In our development shop, you are not allowed to call software beta if it corrupts data or loses data. Logseq Sync both corrupts data and loses data. This service is alpha at best.
I ran across another significant data loss defect so I downgraded to 0.9.19. I’m currently studying for a certification exam so I don’t have time to fix all the corruption and watch out for data loss so I turned off Logseq Sync for two days.
I use Git on my laptop as well and sync that to Github so that was my backup strategy while Logseq Sync was turned back on. Once I was ready to turn Sync back on, I tagged my Git repo so I could always get back to what it was prior, ya know, just in case.
The only edits to my graph were on my laptop where Sync was turned off. I stopped using my other devices while Sync was off. So if working properly, Sync shouldn’t have made any changes to my local graph.
(narrator: it totally did make changes to my local graph).
I turned Sync on and then went back to see what Sync did to my graph by doing a git diff. Logseq Sync corrupted ~200 files on my local graph.
Mostly, what it did was on H1 blocks and property blocks, it added back in old values of those blocks. All over my graph. Including pages that I didn’t update in the last 3 days. So now I have hundreds of pages with corrupted property blocks and old blocks that have long since been edited.
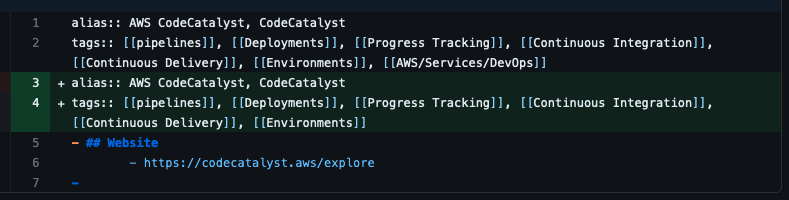
At what point is the Logseq team going to take data stewardship seriously? This whole application and sync service feels like cowboy coding. For the life of me, I can’t imagine any worthwhile CI/CD automated test suite wouldn’t catch some really straight forward defects like this.
I have zero confidence in this application right now. I’m going to stay on 0.9.19 for the foreseeable future. And I’m going to stop donating to Logseq. They were funded with a multi-million dollar seed round. They can spend some of that money and hire some people who can actually implement a robust quality strategy.
Sorry, I’m super salty. I’m seriously invested in Logseq and I’m now realizing what a mistake that was.