When graphs can talk
For having a visual graph communicate something to us, we should consider its signal and noise:
- Each connection between nodes:
- carries some signal
- adds noise to the nearby connections
- That makes a graph (or subgraph) with:
- too few connections: silent, has nothing to say
- too many connections: noisy, has nothing meaningful to say
- As a (simplified) consequence, graphs (or subgraphs):
- that look like stars (or stars of stars), are neat but silent
- where everything connects with everything else, are noisy
- that combine the above, combine silence with noise
- that balance their connections, may communicate something
- To improve the situation:
- look for nodes that are:
- underconnected:
- have less than 2 connections
- they should either:
- acquire more connections
- be merged into other pages
- they should either:
- have less than 2 connections
- overconnected:
- have more than 8 connections
- they should remove some connections by either:
- delegating them to the remaining ones
- breaking into smaller pages
- they should remove some connections by either:
- bridge things that are directly connected to each-other
- this adds noise
- decide which are the direct connections and remove the indirect ones
- have more than 8 connections
- underconnected:
- use the following soft rule to add missing connections or even nodes:
- if node A has:
- a connection of type R with node B
- a connection of type S with node C
- and R is orthogonal to S
- then some node D has:
- a connection of type S with node B
- a connection of type R with node C
- if node A has:
- look for nodes that are:
Structure matters
The streets on a map originate from either:
- animals (e.g. in an old forest)
- they connect points of interest (water etc.)
- engineers (e.g. in a modern city)
- they essentially connect doors
They both are useful in going from one point to another.
- If I structure a graph as:
- an index, it will be easier to find the inserted info
- think of multiple doors in parallel corridors
- a hierarchy, it will be easier to navigate that hierarchy
- think of narrow streets connecting to larger ones, to avenues, to highways
- an index, it will be easier to find the inserted info
- Structures like the above, give me back exactly what I put in.
- This is great for returning to a place.
- If I let a graph structure itself, it may give me back more, both:
- from its structure
- think of ants’ tracks
- from its lack of structure
- It is a comparison between expectations and the actual graph.
- Whenever the expectations fail and they are:
- right, it is a chance to fix the graph
- wrong, it is a chance to learn something
- Whenever the expectations fail and they are:
- It is a comparison between expectations and the actual graph.
- from its structure
A simplified example
- Consider a single journal-note:
[[Purchase]] of [[apples]] by [[my neighbor]].
- Here are some easy questions I could ask, related to that note:
- What did my neighbor purchase?
- Who did purchase apples?
- What happened between apples and my neighbor?
- Here is a less easy question I could ask:
- What are the transactions between persons and fruits?
- To answer that, some extra knowledge is needed:
- my neighbor is a person
- an apple is a fruit
- a purchase is a transaction
- But I still query for pre-existing notes:
- I entered some transactions in the past.
- I query for those transactions in the present.
- This is the traditional boring approach.
- Now consider a graph that contains no transactions at all.
- This is not a necessity, but helps with focus.
- Then consider the following hard question:
- What could my neighbor be involved in?
- And here is a desired answer:
- My neighbor could purchase apples.
- The desired answer doesn’t exist in any individual note.
- I query for possible transactions in the present.
- I may enter those transactions in the future.
- I may find that some have already happened in the past, but I missed them.
- To provide such an answer, even more knowledge is needed:
- a person is an agent
- a fruit is an object
- a transaction involves an agent and an object
- this is the type of knowledge that can lead to discoveries
- One could try working this answer by combining the previous knowledge:
- my neighbor is a person, therefore an agent
- apple is a fruit, therefore an object
- a purchase is a transaction, therefore involves an agent and an object
- Datalog anyone?
- Alternatively, one could work this answer by following connections in a well-made graph:
- There is a path from my neighbor to purchase.
- There is a path from purchase to apple.
- Nobody constructed those paths on purpose, they emerged.
- In a noisy graph, they remain invisible.
A simple visual example
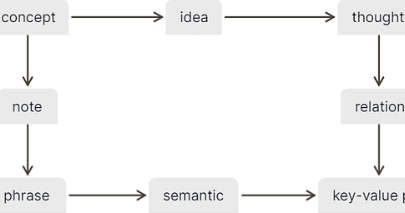
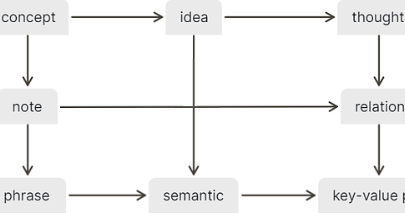
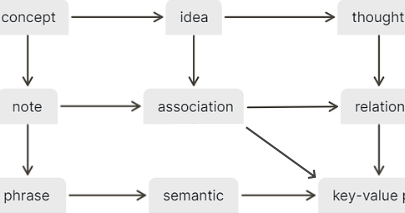
- Visit A whiteboard for the main concepts in Logseq
- Imagine any of the nodes missing, either:
- along with its connections to its neighbors:
- with its neighbors connected directly:
- even if the remaining nodes have issues
- e.g.
associationinstead ofrelation
- e.g.
- along with its connections to its neighbors:
- Or imagine a mistaken connection:
- Wouldn’t it be easy to visually detect any of those issues?
- This is possible because of the emerged pattern.
- Is everything that easy?
- Not at all, but you have one more tool, if you want to use it.
Short points to keep
- The right tool for the job:
- Journals are for events.
- Other pages are for knowledge.
- It is not “one or the other”, both can co-exist.
- Graphs don’t benefit from journals, but from interlinked pages.
- Tagged journals generate stars.
- We typically hide those.
- Interlinked pages generate paths.
- Excessive noise makes paths invisible.
- Therefore, graphs don’t benefit from stars, but from visible paths.
- Tagged journals generate stars.
- Failed expectations can be:
- opportunities
- pleasant surprises