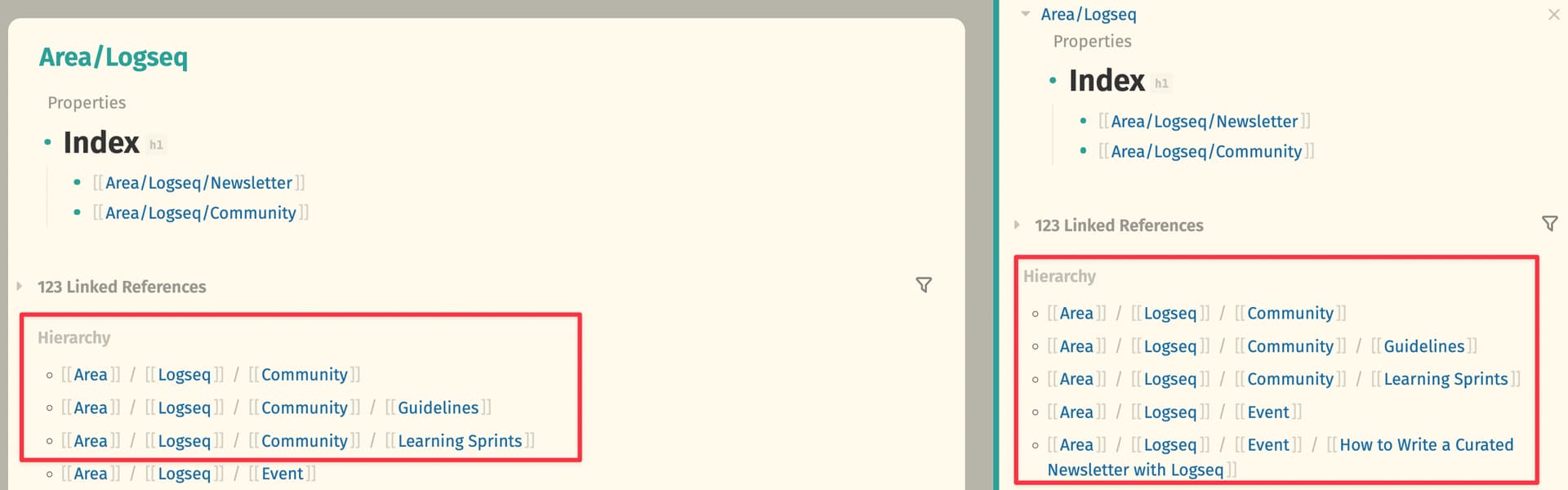
Maybe I misunderstand you, but this already exists. You can show the namespace (called Hierarchy in Logseq) both in the main window and sidebar:
1 Like
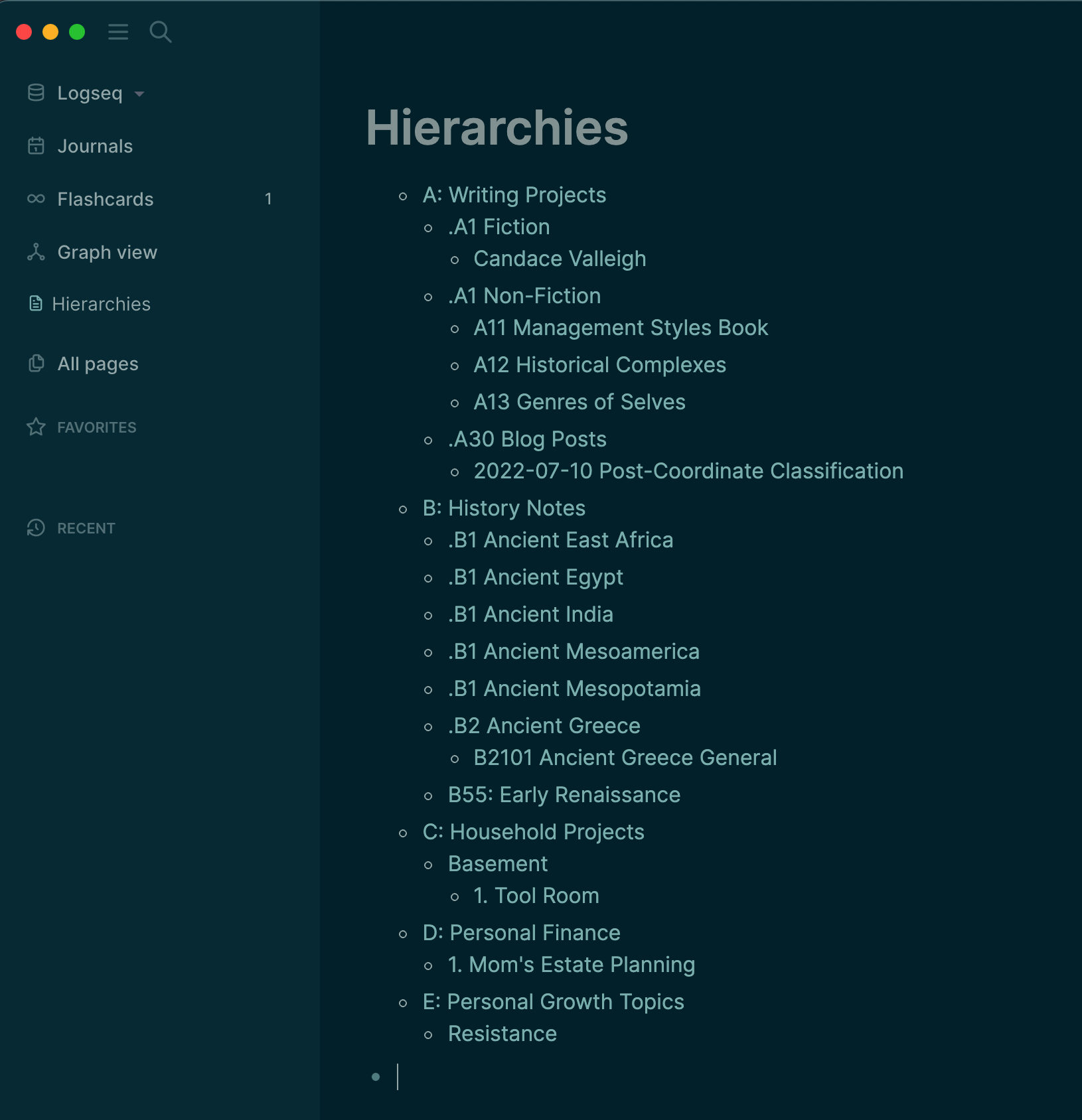
@Ramses Left Sidebar, for all Hierarchies, was my thought
1 Like
Logseq is an outliner that’s built on top of a graph database. What you’re proposing sounds more like something for #feature-requests, but it would cause an anti-pattern (back to folder hierarchy).
The hierarchy at the end of the page with all other pages in the namespace is the closest to a folder hierarchy you’re going to get in Logseq. Personally, I wouldn’t obsess too much about hierarchy in Logseq and instead rely more on linking and indenting blocks.
4 Likes
We discussed this for a while and here there is our proposal:
I don’t think this is an anti-pattern; namespaces seem to me more similar to folders than the proposal above, that links together properties, queries and hierarchy.
3 Likes
I’m running into a limitation of my technical understanding here. All I can rely on is my own understanding and use of Logseq as a graph tool, and I wouldn’t know why I would want to create (strict) hierarchies in my graph. But, to each their own.
I know @cldwalker is interested in reworking the namespaces, so I hope he’ll have a look at the proposal.
But these are not more strict hierarchies than the ones we already have. It’s just some helping UI/UX.
At the moment when you look at the graph you only see one type of relation, “reference”. We want to embed more information into relations between pages by using properties (already possible) and browse/display it (what we are proposing).
For example you want say [[Linear Algebra]] is a branch of [[Algebra]] that is a branch of [[Mathematics]].
