As someone who values the simplicity and organic flow of traditional outliners, I’ve found Logseq’s approach to be increasingly counterintuitive to the core strengths of an outliner over the years. While Logseq is undoubtedly powerful, especially for power users, it introduces a degree of rigidity and complexity that feels at odds with what outliners should provide—simplicity and the ability to organically structure information.
I’ve been using Logseq for over three years when Logseq was still in early alpha, and since that time, I’ve been an avid user. However, when I raised concerns about the decentralized structure in the DB Alpha feedback group, I was told by some community members to simply look elsewhere for other tools. This was surprising given my long-term investment in Logseq. It seems like the community focus has shifted more towards catering to advanced users, which doesn’t leave much room for those of us who want a simpler, more outliner-centric experience. With that said, I have been migrating my data for several months now, but with 3+ years of data it will take some time. I still think this is warranted to raise these concerns as I am sure there are other users who are feeling this pain and I do believe this would open the door to more users who would love to use Logseq.
Decentralized Page References Fragment Structure
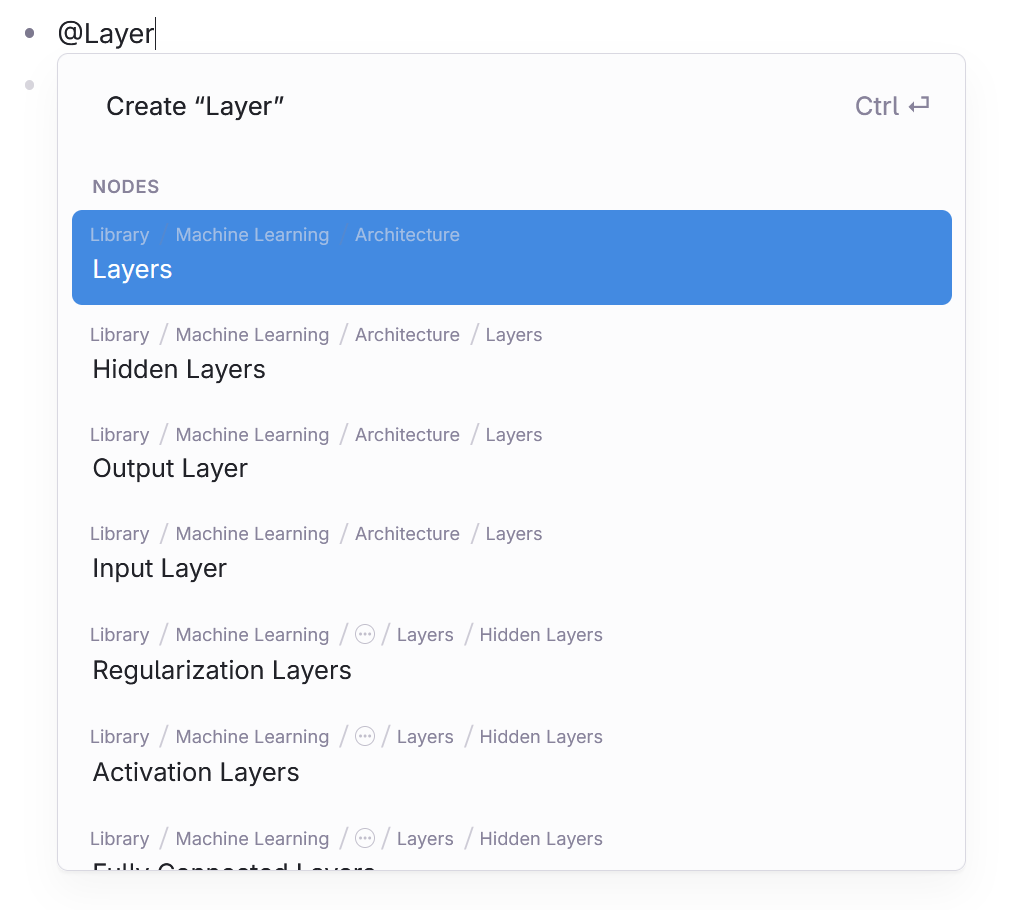
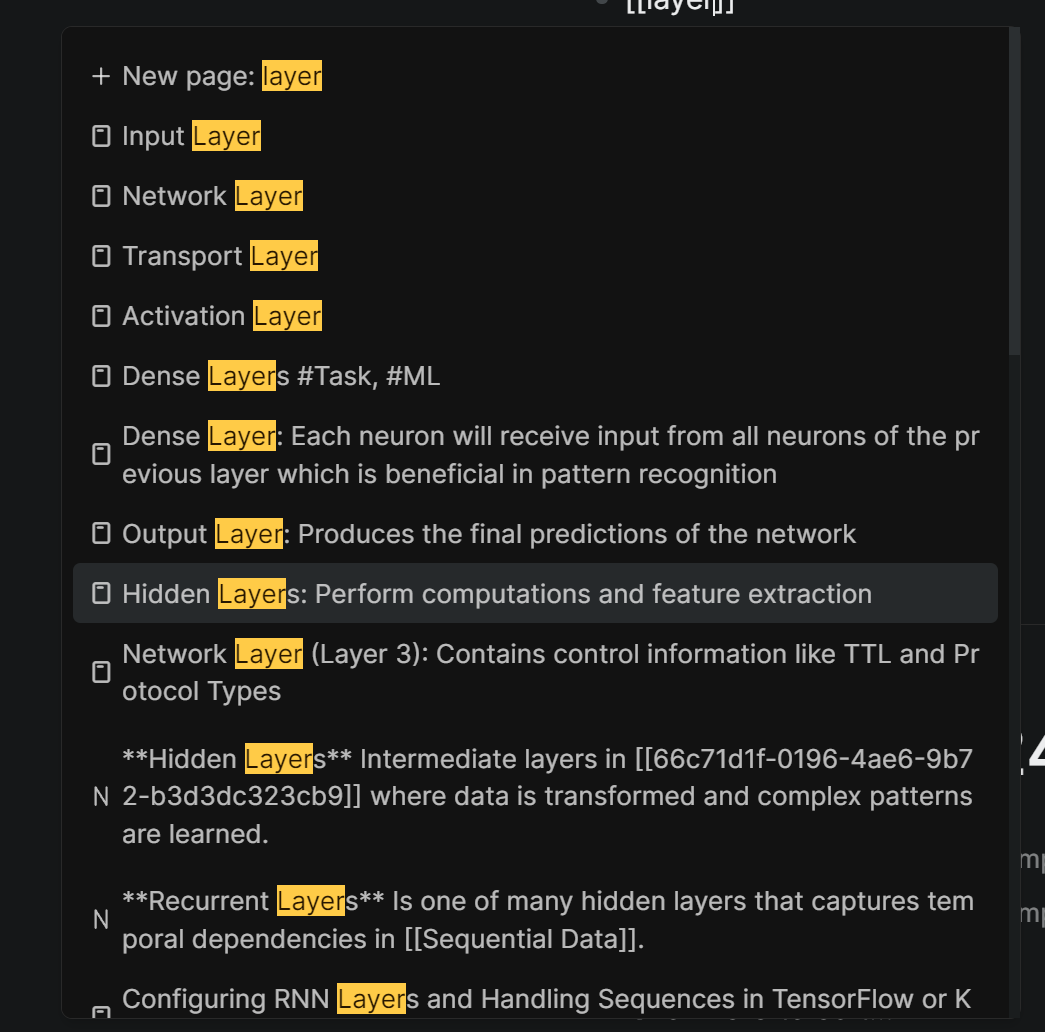
Logseq’s reliance on Page References allows for a decentralized structure, but this creates its own set of challenges. Since Page References can be scattered across the graph, it becomes difficult to form a coherent, centralized structure. In a traditional outliner, everything naturally fits into a clear hierarchy, where relationships between ideas and concepts are immediately visible and easy to follow.
With Logseq, this decentralized model leads to fragmentation. There’s no single, unified place to see how all your references fit together, making it hard to navigate and understand the larger structure of your knowledge base. This is a sharp contrast to other tools like RemNote/Tana or Obsidian, where there is either a built-in hierarchy or a filesystem to fall back on for clear organization. Without a clear way to manage this fragmentation, it can feel like you’re constantly chasing scattered references instead of building a unified system.
