Let’s say I have a note [[Tension]] that I want to categorize under the hierarchy Physics -> Mechanics -> Tension
I could use a namespace [[Physics/Mechanics/Tension]], but I’m trying to get away from folder-like structures. I’d rather use a topic:: page property.
So the [[Tension]] page would have topic:: [[Mechanics]] and the [[Mechanics]] page would have topic:: [[Physics]].
The problem is, Logseq doesn’t associate [[Tension]] with [[Physics]] with that structure. I suggest making the association implied, where a query for topic:: [[Physics]] would return both [[Mechanics]] and [[Tension]].
In case implied properties are involved in a query, there should be a visual toggle to show/hide those results.
Creating implied association in property chains isn’t just relevant to that use case. Let’s say I’m shakespeare writing Shall I Compare Thee to a Summer’s Day. [[Shall I Compare Thee to a Summer’s Day]] will have type:: [[Sonnet]], [[Sonnet]] will have type:: [[Poetry]], and [[Poetry]] will have type:: [[Writing]].
A query for type:: [[Writing]] should include [[Shall I Compare Thee to a Summer’s Day]], with an option to show only immediate children ([[Poetry]] in this case).
@alex0’s query proposal might be what you are looking for:
Generally, an SKOS relationships would be a superset of what you suggest, and would also be able to express things like relatedness:
One interesting problem with your suggestion is that it removes the distinction between tags (is an element of a category) and properties (is a subcategory of a category), you would express both as topic properties.
I think it would be cleaner to tag the page with #tension and specify that #tension is a subcategory of mechanics, which is a subcategory of physics. #tension might also be a subcategory of #mechanical_properties, which might be a subcategory of #materials_engineering.
Honestly I think many of those other suggestions add too much complexity. And yes, in those examples there is no distinction between elements of a category and subcategories of a category, because they can be the same thing. Forcing one is exactly the reason I can’t just use namespaces. If I knew that an element of a namespace would never become a subcategory of its own, then there wouldn’t be an issue (except for the fact that a page can only point to one namespace)
For now, until this is developed, it might be useful to categorize each subcategory with the full path to its root category.
That is, the [[Tension]] page should be categorized as #mechanics but also as #physics.
Here the transclusion templates could also come in to play. For example, in the previous case, it would be enough to include the mechanical category template, which would include all the relevant categories.
What is youse use case for having subcategory and element relationships be the same?
They are fundamentally different things, for sets it would look like this:
Physics = {1,2,3,4,5}
Mechanics = {1,2,3} ⊂ Physics
Tension = {1} ⊂ Mechanics
1 ∈ Physics but 1 ⊄ Physics, {1} ∉ Physics . “an article on Tension is an element of the physics category, but neither a subcategory of physics, not is the subcategory of tension articles an element of the category of physics articles”
As you said, when you expand Physics, it should show the elements and the subcategories, but forcing them to be the same might break things later on.
