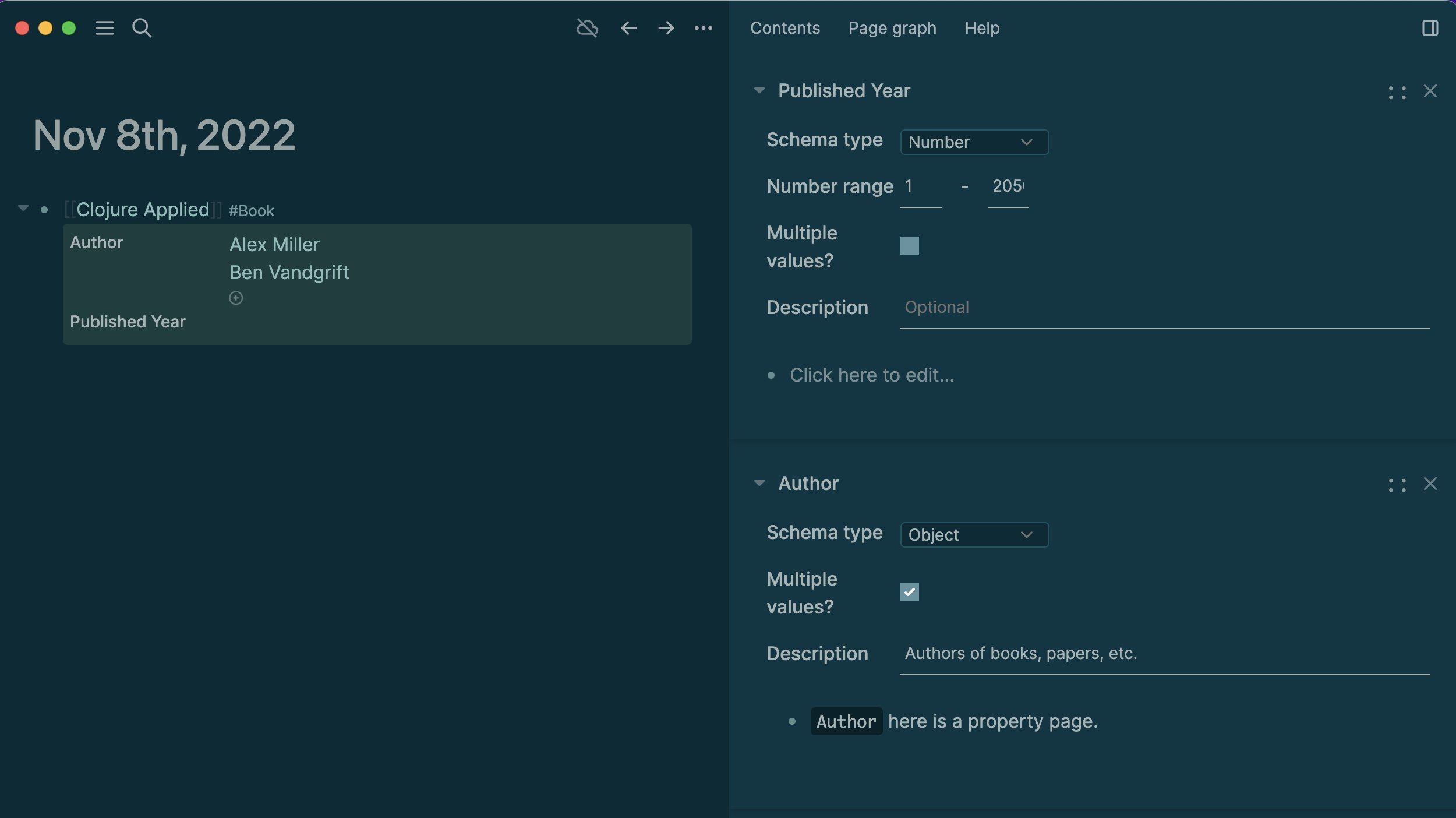
Yes, this may be in relation to Tienson’s tweet where he showed his Logseq, and showed some notes talking about a “Properties 2.0” and schemas. I think we can achieve supertags fairly easily with Logseq, and adopting different views should also be easy. I’ve already built a prototype for the table view Tana has. I need to finish completing the plugin so I can publish to the marketplace, but I have high hopes.

Also just noticed something, from tienson’s tweet (which is looking very promising) you can see how he’s showing off this new schema type of look: