Goal
Make everything truly a block.
Substitute page-tags, page-property of simple, advanced queries and other page-related things by block-operations, resolving inconsistencies between page and block.
Intro / Issue
Hi,
Logseq has the “block” as smallest unit of thought, which is great. In addition, users and developers currently also need to take care of a different concept called “pages”.
Pages are often described as persistable blocks, which are stored as markdown files in the filesystem.
Unfortunately, I have experienced inconsistencies between pages and tags in the user interface (~ one month testing time). This post might serve as point of reference and collection for other related problems, please let me know here. I’ll describe two found issues:
Minimal example
My Page.md:
tags:: mypagetag
- parent #myparenttag
- child #mychildtag
Issue 1: Query with page-tags vs block tags
Both page-tag (via tags:: mypagetag) and blocktag/page link (#myparenttag, #mychildtag) should be tags and uniformly queried. This is not the case currently (assuming otherwise empty graph):
{{query(and [[mypagetag]] [[mychildtag]] ) }}
→ 0 results
{{query (and (page-tags [[mypagetag]]) ([[mychildtag]]))}}
→ 1 result
From user perspective, it is confusing to differentiate between page-tags and normal tags/page links.
Issue 2: Linked reference filter inconsistency
Going to mypagetag page and inspecting the filter at bottom does not show #myparenttag or #mychildtag in the available items to choose from:
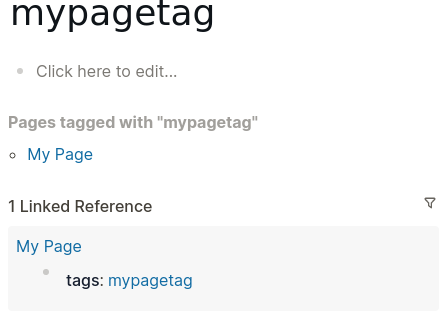
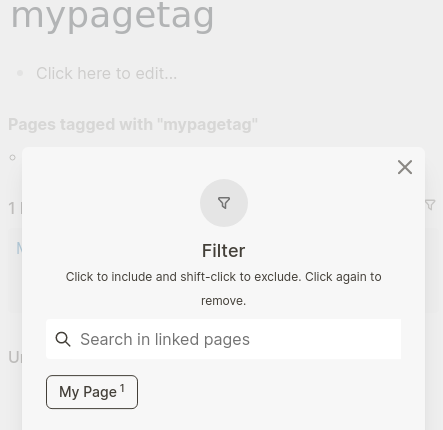
Going to mychildtag will at least show containing page name “My Page”, but not its tag “mypagetag”:
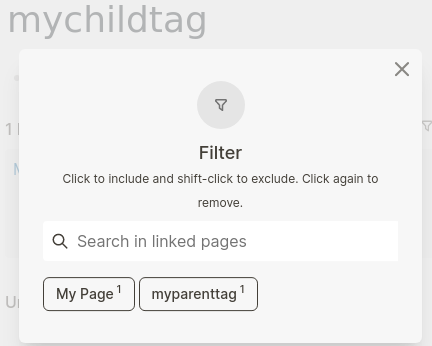
→ Incosistent browsing, depending on which tag you searched first and filtered second
Suggestion
Not sure, if above issues can be easily fixed. But to simply further ongoing development, I would like to suggest further decoupling of the persistence layer, getting rid of page in the UI.
Here is a rudimentary illustration:
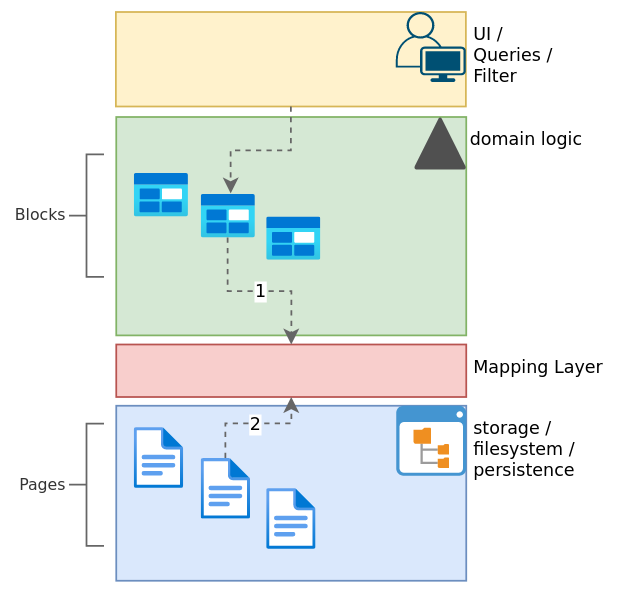
Users (UI) should not need to deal with pages. A mapping layer can act as “glue” between pages and blocks, also minimizing breaking changes, so that current filesystem approach is retained.
This mapping layer might provide information like:
- map page of filesystem to root block for query and other operations
- find containing page of any given block (1)
- get all contained blocks of page (2)
Further advantage: This allows to easily switch persistence layer from file-system to SQLite, EDN, or something different.
What also might get easier to implement
- being able to have block as favorite in sidebar instead of just pages
- Instead of using complex file names for Logseq namespace, just use a block to represent hierarchy
- More consistent page and block
title::property, maybe even block aliases (?)
Conclusion
In an ideal word, there is no difference between pages and blocks from a user experience(UX) perspective - pages just take on the duty of saving notes on filesystem.
Abstracting away the storage to the edges of the system might ease up developers’ life as well. If you already got in touch with the Tana app, their approach is straight-forward in this direction: “Everything is a node”.
I think this would be a good time for optimization, as the app is still in Beta status. Feel free to correct me otherwise, if there should something wrong here.
As last point, let me emphasize I love logseq. Please take this as constructive criticism and just an idea to make overall product better.
Greetings
Related discussions