Properties Introduce a Rigid Structure
Logseq’s properties are great for adding metadata to blocks, but they bring with them a rigid structure that can weigh down the simplicity of outlining. Outliners are supposed to let users evolve their thoughts organically, with structure naturally emerging through nested relationships. Properties, on the other hand, lock users into predefined fields like tags, statuses, or dates, which require constant management.
Instead of letting the structure emerge as you build, properties force you to think about how to categorize everything upfront. This rigidity adds friction to what should be an effortless process. You can’t just outline your thoughts—you now need to think about how to structure the data through metadata fields, and that’s not the natural flow most users expect from an outliner.
The Focus on Power Users
One of the things I’ve noticed is that Logseq is increasingly catering to power users who rely on advanced features like properties. While these features are undeniably useful in certain contexts, they introduce a rigid system that often demands upfront planning and a more structured approach to organizing information.
This shift is especially evident in the DB version, which places even more emphasis on the use of properties compared to the file graph version. For users who prefer a more organic and fluid outlining experience, this growing focus on properties and structured systems can feel restrictive. After three years of using Logseq, I’ve found it increasingly difficult to maintain the simplicity and flexibility that originally drew me to the tool.
It seems like the development direction is moving toward supporting advanced workflows, leaving users who value Logseq for its outliner capabilities feeling somewhat alienated. The outliner simplicity—where ideas could naturally evolve and structure themselves—now feels overshadowed by the need to manage and plan around structured properties and metadata.
Visual and Conceptual Rigidness
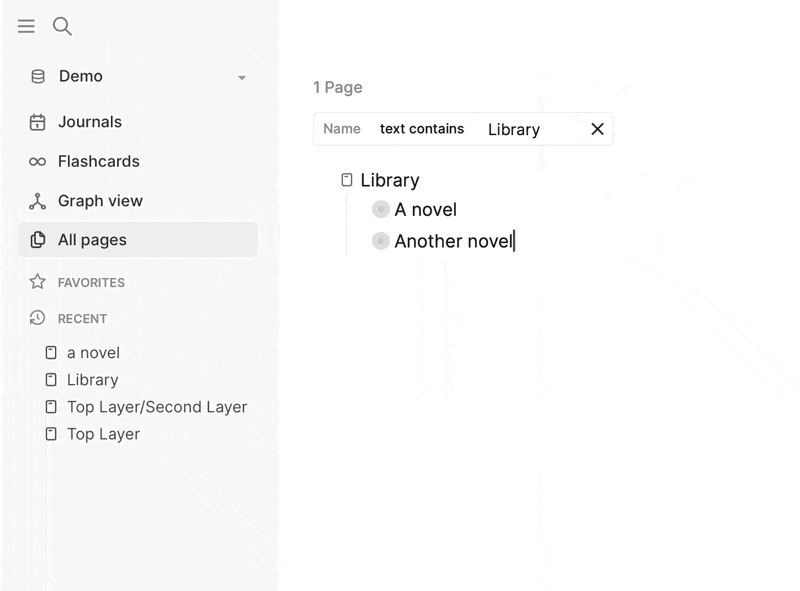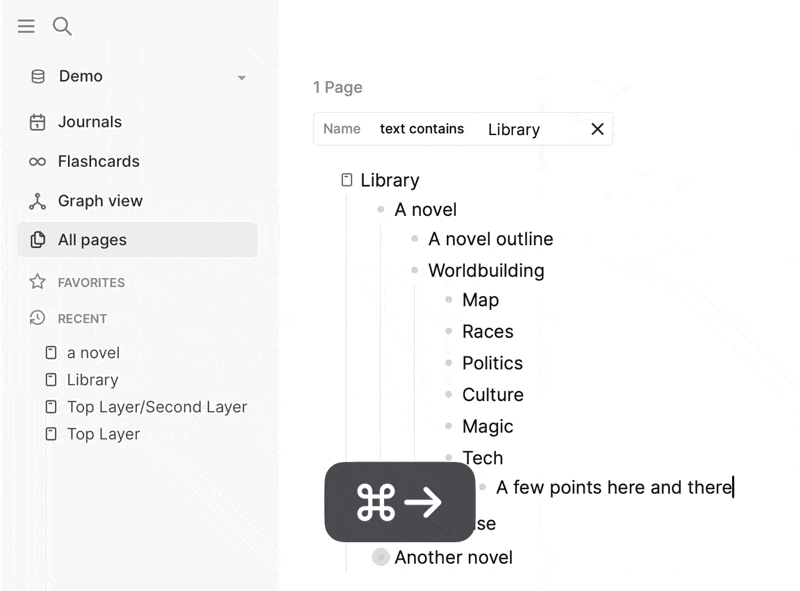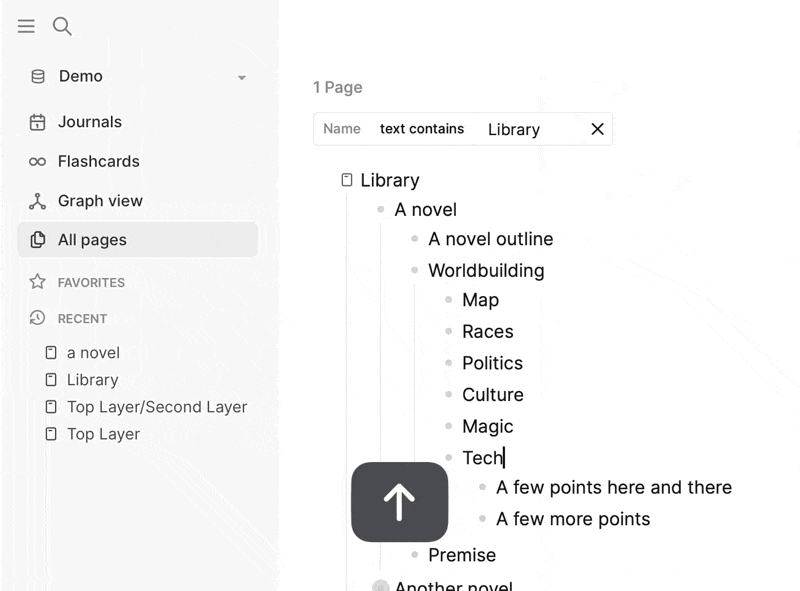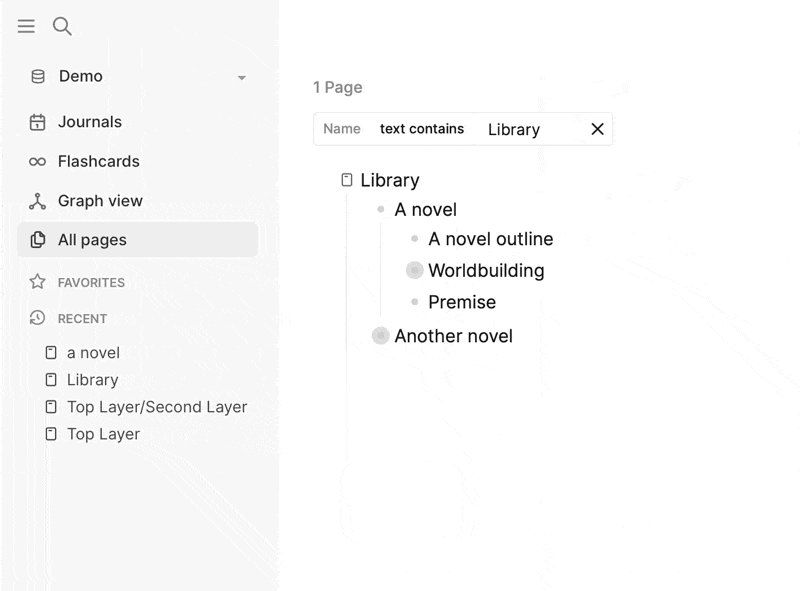
Logseq’s graph-based approach introduces visual and conceptual rigidness. In other tools, like RemNote or Obsidian, there is a more obvious visual hierarchy—a centralized space where users can easily organize their ideas. In contrast, Logseq’s graph model makes it harder to see how everything fits together at a glance. You can link blocks and pages, but without a centralized structure, it can feel disjointed.
In a traditional outliner, your visual hierarchy is clear: you nest items, move them around, and everything stays organized visually. In Logseq, you have to jump between references, pages, and queries to pull everything together, which makes it harder to see how your ideas fit into a larger whole. This rigid approach is especially problematic for users who are accustomed to seeing their thoughts and ideas clearly organized in one place, without needing to rely on graph views or complex queries.