Still mulling.
I think an actual faceted search is probably best implemented in a plugin. If the data model is there, then various kinds of facet search plugins can leverage it. It’s essentially a query GUI, isn’t it?
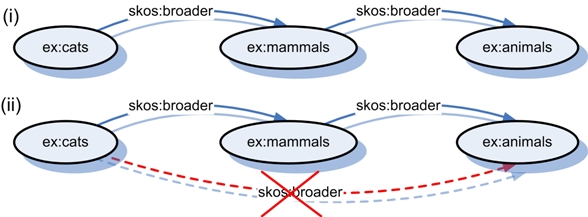
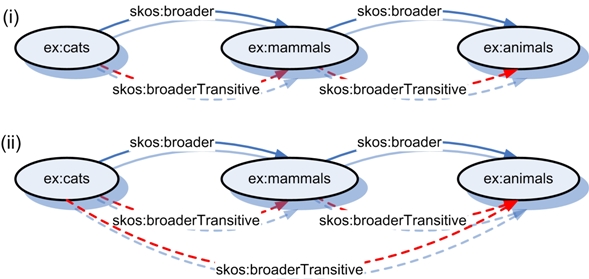
When I mentioned “facets” earlier in this conversation, I was actually referring to what gets covered off in SKOS as collections and concept schemes. Those can be used for analytico-synthetic post-coordinate classification like you find in Ranganathan’s Colon Classification or Bliss 2 classification. You can maintain a thesaurus, and implement some tag control that way.
I’m not sure that the idea of a single classification hierarchy like the Dewey Decimal system bothers me, because I don’t think classification in that sense is even possible in this type of environment.
The main issue with classification in a physical collection is that things need to only be in one place. In an index to that collection, or in a networked digital environment, they can appear in multiples places. An index isn’t polyhierarchical necessarily - it uses “see” and “see also” references to related concepts (skos:related) - but again that’s kind of vestigial from the fact that indexes have historically been created on paper. (One might say that “Unlinked References” is an evolution of these “related” index entries).
Feature Request 2: Hierarchy Page
I don’t know how hierarchies/namespaces are currently implemented under the hood. But my initial request, listed as Feature Request 2, is just the first bullet, more or less.
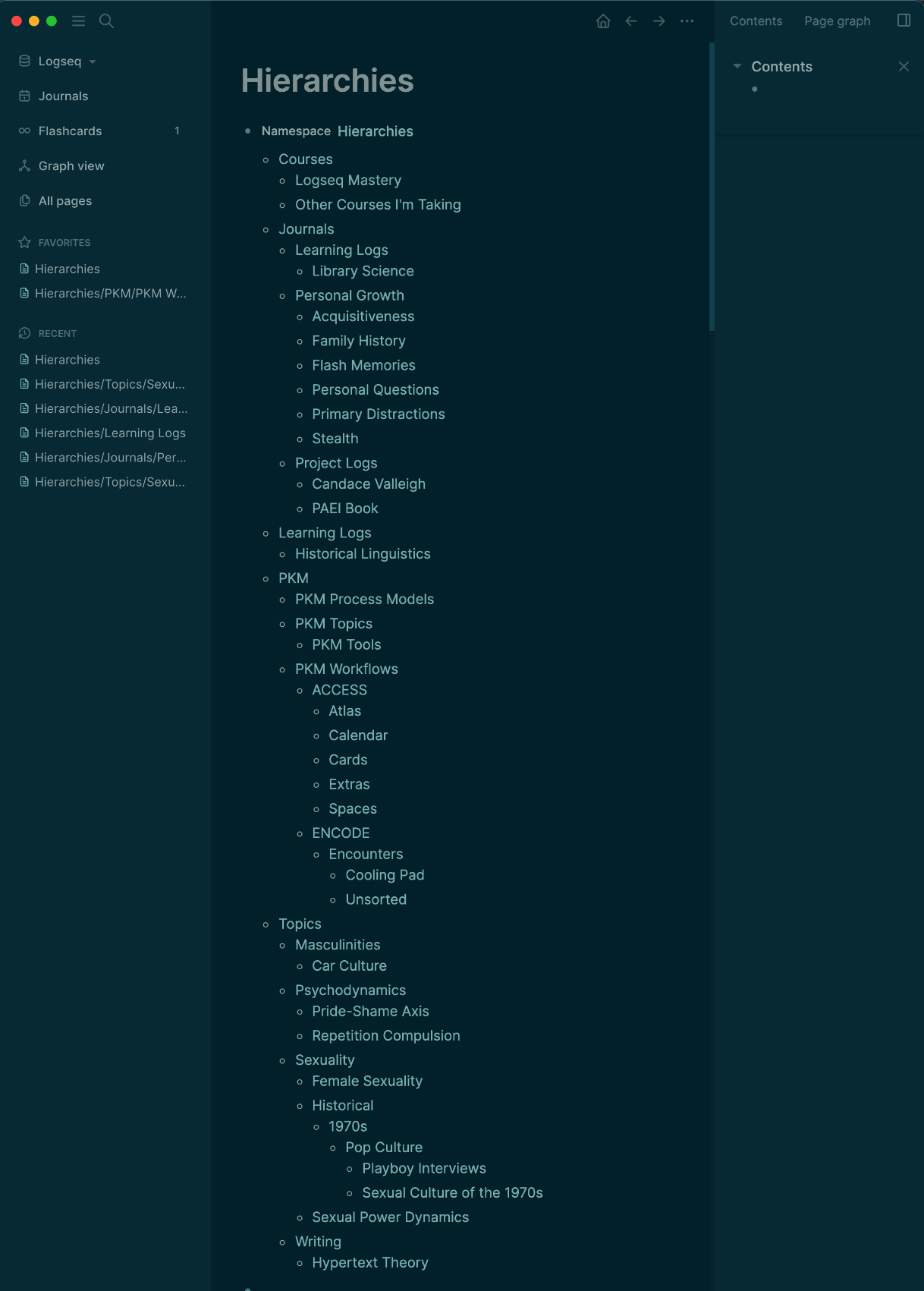
It’s agnostic to however namespaces are represented, and just asks for a quick link to an auto-generated list of them. It’s a lot like the “Hierarchy” link at the bottom of the page, except it lists all of them on a single page.
I can, in fact, hack this feature together now, more or less, by putting all pages that I’ve placed within hierarchical namespaces under a grandparent “Hierarchies” namespace, querying the namespace “Hierarchies” on the Hierarchies page, and favouriting it. It’s just not editable so I can’t make it into a “Master MOC” hub for my database.
I see this feature as a quick hit for the development team. It may not significantly derail their roadmap to squeeze it in. It would also be a clearly visible differentiator from Roam, if that’s important. For that reason, I’d pop it into the Feature Request forum as its own thing.
Feature Request 1: I Would Split it in Two
It seems to me that Feature Request can be unbundled a bit, split into two or three features. I’ll do it as two features.
FR 1.A: Polyhierarchies
Polyhierarchy is a distinctly different feature request. It could be implemented without there being an autocompiled list of all hierarchies, with a system link to it in the left sidebar (i.e. without Feature Request 2).
The “Hierarchy” section at the base of the page could simply be a “Hierarchies” section, and more than one hierarchy that intersects with that page could be listed there.
Now my ignorance is going to show here. Wouldn’t that mean that the place of a page in a hierarchy would have to be defined in a page property or page tag, as opposed to slashes in the title? I like deep trees and so the slashes in the title is a pain for me, so I’d be happy to do it differently.
I see references that indicate to me some other ways of defining namespaces in other places in this forums:
Anyhow, all that is to say that Polyhierarchies (having a page appear in multiple namespaces) can be implemented without having a sidebar link to an overview page, and vice versa.
I think it’s a different kind of feature request from Feature Reques 2, because it does touch how namespaces work, potentially.
I still think it’s a smaller feature request than implementing SKOS (provided Logseq isn’t architecturally similar to SKOS already).
FR 1.B: Vocabulary Control
Having a nested hierarchy of terms (broader, narrower, related) is different from having branching hierarchies of namespaces. In Ranganathan’s terms, it’s classification on the “conceptual plane” as opposed to the “physical plane” (I’ll treat digital notes as “things”, and so they’re analogous in some ways to objects - on the physical plane).
How are conceptual hierarchies different from hierarchies of things like notes? You can construct namespaces (for locating things like notes) any way you like. It’s essentially manual outlining, on a macro level above the page level. There are no conceptual limitations on what you put where.
However, once you get into the conceptual business of defining broader, narrower and related terms, you are doing vocabulary control. This is taxonomy creation. You are limiting what tags can mean, and how they are related to other tags. You can theoretically do this whether or not you have any instances of them yet.
You could import a taxonomy of animals, or a medical taxonomy, industries or minerals… whichever of those is important to you. There are lots of these official taxonomies, as you know. But this would give you a pre-structured set of properly-organized tags for organizing knowledge in the same way that your larger discourse community organizes it.
That would be very helpful for collaboration in certain contexts. I could see it as something a PhD student might do right away for getting some structure into their research database.
It would be cool to import a public taxonomy as a an outlined page, with indentation to represent each level in the nested hierarchy, but no square brackets around anything (or no hashtags). Then you could only turn the terms you want into pages, and potentially delete whole branches of the taxonomy that you are pretty sure will never relate to your work.
That kind of importer might not be core, at least at first. If structured research/discourse communities start to gravitate to Logseq, it might become a killer feature, but importing public taxonomies might be best left to a plugin for now - and it’s not what you’re proposing anyway.
It sound like you - like me - want to create your own bottom-up taxonomy of tags. I want that, with a thesaurus to keep track of (groom) term trees, to keep them clean.
I see Vocabulary Control as distinct from Polyhierarchy. Vocabulary control is very important to me as I envisage long-term use of these tools. I have no illusions that every note can or should fall within the scope of any one taxonomy. Taxonomies are MOC-style notes like any others, that structure segments of the graph - but they’d need to enforce the SKOS nesting relationships defined within them.
Just like on an MOC-type page for a manual namespace-based hierarchy, it would need to enforce the manual indenting levels you created across pages in the namespace - even though you’d need to be able to add sibling nodes at any level, to make the MOC more verbose and informative.
Idea: Logseq MOCs / Outliner MOCs / OMOCs
What I’m seeing here is the emergence of Logseq MOCs - or Outline MOCs (OMOCs) a distinct form of MOC native to outliners, with enforced indenting to preserve hierarchical relationships that span assemblies of notes (for manual page hierarchies) or ideas (for SKOS-light taxonomy-type conceptual relations) - but you can add notes to make them more informative than just TOC-like header links.
Question: Are Conceptual OMOCs Queries?
I think for the bottom-up conceptual OMOC, what I think you’re suggesting is the creation of a taxonomic index to notes. So you have a page with a taxonomy (you might zoom into specific blocks of it). There you find links to any notes you’ve decided to situate in that taxonomy, by tagging them with terms that fall within that taxonomy’s scope.
Navigating the taxonomy (the page defining the broader, narrower and related terms), would show links to the notes that have been gathered around those terms. It would pull notes into a hierarchy without using explicit namespaces. It’s a separation of the tree-making and leaf-placement concerns.
The concern of a taxonomy is hierarchy-construction. You make the tree as its own term-based thing, independent from notes, but it defines tags. You use those tags throughout your database. Then when you use the taxonomy page to explore the notes aggregated by that hierarchy, any notes you’ve tagged using those terms appear in place.
To express this second point a different way, notes flag themselves for inclusion within a hierarchy by wearing a tag belonging to it. (This is very Tinderboxy)
I see this taxonomic/conceptual plane organization as distinct from polyhierarchy. Polyhierarchy can possibly work with branching hierarchies of “things” only, not nested conceptual ones. So I think polyhierarchy and SKOS are different asks.
Splitting the First 2 Feature Requests into 3 Requests
I agree with you that if you are going to do any of this, it can theoretically be done using SKOS.
If I use namespaces to create branching hierarchies of notes, with no semantics that other people would care about, that can just be my own idiosyncratic instantiation of what, under the hood, is a concept hierarchy.
However, in terms of incremental steps towards developing these features, it’s possible that Feature Request 2, bullet 1, is quick and easy.