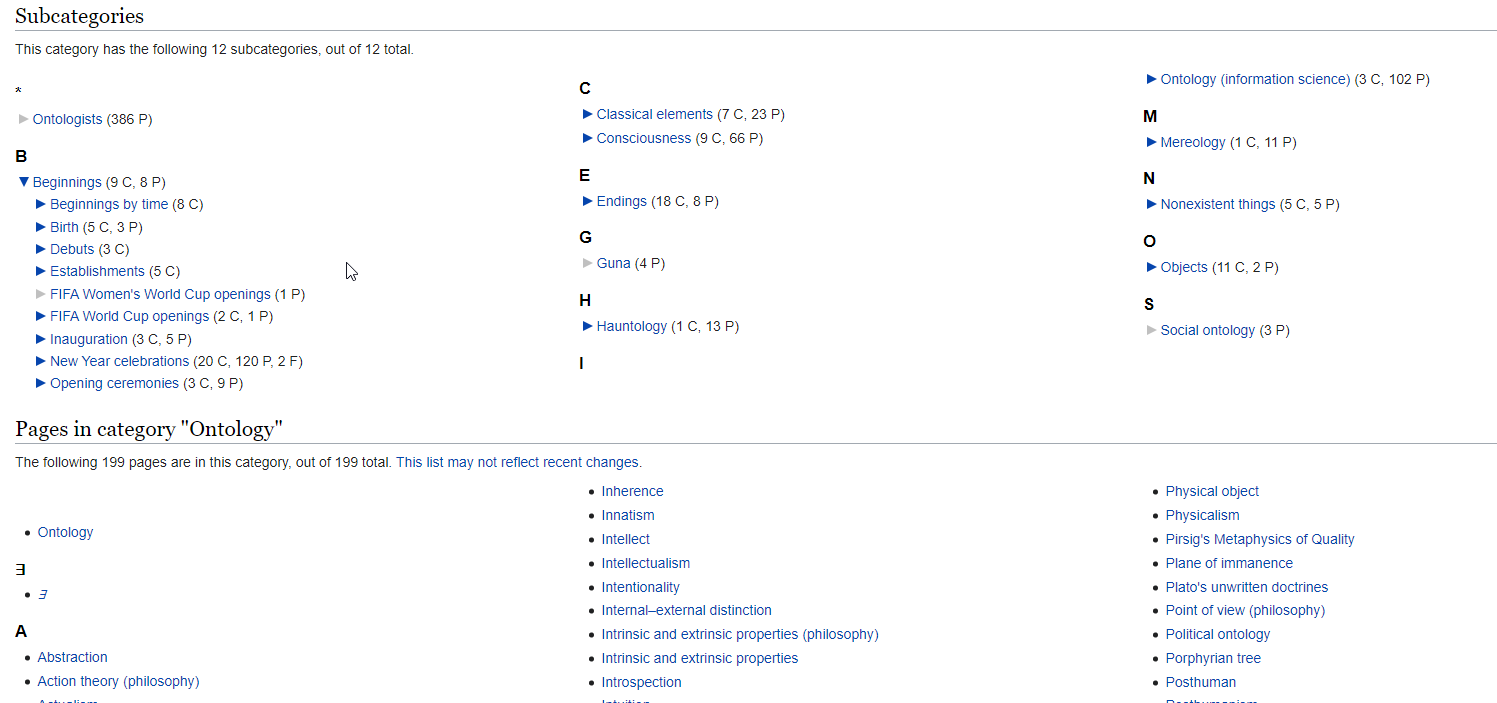
Here is a Wikepedia example, it shows both the subcategories and the pages in the category ontology. Wikipedia can distinguish them, because it knows that a category is different from its elements.
The subcategories can be expanded all the way to the bottom:
That would only allow a simple hierarchy, but an article tagged Tension should automatically be both in the Physics and in the Materials_Engineering categories. The simple folder-like namespace concept is broken, this is the reason which got the entire discussion started.
That would only allow a simple hierarchy, but an article tagged Tension should automatically be both in the Physics and in the Materials_Engineering categories. The simple folder-like namespace concept is broken, this is the reason which got the entire discussion started.
You are right, that’s true. I was just suggesting that in the meantime, as a “trick”, it might be useful in the sense that queries including all categories of the path would return the desired content, with no further implications.
The reason I think elements of a category and subcategories of a category don’t need a distinction is because you can always get more specific. A page may start as an “element,” but as your required level of specificity changes, that “element” should be able to dynamically become a subcategory. With this structure, there is no distinction to begin with.
It’s the same idea as a folder-note. As you go deeper into a hierarchy, you get more and more narrow, but the subcategories (subfolders) themselves can store information, making them an element of their parent category.
I don’t think this structure is contradictory to your Wikipedia screenshot. You can consider [[Mechanics]] as an element of [[Physics]] until you create the [[Tension]] page, which points to [[Mechanics]]. At that point, Wikipedia would consider [[Mechanics]] a subcategory of [[Physics]] rather than an element, but really there’s no distinction beyond the label.