At the moment you have three possible approaches
- namespaces:
[[Mathematics/Algebra/Linear Algebra]]
- Pro: better navigation with breadcrumbs at the bottom of pages
- Con: too strict, hard to manage, don’t scale, can’t use the same page in different hierarchies
- block indentation:
- [[Mathematics]]
- [[Algebra]]
- [[Linear Algebra]]
- Pro: easy to manage, edit, update, you can mention the same page in different hierarchies
- Con: worse navigation i.e. no breadcrumbs like namespaces and in the graph all the relations look the same i.e. no way to specify that the above is a
branch-ofrelation
- properties:
Algebra.md
branch-of:: [[Mathematics]]
Linear Algebra.md
branch-of:: [[Algebra]]
- Pro: you can give a name to the relation (“branch-of”), it can be combined with queries, the same page can be in different hierarchies
- Con: basically impossible to browse, no breadcrumbs, no command to print an indented list like namespaces, no way to display only this relation in the graph view
We are proposing better UI/UX for the third approach that could solve two issues often mentioned by users: graph is a mess to navigate and namespaces are hard to manage.
9 Likes
- Why is this an anti-pattern?
- It’s an indented outline!
HIERARCHIES NEED NOT BE STRICT
- As alex0 says, there need be nothing “strict” about these hierarchies.
- Think of hierarchies as flashlight beams into your graph.
- You can have several, illuminating your graph from different angles.
- A block or page can turn up in several hierarchies.
- Sometimes you want to look into your graph, and go to a specific place, and start working there.
- It’s a wayfinding or orientation aid, exactly like Nick Milo’s MOC and Datascope concepts.
IT’S MORE LIKE AN “OUTLINER-STYLE” MOC HUB
- It’s fine if most of the pages in my graph don’t show up in this MOC-type of view of namespaces.
- I don’t intend this hierarchical “net” I’ve thrown across part of my graph to be exhaustive.
- I’d expect the number of pages directly returned by “Hierarchies” to be small, compared to the number returned by “All Pages”.
IT’S THE SAME OUTLINER PATTERN - AT A HIGHER LEVEL OF ORGANIZATION
- It’s just an way to visually review all the pages I’ve chosen to relate in branching patterns
- It lets me get into my graph spatially, instead of temporally.
- I’m a spatial/navigational thinker (not a visual thinker - I don’t need an infinite canvas and stickies!)
- I like & want Logseq’s default view of information - outlines - but at a higher level of organization (pages in namespaces)
SHORTCOMINGS OF MY INITIAL NAMESPACE-BASED EXAMPLE
In the example/screencap I shared, I used a hard-coded scheme based on namespaces. That may be distracting. It may make it seem like I only wanted this for namespaces.
Technically, it’s possible hierarchies could be created more flexibly, using queries and page properties, which alex0 figured out (as I describe below).
