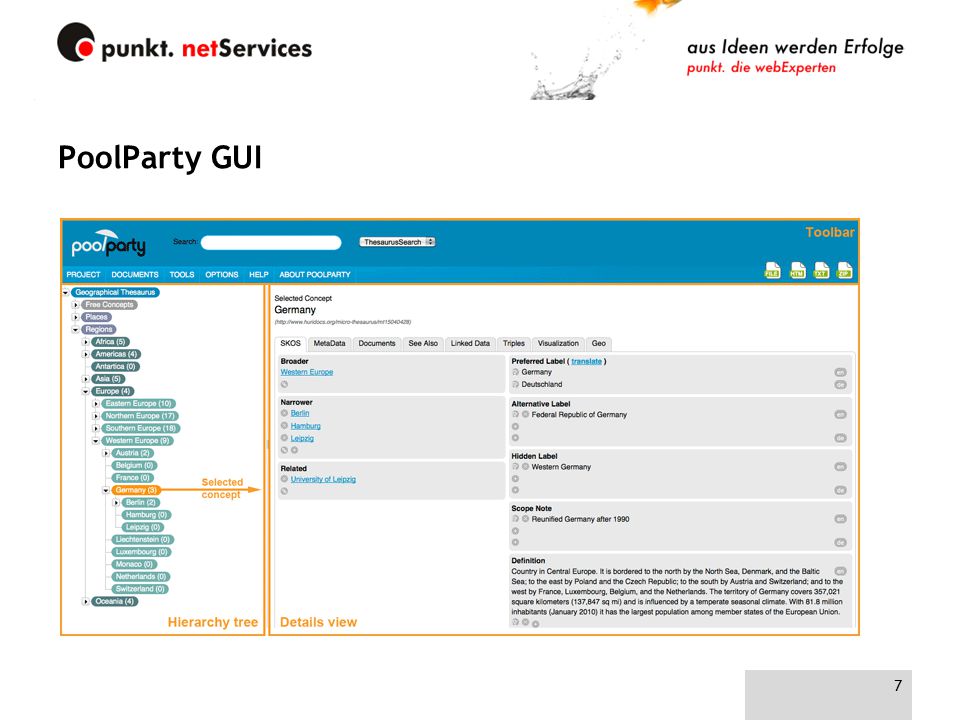
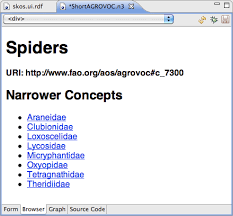
Why do we need Knowledge Management for Tags?
- Graphs will quickly have far too many tags
- We need a way to organize and browse tags
The Problem
- Tagging leads to a large number of unrelated tags (thousands) without any structure
- Browsing these tags through a list, graph, or tag cloud, is not very efficient
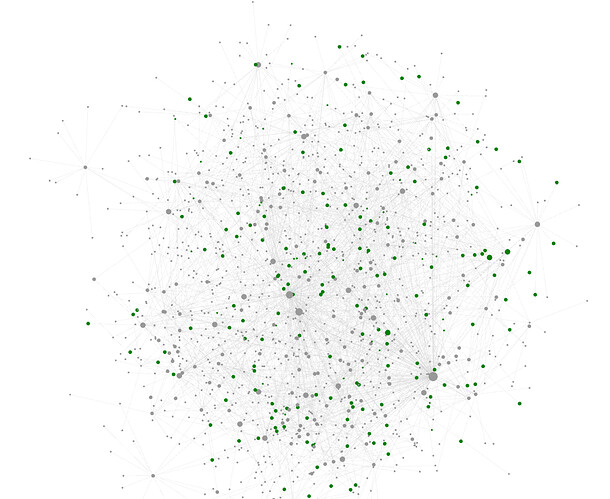
- As shown in another thread by @ChrisYT and @Zdenek_Hurak items imported from other systems (e.g. Zotero) have many overlapping tags, such as “History, 20th Century”, “history”, “History / World”. In practice, this creates graphs that look like this
and is practically unusable, the recommended solution being to just delete the tags (and discard the information contained in the tags).