So Tension = {1} is an element of Physics, and an element of Mechanics, which is a subset of Physics. If I understand your logic, you’re saying that Mechanics cannot be an element of Physics, because it’s actually the label of a subset.
That’s not exactly how this feature request would work in Logseq. It would instead look like:
Logseq’s data structure already has no clear distinction between set labels and elements of a set, because both are the same unit (pages). Your set example is more like a folder structure, with folders vs files as fundamentally different units
I think we are on the same page. What I meant to say is that we have 3 categories, Physics, Mechanics, Tension. The numbers are the elements of these categories, think of them as articles. So 1 is an article classified in the category Tension. Mechanics = {1,2,3} is the subcategory of the category Physics that has the articles 1,2,3 in it.
It is a subset of Physics {x ∈ Physics | x ∈ Mechanics}, but it is not an element of it. {1,2,3} ∉ {1,2,3,4,5}.
Under the hood, Logseq stores all of them as individual files, at this level they are all exactly the same thing. Didac and I were just chatting in a different thread whether this is a good idea or not, Wikipedia made the decision to use a different namespace for categories. To me it feels that it might not be a good design choice, but it is unlikely to change and I don’t really know if it is bad or not.
Where the distinction comes in in Logseq is between tags and properties. So if we tag an article with #Tension, it means, in set notation, ∈, and if we use @alex0’s idea to represent hierarchies with properties, the line “broader::Mechanics” in Tension.md means Tension ⊂ Mechanics. So Logseq can make the distinction, but it uses one namespace for all of them.
To make your case look like the Wikipedia, we would take all of the pages that don’t have any content other than properties and display them in the “Categories” section, and take all pages that have content and display them in the “Pages in Category”.
Some pages, those that have both narrower properties and content would display in both sections (or could display in a different color).
As far as I can see, this would work just fine.
One downside of this approach is that it is different from the usual tagging in Logseq, so instead of tagging an article with [[Tension]], I would have to set the property broader::Tension (meaning that Tension is a “broader” version of the article, breaking the distinction between ⊂ and ∈).
Tagging would effectively be replaced by setting properties, which have a different use case. I think they don’t yet allow inline syntax either.
I don’t believe that distinction exists/is necessary. A property topic:: [[Physics]] is identical to #Physics, except I’m specifying that the association is by topic for querying later.
This goes back to the idea of no distinction between elements of a category and subcategories of a category. Both tags and properties indicate both∈and ⊂. Adding specific syntax like broader:: creates unnecessary complexity, when we can just apply this system to any property chain like I described in the OP.
Is there a particular reason you think we need a distinction between ∈ and ⊂? Having no distinction allows for more dynamic structures, and also better matches how knowledge works. A subcategory has more information associated with it than just its name, and for that reason each subcategory has a page and is an element of its parent category.
Instead of reasoning in terms of Set Theory, if you look at this from the geometric point of view it will be much simpler:
A graph is the most generic structure. The others, like trees, are contained in it. You can extract many trees from the same graph using different indications.
Properties specify what kind of relation there is between nodes while a normal reference in Logseq is the default “neutral” relations.
Imagine a graph where all the connections are the same. That is a graph made from references only.
Then imagine a graph where there are different kinds of connection, each with a different color. That is a graph enriched with properties. Each property key has its color.
Now imagine to traverse the graph following a certain color, obtaining different structures including trees.
I’m proposing that the user can choose any of the property he used to extract a structure.
It’s up tp the user to dedicate one or more property keys to build a certain structure.
For example an user could introduce property keys like these:
category:: for example [[Mechanics]] has the property category:: [[Physics]], [[Tension]] has category:: [[Mechanics]] etc to get a tree
next:: for example [[Chapter 1]] has next:: [[Chapter 2]] to get a chain
instance-of::, belongs-to:: etc for other trees.
Logseq doesn’t have to choose any property keys, they would be user-defined. What’s Logseq has to introduce is a syntax like {{tree key}} to traverse the graph using key as indication and display the results as a tree.
If this is clear now, please read again my previous message.