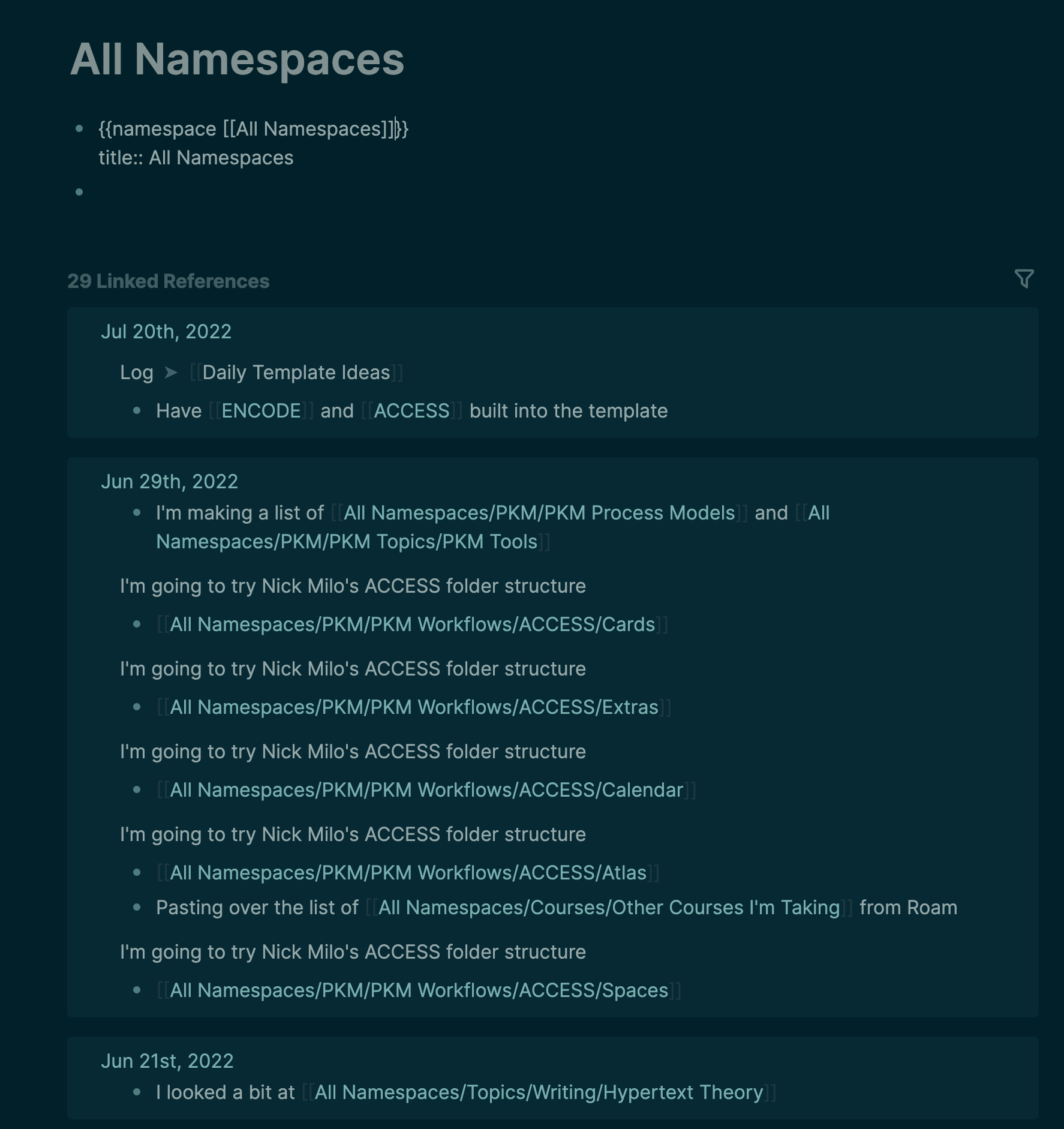
But for my own inadequate, limited, purely namespace-based example, I ran a query something like this:
And that returned something like this:
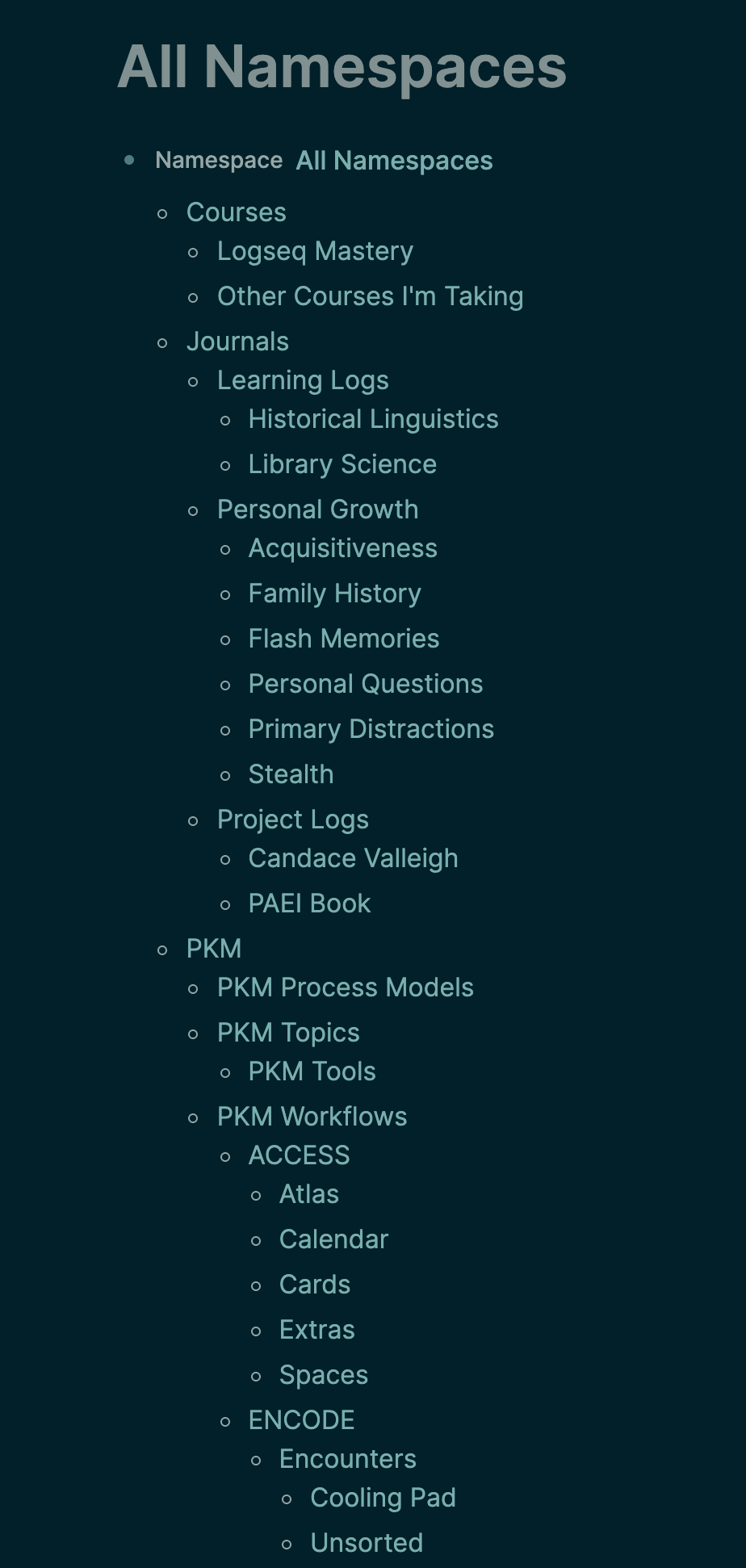
I WISH I COULD EDIT THAT RETURNED OUTLINE
But I can’t edit that outline, to add headers, and text blocks to explain what’s down each branch. That would make this a true MOC hub.
More ambitiously, it would be cool to move and rename pages here, and have those structural changes cascade through my graph.
Basically, Logseq won’t let us do to namespaced pages what it lets us do to blocks on pages. (Unless we do it manually).
I just want to keep doing my “Logseq thing”, over this higher level of organization.
IT’S ALREADY A FEATURE IN DEVELOPMENT
- It’s hard to see it as an anti-pattern when it’s already what gets returned by the {{namespace}} query.
- Logseq already supports a very rudimentary version of the feature of aggregating and displaying namespaced pages.
- I’m just providing input about how this existing feature can be enriched and expanded.
BEING "OUTLINE-STYLE MOC-FRIENDLY IS A GOOD DIFFERENTIATOR
- I think there is huge potential here for Logseq to become very distinct from both Roam and Obsidian.
- Why not support outlines above the level of the page - editable outlines of namespaced pages?