Polyhierarchy using the same namespace logic as the team currently uses might be a bit more work, but may not strain the existing architecture too much.
To allow the construction of SKOS-based conceptual taxonomies, and automatically aggregating links to notes tagged for inclusion in taxonomical indexes… the relative difficulty of doing this depends on how hospitable (or how “close”) the Logseq architecture is to SKOS already.
Perhaps its a North Star, and the team should try to make new developments future-compatible with SKOS, but it may not be something they can deliver in one incremental step yet. It may be more of a Saga than an Epic.
Feature Request 3: Tree Search
If you can aggregate leaf notes, so they appear at the right places in a conceptual tree for one big OMOC hub, which seems to be a query, to me, then Tree Search is probably a matter of adding a bit of tree-based syntax to cross-note queries.
I don’t know to what degree tree search query syntax is supported or achievable across multiple notes, in namespaces or so on.
Logseq is an outliner so there must be a ton of parent-child-sibling logic in there, within the page level. Presumably it could be elevated across pages to populate OMOCs. But I’m a newbie so I’m still figuring all this out.
Maybe this isn’t a feature request to the development team at all, but a user-community effort to figure out how to construct this kind of query. I don’t know. If it’s a feature request, it doesn’t seem as big to me as SKOS-based conceptual hierarchy support (enforced nested hierarchies).
Is All This Worth It?
It bothers me that when I express the desire for these library-science types of things, people often chime in suggesting it’s a high-investment, low-return activity with fragile output.
Many of these people understand that careful note creation is important, but suggest that structured outlining over a large collection of notes somehow isn’t.
I see a future where someone in their 20s today collects extensive notes for 40 years. Then they want to start writing masterworks. I think if they’ve been playing with and refining namespace OMOCs, and conceptual OMOCs all along, those will provide important pathways into their ginormous note clouds.
This isn’t foldering. These structured pathways into their graphs don’t need to be exhaustive. Not every note need be encompassed by these maps, and that’s fine.
I think you can often say about classification hierarchies what is sometimes said about plans. “Plans are useless, planning is priceless.”
When I spend time and expend intellectual effort organizing things hierarchically - essentially thinking like an outliner, but using crisp criteria over very large collections of notes, it increases my mental clarity. If at some point the hierarchy becomes useless, I’m happy to let it go stale.
When I’m writing a start with an outline but as I get into the compositional flow of things the outline gets very malleable and may be abandoned altogether as a new emerging logic asserts itself.
At the same time, a meta-outline that grows resilient over time, and seems to legitimately embody the larger structure of your way of thinking, would be gold.
tl;dr - I think we have 4 feature requests here, not 3. Actually… I think there are 5 - one is hidden.
- Namespace-based hierarchies homepage (the “Logseq namespace MOC”) autolinked from sidebar
- Polyhierarchy support (multiple “Logseq namespace MOCs” - where children can have two parents)
- Conceptual hierarchy (a complex query page that aggregates notes to the right nesting level in a conceptual tree on a page that has the property of being a conceptual hierarchy… ?)
- Tree-search - a query that picks a page in a multi-page hierarchy as parent, and returns it and all its child pages.
The hidden feature is enforcement. OMOCs would ideally be editable, with enforced limitations on indenting. OMOC indenting would have to enforce the multi-page nesting order of the multi-page hierarchy.
If you were doing an SKOS-like taxonomy to control vocabulary on a Conceptual OMOC, ideally that too would be editable. You want to be able to add sibling blocks for headings, comments, and maybe even manually link to additional pages. But if you’ve defined the hierarchy using either namespaces or concepts, the OMOC would have to preserve that nesting order. That’s an architectural saga, perhaps, and would be a fifth feature request.
Enforcing nesting levels like this doesn’t force page links to a single position in a hierarchy. If a page link is tagged with two concepts that both fall within the scope of some OMOC you’ve written, it would appear twice. It would have two parents. That’s fine.
Sorry for the rambling post. I can be very succinct - but I’m tired plus due to family stuff I step away and return frequently to this post. I haven’t had time to look back over stuff and redraft it during this time.