I am thinking, @alex0, that perhaps we agree on substance, but I used “hierarchy in an ambiguous way”. Thank you for your more focused description. When you wrote:
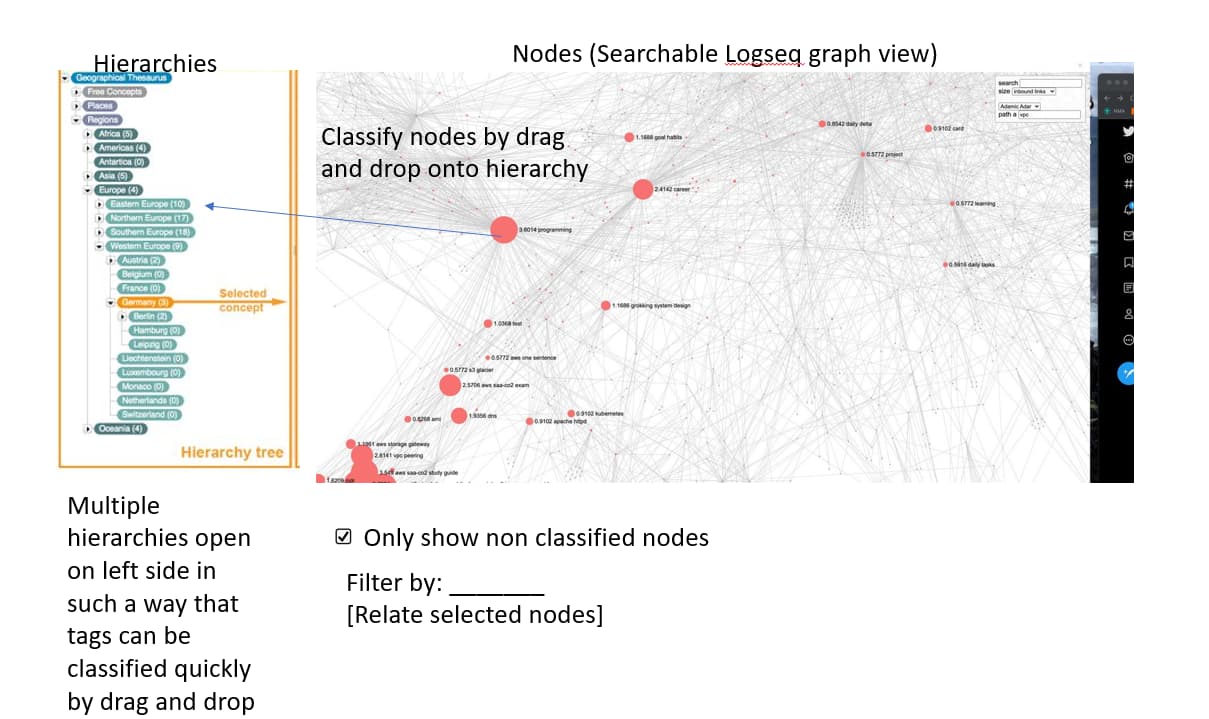
you can browse them maybe interactively with “virtual” hierarchies
That is what I want. A good UX, layered over what you describe as a database approach is great! What matters is the experience of browsing a tree, as way of traversing a subset of your graph, above the level of the page.
Conveniently, a tree = an outline, in terms of UX. Logseq already does the UX right.
In terms of UX, I wish I could edit “All pages”, “Linked references” and “Unlinked references” exactly like a standard page, in outline form, with maybe a drop-down menu specifying the query:
- So one could be the current default or flat list in reverse chronological order
- One could be according to some taxonomy or classification scheme, plus a flat list for notes outside that scheme
- One could be by project, plus a flat list for notes outside that scheme
- And you could edit those pages like normal outlines, and turn them into saved search pages
I don’t need hierarchies to be stored objects necessarily. It will be better if they are saved queries that return outline-structured, editable, saveable results. It’s good because I’d want many notes to fall within the scope of more than one tree.
- In one of my examples above, the hierarchy shows a note for [[Topics/Sexuality/Sexual Power Dynamics]].
- That note is relevant to both [[Topics/Sexuality]] and [[Topics/Psychodynamics]] Topics.
- But the reason I’m exploring it is for the novel I’m working on: [[Journals/Project Logs/Candace Valleigh]].
- As a novelist, the fire in the story comes from deep inside my psyche, so I also need to ask hard, searching questions about that topic and why it is emerging in my heart as a topic relevant to this story, so I need to do personal journaling about it. I’ll want to open my personal journal and go to that topic to work on it, when I have reflections that relate to that topic.
In each of these locations, I want that note to appear in editable, collapsible outlines.
I can do this manually, or try my luck with Unlinked References, which I cannot currently edit as an outline in and of itself. This makes it a bit of a mess, taking too long to scan visually, so I ignore it.
As a non-technical user, I just want the experience to work. I want this tool to be useful for me and for the way I think. Since it’s in early stages of development, this is a chance to have input. Also, since what I want is editable outlines, and much of what Logseq does is present interrelated blocks in editable-outline form, this seems like a promising tool.
But I want this to be a tool, not a toy. As a non-technical user, if I have to tinker with it too much, it becomes a toy. I’d play with it for the sheer delight of dancing up the learning curve, and do my real work in Scrivener or something.
I’m currently using Scrivener as a massive database for teaching the history of psychology, but the search is too slow, and the foldering is a bit too rigid - even though labels help with lateral connections a bit. It’s really not optimized to be a long term environment for grooming and improving a web of knowledge, but I can be fast in it.
There’s no such thing as “just UX” for a non-technical user. I feel comfortable in Logseq, but some founders, like those building app.capacities.io, take UX pretty seriously, and it feels good to be respected like that, as a user, and not be told to construct something that looks like code. (I’m a bit technical, but prefer GUIs for most things).