- Right now, we can build those manually
- But the namespace information exists in the database, so it could be automatically generated
- Alternatively, we could add a “type:: hierarchy” property that takes a path as a value maybe
- Then a system-provided “Hierarchies” page could show multiple hierarchies.
- Again, these would be like MOCs, not exhaustive TOCs of the graph
- “Hierarchies” becomes an MOC hub, not a document root for all pages
COMBINING NAMESPACE AND QUERY-BASED HIERARCHIES IN THE MOC HUB
- The hierarchy I explored was only a namespace-based one
- That’s only because I didn’t have the knowledge on how to do it using queries over properties.
- The queries + properties solution could be implemented if alex0’s Feature Request here was implemented: Specify and display relations between pages/tags.
- Namepace-based hierarchies and property-based ones could conceivably all appear in the MOC-hub (the “Hierarchies” page)
- If the information appearing there was editable (with restrictions), we could add headings into that “Hierarchies” outline to clarify what the different MOCs/hierarchies are
NOT AN ANTI-PATTERN (NECESSARILY)
-
tl;dr - I’M just saying that Parent-Child context matters, at a higher level than just on the page.
-
If this higher level of outlining was forced and exhaustive, it would be an anti-pattern
-
Since it’s not, it’s actually just a combination of the main pattern (indented outline) and a secondary pattern (namespaces) that is already supported
-
People would just have to be advised, as Nick Milo does for Obsidian users, that trying to make MOCs exhaustive is a bad idea.
-
MOCs are accelerators, not organizers.
-
It’s wayfinding for people who think about their personal information topically, instead of by today’s date.
SUPPORT HUMANS, NOT IDEOLOGIES
- Different people will differ in the amount of higher-level organization they need to avoid disorientation
- According to the book “The Science of Managing Our Digital Stuff”, most people far prefer navigational methods to search (for personal information management tasks).
- Using term-based methods like tagging or search is less preferred for personal info (unlike with public information like web pages)
NAVIGATION FREES UP MENTAL RESOURCES
- People need navigational structures because then they can rely on recognition instead of recall to access their info, and procedural rather than declarative memory
- This is especially important if ever Logseq wants to attract a user base that doesn’t necessarily use the tool every single day.
- Those kinds of users would need recognition-based cues to get reoriented to their graph, and not have to dredge up declarative memories of what might be in there.
- If the research findings about PIM hold up, the tool that achieves the best balance of navigational structure and distributed graph traversal will have a strong advantage in the marketplace
ENJOY THE MAGIC, BUT CHOOSE YOUR STARTING POINT
- The magic of graph traversal is you can have serendipitous discovery of linkages that grow in value over time
- But what is the value of doing that from an abstract, search-driven starting point every time?
- Why not chose a topic-based starting point or launchpad, and then enjoy the graph-traversal magic?
- Logseq can become the tool that best balances both wayfinding impulses, leveraging the new graph-traversal paradigm, with just-enough-wayfinding-structure for people more familiar with older approaches
PRAGMATISM OVER PURISM
- Roam is doctrinaire and purist about its graph database philosophy, and hostile to hierarchies.
- I finally became loyal to Logseq because I saw the word “Hierarchies” on a page!!
- (Also, because key evangelists were badly treated by Roam, I thought)
- Since it’s there, I figured the Hierarchies functionality would continue to be developed.
- It would make me sad to learn hierarchies are an anathema to the philosophy and culture of the Logseq developers.
- That’s why I asked: Would a rich commitment to hierarchies and classification be an anathema to Logseq culture?
9 Likes
Hi @Ramses. I wrote a hopefully simple to understand introduction on why we need a way to organize pages differently than by just namespaces: Knowledge Management for Tags / Tag Hierarchies
This request is not about enforcing “strict” hierarchies in the graph (in the sense of being forced into a folder structure).
It is about organizing a huge graph by adding relationships between pages.
This would enable many additional ways to locate a page, e.g. faceted searches and hierarchical browsing that is used e.g. on Amazon’s website or in a library catalogue.