The Solution
-
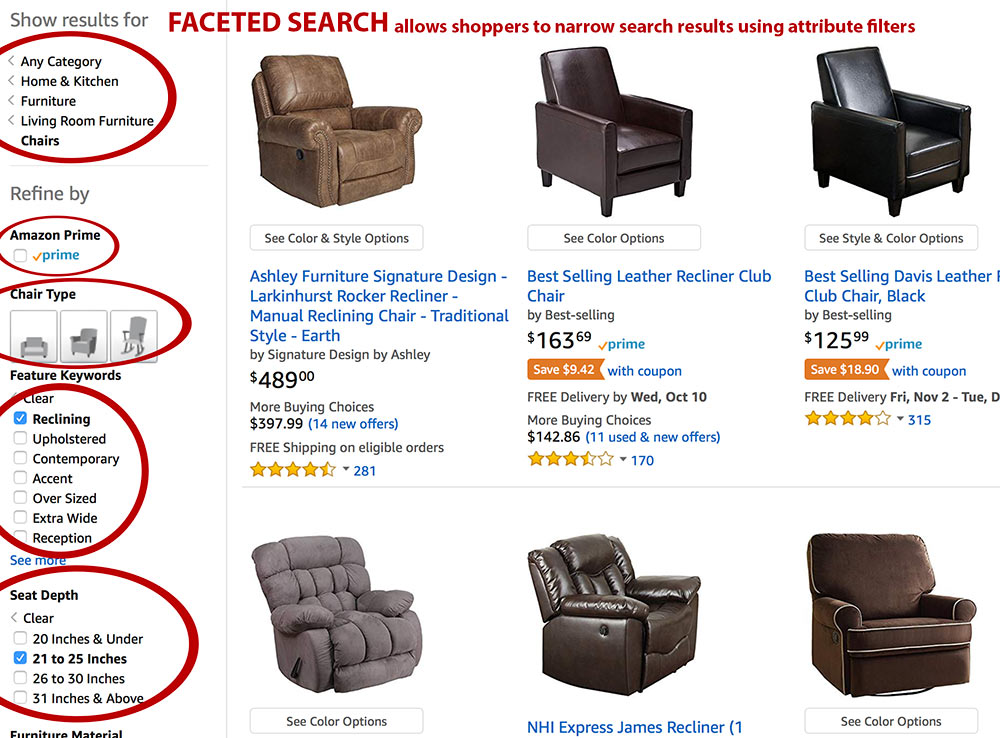
Many efficient search strategies exist elsewhere:
-
faceted search on [OpenLibrary] (Architecture | Open Library) (Search for “Architecture” then then narrow down by Subjects, Places, People, Times,…) or Amazon
-
browsable (poly)hierarchies, like the Dewey system or taxonomies.
-
Graphical visualizations with embedded links
-
-
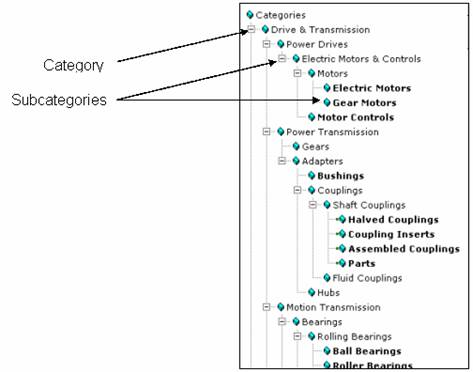
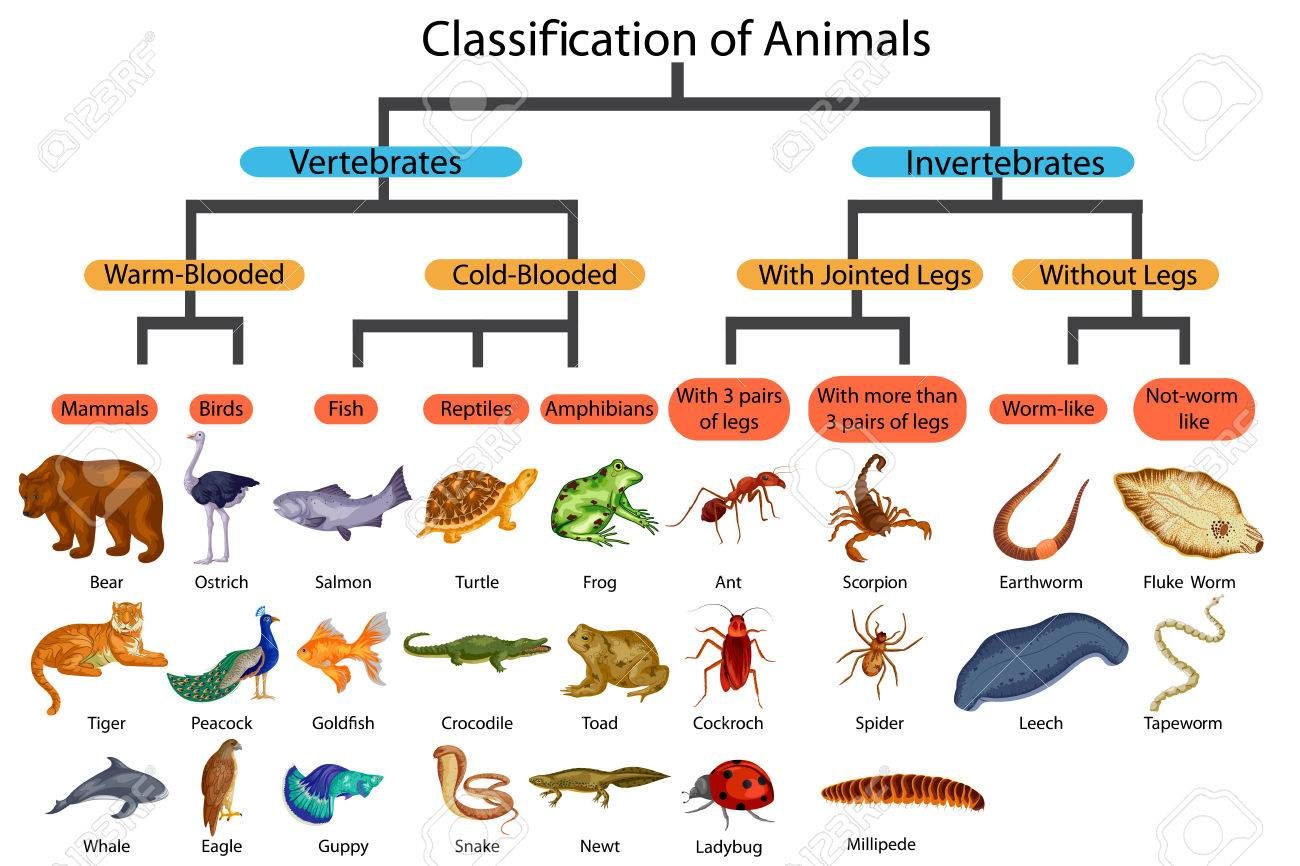
To efficiently search e.g. this animal taxonomy, we need to encode the relationship between tags
-
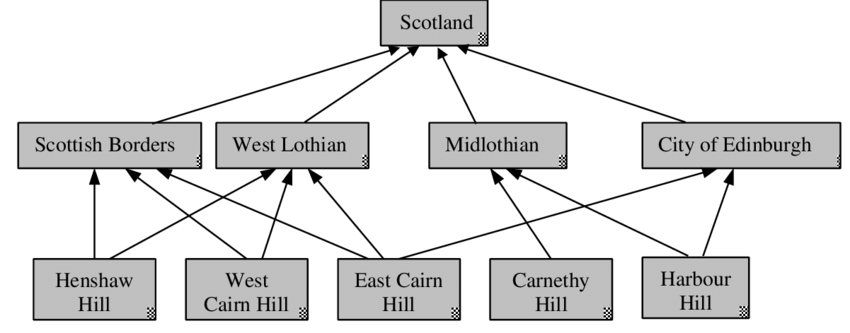
Generally, these hierarchies will often not be strict containment hierarchies, but many elements will have multiple parents, this is called a polyhierarchy:
-
Logseq’s hierarchies of the form
[[parent/child/teddy]]are not sufficient for several reasons:- Each child can only have one parent (
teddycan be both in thechild, and in thestuffedAnimalscategory, but currently this can’t be recorded) - The classification is specified on the pages themselves and can’t be added on later
- If I tag 100 pages with
teddyand later want to add the tag to a hierarchy, I need to edit every single page. Instead, it should be possible to tag pages, and then later classify tags centrally, making all of the original pages findable under the proper hierarchies
- If I tag 100 pages with
- Each child can only have one parent (
What needs to be done?
- Logseq needs a way to specify relationships between tags. One approach, widely used widely used, e.g. by libraries, is the Simple Knowledge Organization System (SKOS):
- TagA is a broader/narrower version of TagB
- TagA is related to TagB
- These relationships are captured centrally, such that tags can be managed without editing each tagged page individually
- We need a user interface to hierarchically browse Logseq pages (not part of this feature request)
- We need a user interface to easily add and edit tag hierarchies (not part of this feature request)
Example use case
Historian Bob studies animals in history.
He reads the following book:
Ark Royal : the Life on an Aircraft Carrier at War 1939-41.
| Author: | Sir William Jameson |
|---|---|
| Publisher: | Penzance : Periscope Pub., 2004. |
The book has these library classifications:
-
Dewey
940.545- Class 900 – History and geography
-
- World History And History Of Europe, Asia, Africa, Australia, New Zealand, Etc.
- History (General)
- World War II (1939-1945)
- Naval operations
- Anglo-German By engagement, ship, etc., A-Z
- Naval operations
- World History And History Of Europe, Asia, Africa, Australia, New Zealand, Etc.
