Hi everybody,
As I have been experimenting with Logseq for the last two months, I am trying to come up with a strategy to organize information. More specifically, I am trying to implement a tag management system without implementing namespaces that expert users recommend against.
My approach is to develop a personal “PKM Schema” to implement the equivalent of a Network Model in database systems. I am trying to accomplish that by using a nesting structure to organize my tags. See example in the following screenshot:
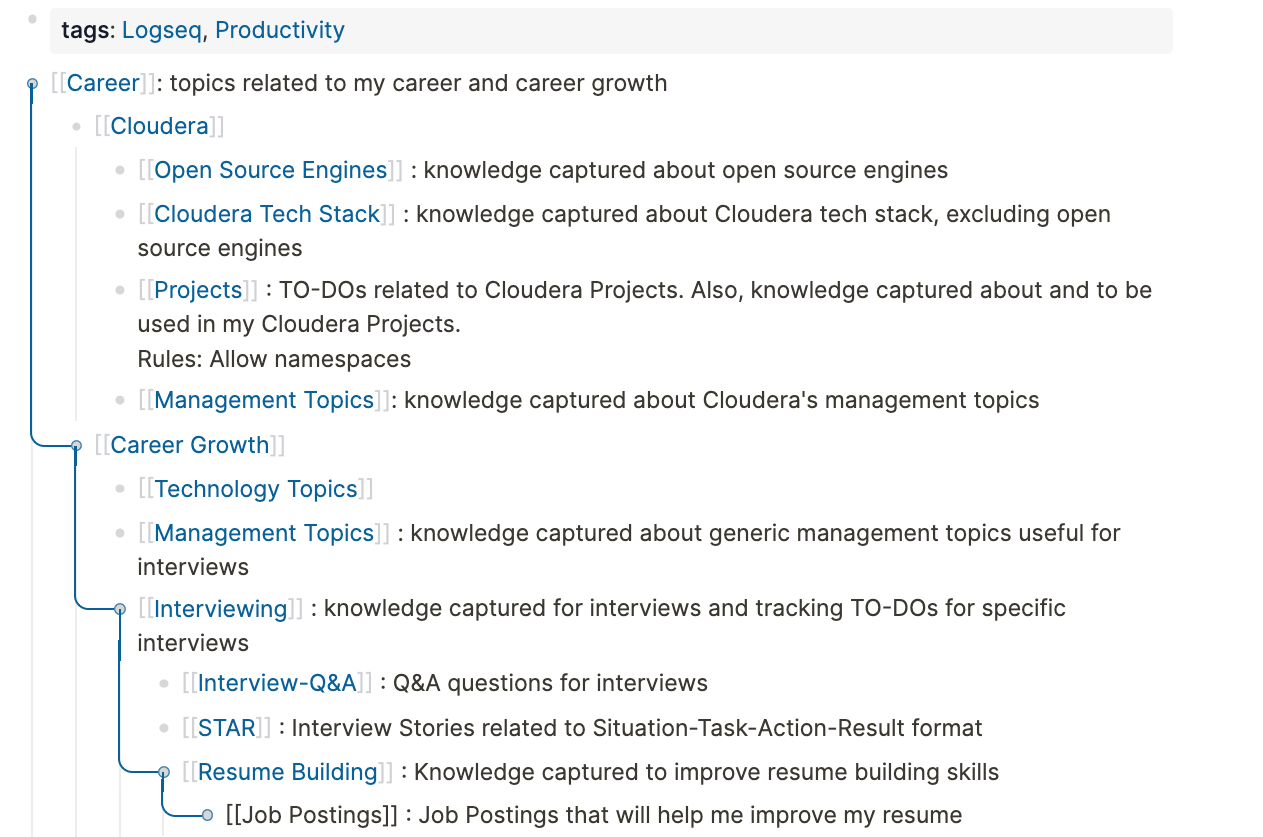
Even though my PKM schema is not fully mature as of yet, my strategy is to have Level 0 (e.g., [[Career]]) and Level 1 (e.g., [[my-current-employer]]) as broad thematic categories that correspond to a specific but broad aspect of my life (I call them “Life Blocks” and my rule for defining them is that they are relatively continuous time-wise and not time-bounded such as a project). Then, levels 2 through “N” can be a) more specific knowledge domains that may or may not similar across Level 0 and Level 1 tags or b) projects and time-bounded activities of narrower scope (e.g., prepare presentation for “x” audience)
A system like that would rely heavily on a robust property management system for each tag.
With regards to that, I am also building a strategy for properties of items organized using my PKM schema. As an example, see below information captured for an item called [[Apache Ozone]], an [[Open Source Engine]] that falls under [[Cloudera]] which falls under [[Career]]

My question for anybody that has built anything similar to the above is, how can I create a query that returns a list of all Level-2 items (e.g., all [[Open Source Engines]]) that fall under a Level-1 and Level-0 tag (e.g., [[Cloudera]] which falls under [[Career]]), in a way that will allow me to index the database I am building using my PKM schema.
Thanks in advance!
Best,
Andreas