This request fits very naturally into Logseq’s data model with some small extensions to the search, as suggested in @alex0’s feuture request he mentioned above: Specify and display relations between pages/tags
It would be great to get feedback on these requests, as some of us consider them to be absolutely essential to organize larger graphs. Currently the “best” practice recommended to deal with e.g. Zotero imports is to just delete nodes to simplify the graph. That can’t be the intended use.
3 Likes
@boisjere Can you expand on this? I can’t quite follow what you’re doing here, but I’d like to be able to replicate it.
Well @knowlost - first you have to do the somewhat tedious task of renaming all your files - or at least, all the ones you want to appear in your hierarchy.
You have to put them all in the same namespace, under one top-level name. I used the term “Hierarchies” for this top-level name in one sample I shared. I used the term “All Namespaces” in another. If you like the idea of Maps Of Content, you could write “MOC-Hub” as your top-level term, or “TOC” for Table of Contents, or “Index”, etc.
Then you have to go through and rename all the pages in your graph to put them under that top level name. Right now I’m working on some stuff about fiction writing. So I have ideas like Plot, Theme, Character, Arcs, and types of Arcs, for example.
I’d have to rename the pages like this (using MOC as my top-level name):
MOC/Story-Theory/Theme
MOC/Story-Theory/Arc
MOC/Story-Theory/Arc/Plot-Arc
MOC/Story-Theory/Arc/Character-Arc/Readiness-Arc
MOC/Story-Theory/Arc/Character-Arc/Damage-Arc
MOC/Story-Theory/Arc/Character-Arc/Awakening-Arc
MOC/Story-Theory/Arc/Character-Arc/Choice-Arc
It’s ugly. Every page ends up having a fully specified path as its page name. Pages are named according to their breadcrumb trail in the hierarchy you want to build. It won’t scale very far.
Anyhow, doing all that will give you an MOC page. Navigate to that page. There, you just type the following query on a line: {{namespace [[MOC]]}}. It seems like a self-referential query, because you are asking it to return all the pages beneath and including it, but then displaying it “on itself”. In truth, I think the query just returns what it returns, and doesn’t care where it’s called from.
That will give you a tree of all the pages in the MOC namespace. Then you add that page to your favourites, and you have essentially the kind of functionality I’ve been squealing about all over this forum.
You could segment your graph into several namespace-based MOCs. So you could create an MOCs page, but not use it in any namespaces.
Then you could use those God-awful breadcrumb-style page names, using several root-level names. So I could do:
Story-Theory/Theme
Story-Theory/Arc
Story-Theory/Arc/Plot-Arc
Story-Theory/Arc/Character-Arc/Readiness-Arc
Story-Theory/Arc/Character-Arc/Damage-Arc
Story-Theory/Arc/Character-Arc/Awakening-Arc
Story-Theory/Arc/Character-Arc/Choice-Arc
…and…
History/Canada/Ontario/Suburbs/Car-Culture
History/Canada/Ontario/Suburbs/Car-Culture/Canadian-Tire
History/Canada/Ontario/Southwestern-Ontario/Memoirs
History/USA/1940s/Film-Culture
History/USA/140s/Sex-and-Gender
Then on my MOC page, I could put two queries:
{{namespace [[History]]}}
…and on a separate line…
{{namespace [[Story-Theory]]}}
Then I could add the MOCs page to my Favourites like before, and there’d be a few MOCs on it
Nick Milo often says MOCs should not aspire to become exhaustive Tables of Contents. They’re just accelerators to get you into good spots in your graph. So you wouldn’t need to have breadcrumb-style page naming everywhere, just on pages you wanted to index this way.
The advantage of using a namespace-based approach is that the branch in your tree leading up to a page appears in the “Hierarchies” section at the bottom of each page.
However, a page can’t be in two namespaces at once. So my approach doesn’t allow for polyhierarchies, something @gax has written about extensively on this forum.