The book is tagged with Dewey:History of Europe and LCC:Anglo-German By engagement, ship, etc., A-Z. “Dewey:” is the namespace for the Dewey system, and “LCC” is the namespace for the Library of Congress Classification. These tags be added easily automatically by an improved Zotero plugin.
So just by automatically importing library classifications, we can already browse our books by the Dewey and LCC systems.
The book is also automatically classified by author last/first and year.
The book also mentions a cat, Unsinkable Sam, so
Bob tags the book with animals:F. catus. This makes the book appear in a hierarchical search about animals as well.
So with very little effort (a single manually added tag so far), Logseq can already automatically generate 5 browsable hierarchies:
- /Books/ByAuthor/Jameson/William
- /Books/ByYear/2004
- /Dewey/History and geography/History of Europe
- /LCC/World History and …/History (General)/World War II … /Naval Operations/Anglo-German…
- /animals/…/…/Mammalia/…/Felinae/…/F. catus
Additionally, Bob has a few lightweight classification schemes that fit his work, so he tags the book with bob:aircraft-carriers and bob:non-fiction, this additionally makes the book available under
- /bob/military/navy/aircraft-carriers
- /bob/literature/non-fiction/
Further, some plugin might provide a faceted search, so Bob can search under /bob/military and then narrow down by animal type.
Bob told Logseq that aircraft-carriers is narrower than navy which is narrower than military, so Logseq can also generate these search hierarchies automatically.
The process is very lightweight, so Bob can easily tag individual blocks of his notes.
It does not affect the current use of tags either, so Bob does not need to classify all tags from the beginning, he doesn’t even need to use the hierarchical capabilities at all.
The Library of Congress also uses SKOS, similarly, Logseq would provide navigation to broader, narrower, and related terms:
- LCC:
Example implementation
As @alex0 mentioned, tags are pages themselves, so in principle, the information about broader and more general tags can be stored directly in the tag page without changing the Logseq data model:
The problem is that currently no user interface exists for editing these relations across files.
The following example uses Markdown to represent a subset of SKOS. Such a Markdown file could be autogenerated based on the parsed tag files to present all hierarchies in a single document. Changes would then be propagated back to the individual files.
-
Tags are connected using the relations
broader,narrower,broaderTransitive,narrowerTransitiveandrelatedbroader,narrower- specify that one tag represents a broader/narrower concept than another
broaderTransitive,narrowerTransitive- specify that one tag represents a broader/narrower concept than another and all its children/parents
- e.g. A Cat is a narrower concept of a mammal, which automatically makes it a narrower concept of Animal
related- two tags are related, e.g. Apples and ApplePie
-
This is not to suggest any specific syntax, is just an example how to display the data as Markdown itself in the spirit of Logseq for easy editing.
- Alternatively, Logseq could directly parse SKOS RDF/Turtle description files.
- Several editors exist to create these description files.
- SKOS is a minimal example, other knowledge management systems exist, and in principle Logseq could record arbitrary relations between tags.
- SKOS relationships can have additional metadata added, such as descriptions, translations, or even images, which opens up the possibility of providing an image carousel for the search.
-
The following relationship is a (small) section of the animal taxonomy.
Sub-items of the list are more narrower terms for their parent items. The lists can me arbitrarily nested. For example. Chordata and Mammalia are both narrower terms for Animalia. For a non-transitive relationship, Chordata would be a narrower description for Animalia, but Mammalia would not.-
The animal taxonomy has the namespace
animalsto distinguish it from other hierarchies that can exist in parallel. One item can be in multiple hierarchies at the same time -
semanticRelation::narrowerTransitive concept::animals - Animalia - Chordata - Mammalia - Carnivora - Feliformia - Felidae - Felinae - Felis - F. catus - F. silvestris ``` -
If a user tags an item with
animals:F. catus, the item will automatically appear in a search for Animalia -
The user does not need to tag with the entire hierarchy
animals:Animalia/Chordata/Mammalia/Carnivora/Feliformia/Felidae/Felinae/…, as this would duplicate the hierarchy on every item. The tag is onlyanimals:F. catus, from which Logseq can infer that we are dealing with a type of cat.
-
-
This is an example of a “related” relationship. All of the tags [frying, deepFrying, airFrying, grilling] are marked as related.
- If a user tags an item with the tag frying, a search for related items will bring up the other 3
semanticRelation::related concept::cooking frying deepFrying airFrying grilling- Related tags can also live in different namespaces
semanticRelation::related cooking:frying nutrition:fat
- If a user tags an item with the tag frying, a search for related items will bring up the other 3
Many thanks to @boisjere and @alex0 for their contributions to this draft.
For more discussion, see this thread: Would a rich commitment to hierarchies and classification be an anathema to Logseq culture? - #25 by boisjere