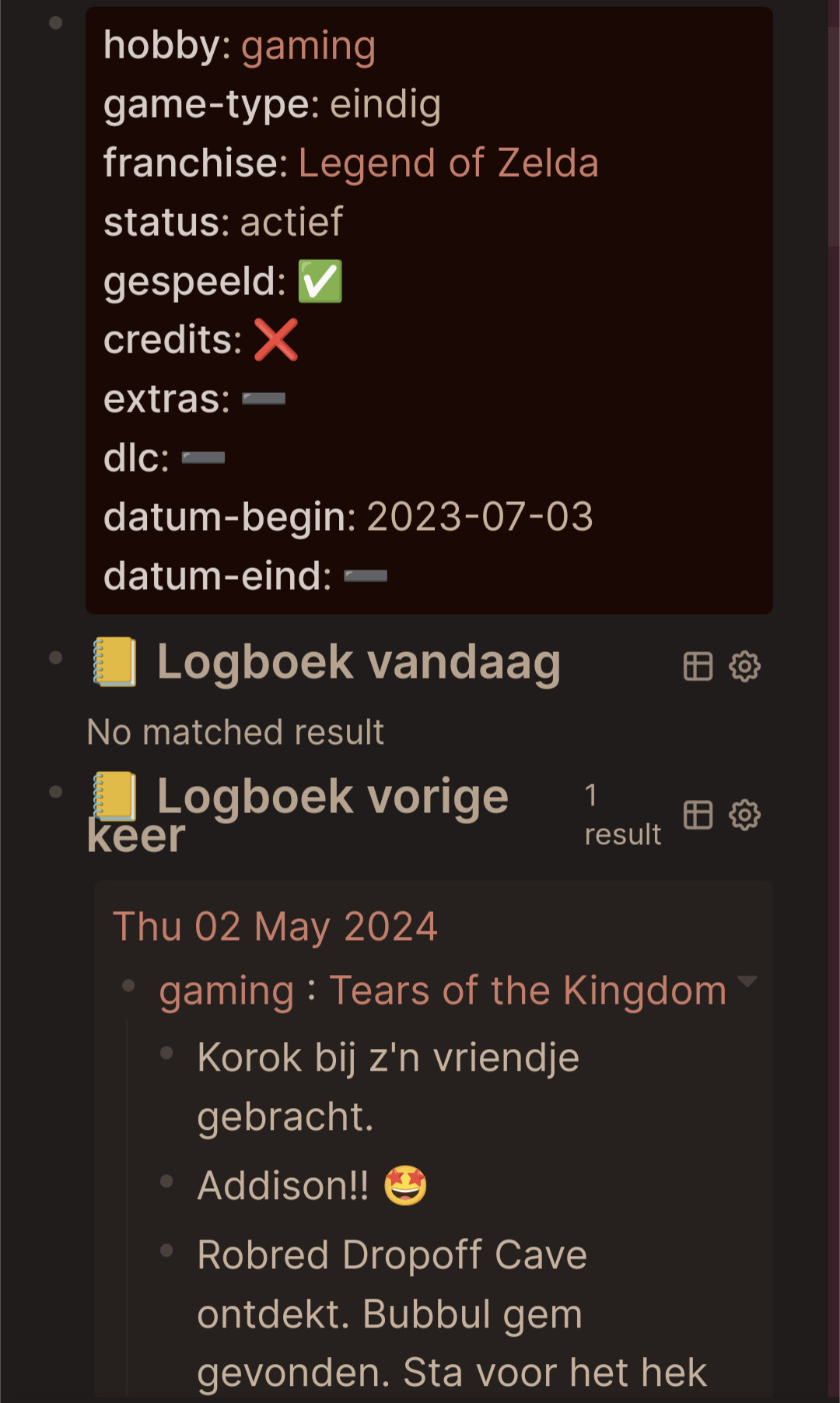
Next I’ll show a bit from my Tears of the Kingdom page (sorry if it is a spoiler, I don’t think so necessarily? Also don’t worry about my obsession with Addison, I’m fine )
You can see how I use my journal entries, which I gather with the query “Logboek”… and some of the notes I actually keep on the page.
So it is a matter of information that is time bound (journal) and information that is more general/timeless (page itself)
This is how I’ve come to divide most of my data. That which matters to a point in time (journal), that which is more general (topic/concept page)
PS. Most of my notes start in the journal and later I’ll move them to a better place if so needed. I make sure each top level block has at least a reference to some page for future recovery.
Wow, i honestly had no idea people are using that many graphs…
To me, the main feature of Logseq is that I don’t have to think where to put anything. I just write in the journal, and tag it. I use it almost as a paper notebook, so there’s private and work stuff, notes about people I met, ideas, research… and I never clean it up
So it looks super messy, but through tagging (this i do consistently!) I can easily find the relevant information, and crucially: it stops me from procrastinating with (folder/graph/etc) structures.
I think the implication is more that it may not work forever.
I have found that even though I tag stuff consistently (same tags, for same things, with same conventions etc), having things be just in the journal starts to become a limitation when one tries to retrieve it later.
I found that searching through linked reference isn’t ideal in most cases.
So for topics outside of actual journaling (or mind therapy I suppose :D) I will move blocks to pages when gathering, organizing and retrieving information. To make sense of it etc. To spare my future self the effort of having to do so again.
There’s something to be said about either
immediately organizing something and trying to make the perfect system
or, never organizing at all
It isn’t either the first or the last. There’s a whole spectrum in between.
I believe that just saying “whatever works for you” is short sighted. It forgets that people will not yet know what works for them in most situations. It also forgets that future you will exist and will need to also get something out of the system.
While we cannot predict the future, we can consider what might be convenient to have at the time of it’s arrival.
It’s a nice sense to have though
I think there is a false conception of popping up at all.
Unless we actively dig through our graph, (whatever shape that takes, linked references, queries, searches) information will not “pop up” at all. Let alone when needed.
I think this is the hardest part of finding a system. Some middle ground between what works for now and what works for later.
We can get lost in over-organization for later, which costs us time and effort now that may not be well spend. Future us may not be at all happy with what past us came up with. (I run into this continuously)
However not doing any organization at all will also hinder future us, even though present us may be very capable of dealing with the current small set of data.
Hi Siferiax,
I’m still quite new to Logseq. I also use it to track games, but it’s quite chaotic at the moment.
Your system seems to be great.
I would be interested in the queries.
Could you perhaps share the two pages from the screenshots as files? Possibly also a file from the journal as you use it there.
- [[gaming]] : [[Tears of the Kingdom]]
- Korok bij z'n vriendje gebracht.
- Addison!! 🤩
- Robred Dropoff Cave ontdekt. Bubbul gem gevonden. Sta voor het hek met erachter de treasure...