If we used the properties-based approach @alex0 devised, we could have polyhierarchies, but queries would have to recursively return “parent-of” and “child-of” pages based on those properties. I don’t think that’s on the Logseq development roadmap.
You can also just create an MOCs page, and hand-code the hierarchy, by making a normal outline, then putting only or mostly page names on it - but it won’t auto-update, not will it appear in the nice, salient “Hierarchies” section like the namespace approach enables.
Anyhow, the approach using the {{namespace [[ x ]]}} query is simple to execute in theory. Renaming pages by hand is a pain though.
1 Like
I’m really enjoying this discussion, even though I barely understand it lol.
Organisation, in Logseq, is what I’m struggling with, as I’ll detail in my next post here on the Learning Sprint.
I particularly like this idea of Logseq differentiating itself from others:
I guess this is the challenge for any 2nd Brain PKM software. Loving this software and am excited about possible future developments:
I just noticed I can move .md files (using a file manager) everywhere in the graph folder (in the root of the graph, in a custom subfolder or a subfolder of /pages) and Logseq just recognize them as they were in /pages. You just need to make sure there aren’t file with the same name in different folders.
4 Likes
Going to link this video onto this thread as I feel it delves into some of these topics

5 Likes
Let me get this straight - when saying that every child page will have a backlink to all the parents in the hierarchy, you aren’t actually talking about namespaces, right? Only that backlinks will appear somewhere as a reference, but to Logseq, this approach does not really impose any hierarchy (unlike using “/” in the name). Correct?
Indeed, I’m talking about Linked References section
Correct
1 Like
In fact, the “child_of” or “parent_of” relations that define hierarchical structures are semantic relations. Hierarchies are concepts as a set of blocks described by a semantic query.
Greetings.
I’m still rebooting with Logseq and I’ve been struck by your reference to a Telegram bot since I use it a lot.
I know this is not related to this thread, but
Could you, even if it was private, tell me something about that bot or tell me where to find information about it?
Thank you
Hi, this is the bot: GitHub - shady2k/logseq-inbox-telegram-plugin
It’s available as a plugin from Logseq marketplace, so you can install it from there and then follow the instruction in the page above.
It’s a matter of 2 minutes, basically you will create a bot using Telegram, it will provides you with a token and with that your Logseq will be able to access your bot.
2 Likes
Having not used Logseq in awhile, and then going back into my graphs, I have to re-emphasize the value of this point I wrote earlier:
- People need navigational structures because then they can rely on recognition instead of recall to access their info, and procedural rather than declarative memory
- This is especially important if ever Logseq wants to attract a user base that doesn’t necessarily use the tool every single day.
- Those kinds of users would need recognition-based cues to get reoriented to their graph, and not have to dredge up declarative memories of what might be in there.
- If the research findings about PIM hold up, the tool that achieves the best balance of navigational structure and distributed graph traversal will have a strong advantage in the marketplace
For someone who uses Logseq for specific purposes, and doesn’t “live in it”, the “time-first” navigation pattern, and strong search-dependency, is very difficult to work with. It’s like there’s not enough structure there to work with, and you start your retrieval experience by being stymied and disoriented.
I don’t see how a tool can grow its market if it assumes people will use it everyday, or at least so frequently that they don’t need more cognitive scaffolding to use it. Scrolling through the journals gives me no idea what I was thinking in the past if my thinking has gone cold. The much maligned Graph View is actually the most helpful tool to get re-oriented.
9 Likes
Precisely. This is why I have been voicing my feedback about a need for a library view to see your graph’s structure. As it is today its just chaos in a non-linear system that relies on recollection to retrieve notes. I may not recall something that could be 10 layers deep until i’m 3-5 days into something and I stumble upon the note by luck, where if I had structure I would of found it on day 1 by looking over my hierarchy.
Now all this could very well have to also do with the fact that I struggle with ADHD. I can only survive by having structure and having everything within view at any given time to see where and what contains all of my notes. When I lack that structure it can become overwhelming for me and panic mode begins to start simplifying my system even more.
1 Like