I didn’t know about Tana and its supertags, but I started testing Anytype even before Logseq and I liked the concept of “types”. Turns out, it’s also usable in Logseq.
You just have to use templates with properties. It’s easy, convenient enough and very flexible.
For example, let’s say I want to keep track of songs I want to learn.
1. Creating a template = defining a type
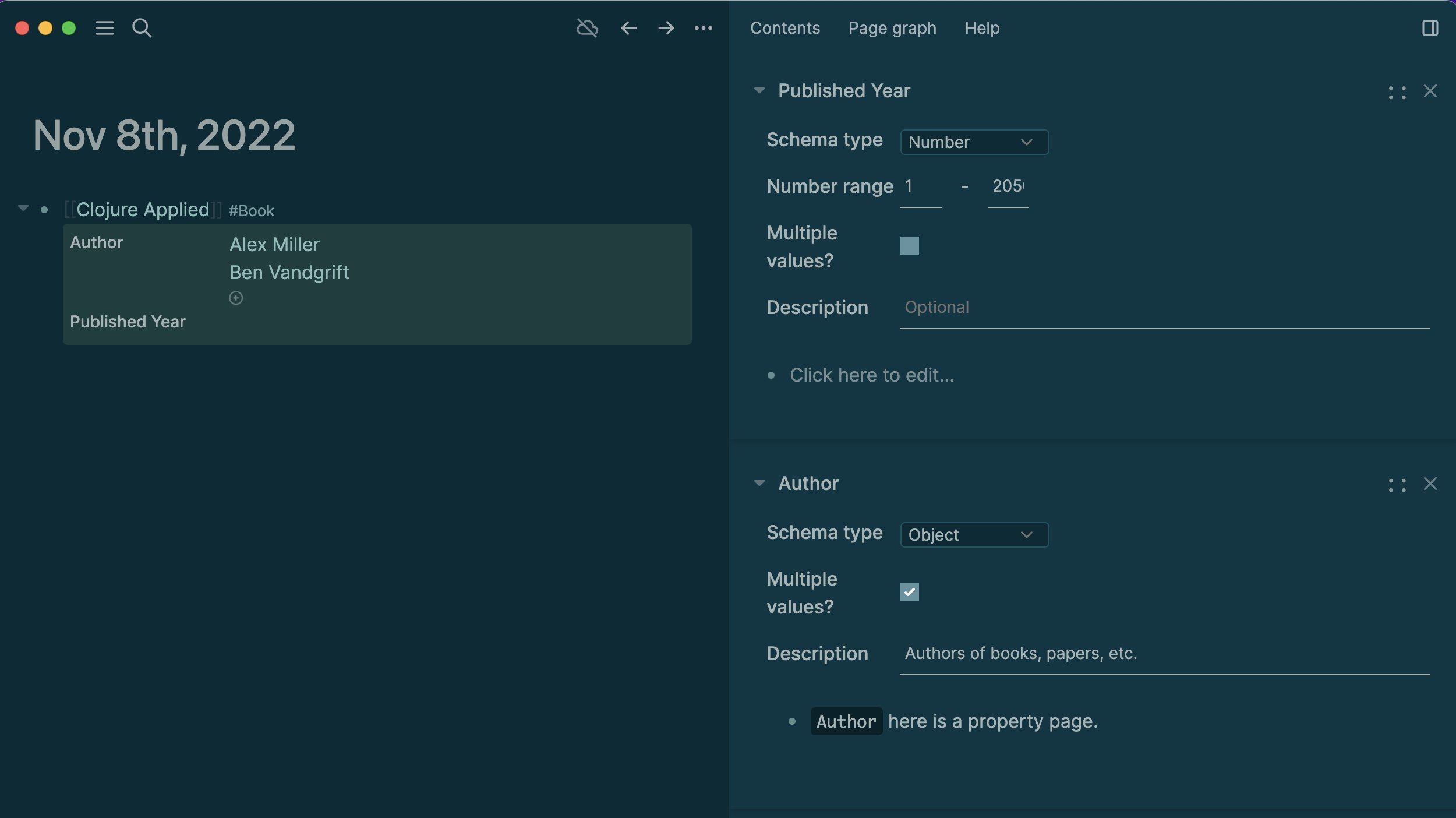
Here I’m creating a template for a type called “canción” (song). The key is the “type::” property, but at the same time I’m defining any other property I intend to use for that type. For example, I want to record the “state” (pending to learn), a relevant URL, author(s), etc.

I could add not only properties, but also any sub-blocks in here, like a section for lyrics and tabs, a notes section… just anything I wanted.
2. Invoking a template = creating an object of a certain type
Here I’m creating a new song, which is a block using the “canción” template. Some properties are already filled (like the “type” property") and others can be filled in that moment and will be specific to that object.

As you can see, I’m referencing an existing block/object (El Viaje de Chihiro = Spirited Away) which has a different type (película = film).
3. Creating a query = creating a set with all objects of a certain type
Here I’m creating the equivalent of Anytypes’ sets, and more speciffically a set of songs filtered by “pending” to learn.
I’m also switching the query to table format, making this effectively an “inline set” anywhere I want, a feature that hasn’t even been added to Anytype yet.

Here you can see a much more detailed explanation on how to use templates as “types”.
Big caveat: You can edit a template at any point and new objects will be created with the updated template, but the existing objects or instances won’t update. When I edit a template, I make sure to look into the “set” (query) and quickly update previous objects (blocks or pages) of that type. Not ideal if you have many of them, but good enough for now.
Big advantage: As you can see, you can assign several “types” to an object, which is much more flexible than Tana’s and Anytype’s implementations. For example, something can be a “website”, a “reference”, a “resource” and a “tool”, or a “meeting” and an “assembly”. It just comes down to what #tags you use in the type:: property.
This is nowhere near the UI and functionality of Tana’s supertags, but it’s close enough for me and VERY flexible. And it’s working in a more powerful way than Anytype does right now (allowing for inline sets, for example).