I think we’ve been talking past each other. I agree with @alex0’s suggestion for adding tree and graph searches and for storing the information.
I did not think about designing hierarchies efficiently, which @boisjere’s program can do.
For now, I’d be happy to even design the hierarchy by hand in Markdown.
I was solely talking about efficiently classifying existing nodes. While theoretically this can be done on each individual page, it is too cumbersome to classify hundreds or many thousands of nodes this way.
What I would like to see is this:
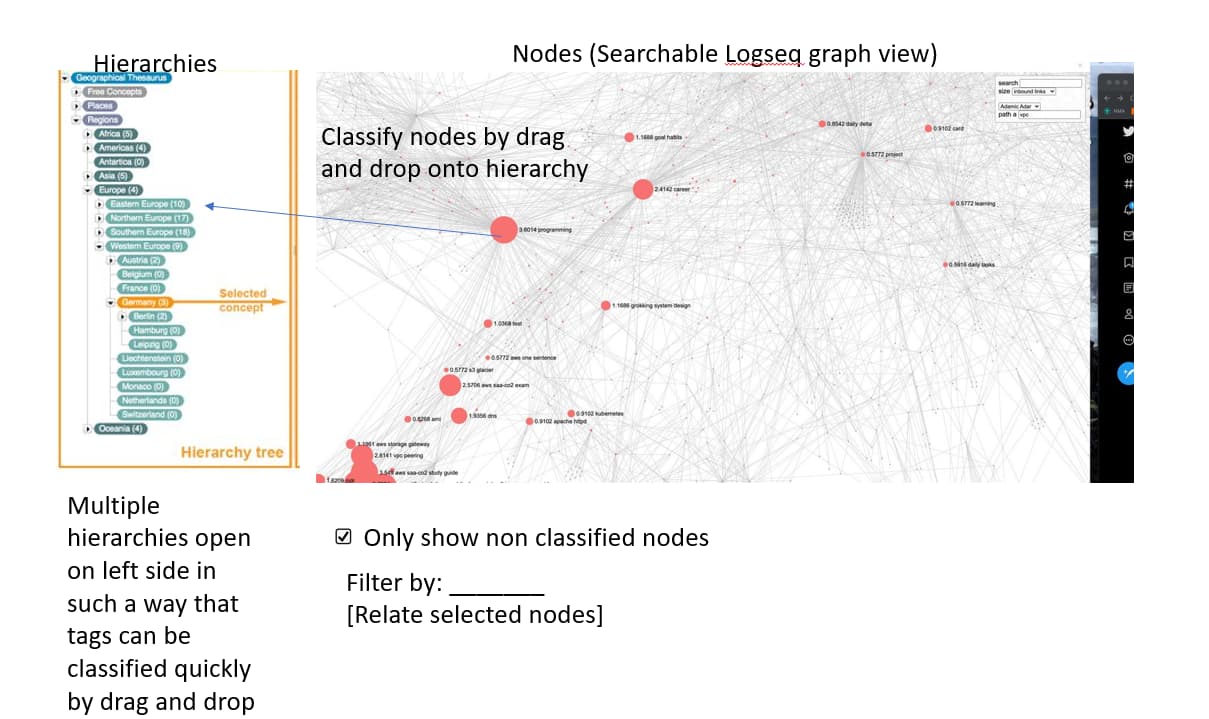
The process should be designed to be as efficient as possible, such that it is realistic to sort a few thousand yet unclassified tags into the hierarchy.