Upvoted that one too. Thanks for not taking it personally!
My intention was to direct or summarize this post to make clearer requests, as I observed the messages we’re trying to communicate are not fully consistent, for example the following messages have intersections but don’t fully align:
- logseq should direct more resources from “feature projects” to bug-fixing and “enhancement projects”
- losgeq isn’t working on the top FRs here (implying they should) ( — but many of them are features)
To be clear, I think things like EPUB annotation are valid requests, but in the context of this thread bringing up “Top FR” muddies water a bit. “Message 1” is closer to the core of this thread so I emphasized that.
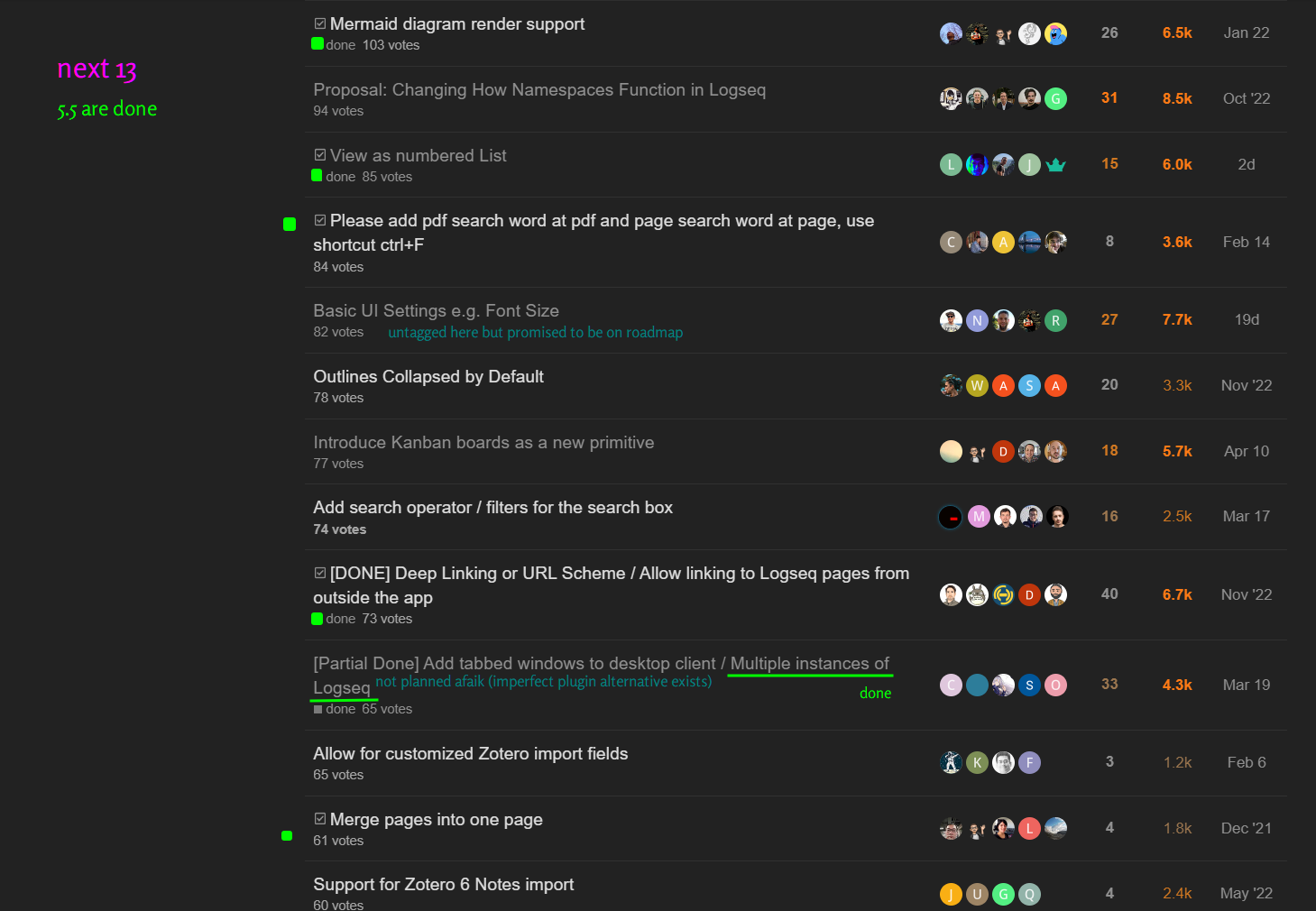
Another example is this message from View as numbered List - #16 by Joe_Smoe
So I have a question, why would the team focus on implementing this, but not something like Prompt user to confirm deleting block when an existing block reference is linked to the block - #6 by tobid ?, which I think would be a higher priority.
- For one, it’s an example against “Message 2” because numbered list is a highly-voted community request.
- Secondly, this mesage implies FR should not be taken according to votes but according to how much it would improve user experience. (Numbered list has 85 votes, the other has 28.)
This aligns with “Message 1” and my personal opinion.
@Junyi_Du Thank you for being so active in this thread, though I don’t think the core question has been addressed yet. Rather than questioning the amount of bug-fixing the team had been doing (we all appreciate your hard work!), I believe OP and many were asking why some of the bandwidth that could’ve been spent on bug-fixing were used on “feature projects” instead.
In my previous post I outlined the past priorities I could understand, but I left out numbered list, because I could not justify it given the unstable current state of logseq that some resources went into that instead of fixing more bugs, especially because
- I don’t think it should take precedence over “parser replacement or improvement” which is on the table and would solve the number list problem in a much better way.
- There already is an excellent plugin; and the official implementation is also visual-only so it isn’t better than the plugin (except it works on mobile, but mobile plugin is also on the roadmap — no?)
So rather than asking us if we have advice on making issue management more efficient or direct, you need to address how you would make more strategic decisions on resources allocation.
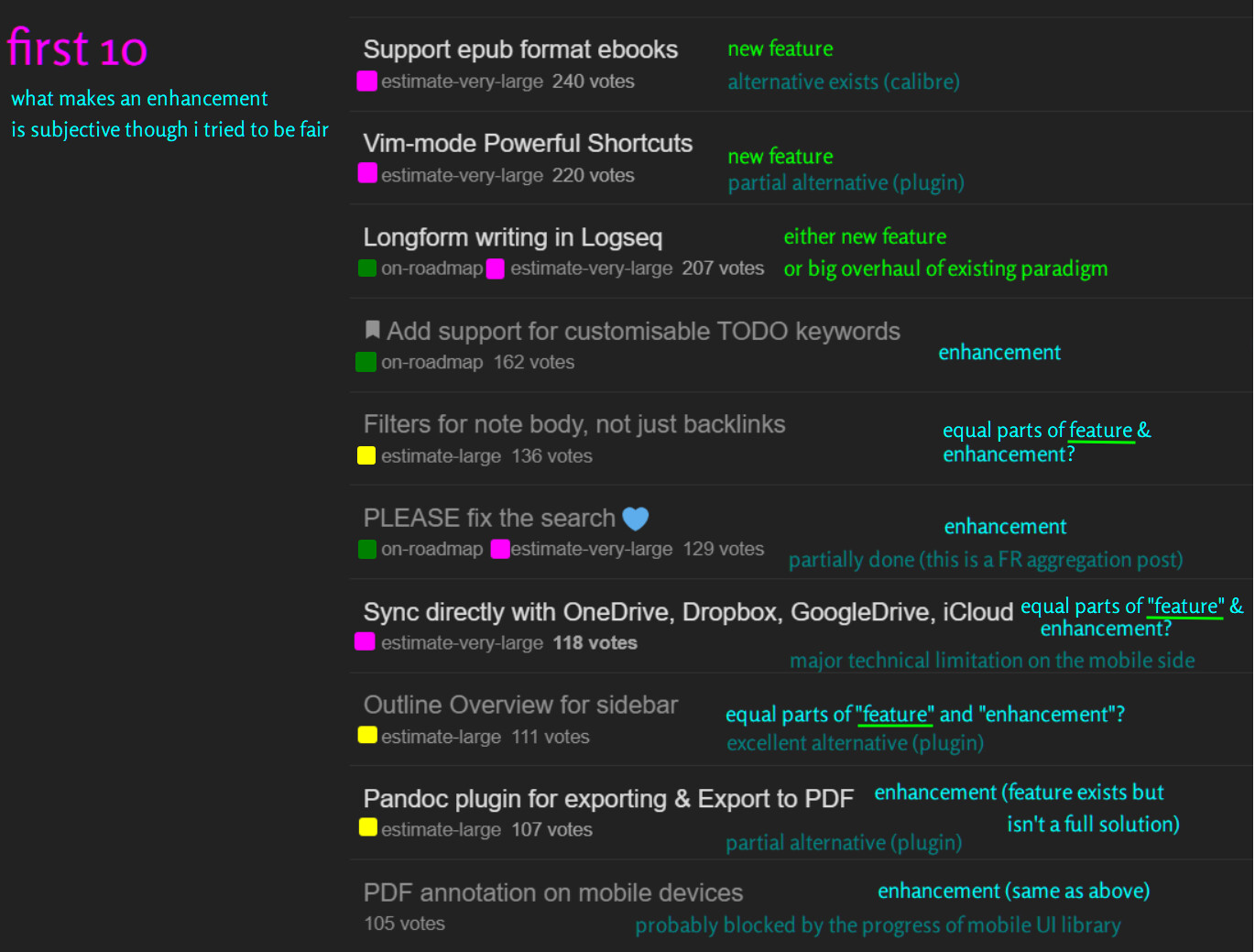
I wanted to show “the pace of enhancement implementation stagnated” is subjective so we do not get into more discussion on that and go off-topic if the team also focused on answering that instead of the main question.
Likewise, while “top requests are not being worked on” is mostly right, I worried someone would extend that to mean “developers are not addressing the FR section as a whole” which is imprecise, especially not for the “non-top but with decent votes” requests.
Here let me speak for the team a little bit so that they don’t do it themselves and make this thread go off-tangent:
If the first 10 requests are taken out, we start to see “done” requests sprinkled in, so devs have been addressing them, though not in the order or at the pace everyone desires.
For most of the unsolved “Top 10”, I could venture a guess why it’s not given a higher priority, so to me it’s not too unfair.