I don’t have a good example where something would break when we make ∈ and ⊂ to be the same, but I have a bit of a fear that things tend to break later down the line if these two very distinct concepts are mixed up. Even though Logseq puts both on the same page, there is still a (blurry) distinction between the page properties in the header and the body with the page content. I would love to hear from an information architect about this topic.
To me, properties are attributes of blocks, while tags are are links. They can be mixed, but they are not identical. In a recent discussion we talked about using Logseq for collecting locations, in this case a location::(lat, lon) is is more natural, while a tag like [[(lat, lon)]] isn’t right. It is possible to disable page generation for properties, but not for tags. For numerical values, it would make sense to disable pages, because a page with the title (38,-177) don’t make any sense at all. It is not even clear it is a location, currentVoltage::(38,-177) would generate the same page.
Logseq is built on linking by tagging, so it is natural to write text with [[inline tags]] and many #other#tags, while I am not sure if inline properties work. If we replace #otherPage or [[otherPage]] by broader::otherPage, it might break a lot of the Logseq functionality, backlinks, plugins etc.
My original use case is the same as yours. I have a lot of tags that are related and would like to browse them in a neat tree-like structure, like in the Wikipedia example.
A simple way is to use SKOS-like properties (broader, narrower, related, synonym, …)
You would call my property “broader” “topic” instead, and not use the other properties, but otherwise it is exactly the same idea. We would both label each tag-page with the properties.
Also, I am just talking about taxonomies for simplicity, but as alex0 said, this is a very generic concept that extends to many other types of relationships. For example, the same mechanism could be used to build citation graphs or family trees. Logseq should support a generic tree search and a variety of different ways to interact with the results, as a tree, like on the wikipedia page etc.
I would like to accomplish exactly what you would like to do, with the difference that I can tag blocks with #Tension and make them show up in the graph view, while in your case I’d need to label them with a property topic::[[Tension]].
Don’t misunderstand me, I am not saying that Logseq does not lack way to search property trees. It absolutely does. The difference between our ideas is just an option to display the leaf nodes that link into the tree by tags.
Let’s say we depict the property broader/topic with an arrow → .
Then we get the following tree
Tension → Mechanics → Physics
up to this point our approaches are the same.
If you have articles, you would tag topic::[[Tension]], and you would get this tree:
SomeArticle → Tension → Mechanics → Physics
I would instead tag the article with #Tension, which gives this tree (a=>b stands for a is tagged by b):
SomeArticle => Tension → Mechanics → Physics
In principle all we need is for the tree search to have an option to show the leaves that tag into the tree to unify both approaches:
{{tree broader showLeaves:true}} will show the tree including SomeArticle, showLeaves:false will stop at tension.
I do generally like this idea of a tree query. I don’t think my query suggestion and @alex0’s tree suggestion are exclusive. In fact, it would be odd to have one and not the other, since both use the same property approach per page.
However, this tree feature would require an entirely new UI that more closely resembles graph view. Would it be rendered on the page itself? There’s a lot of complexity to it, and these feature requests on better hierarchies don’t seem to be getting much attention from the devs ATM. To have any chance of the tree query and UI being created, I think you need more concise/specific description of what exactly it does and looks like.
More realistic in the short term is this implied properties/hierarchies through property chains request. It would only be a subtle change to the existing query/table/list functionality.
@gax, I see your point with tagging vs properties. The problem is, to create this hierarchy in the first place, you need the property chain. I can’t just do #Mechanics in [[Tension]] and #Physics in [[Mechanics]] to create the hierarchy, because they might have other tags of a different nature as well, e.g. #Definition.
If [[Mechanics]] has #Definition, would a hierarchy then be Definition -> Mechanics -> Tension? I think what you’re saying is that the property chain, where the hierarchy type is specified by the property key (e.g. topic::), defines the branches of the tree while tags create the leaves?
This is similar to our ⊂ vs ∈ discussion earlier. The leaves are elements of a category, and the branches are the subcategories (and because each branch is still a page, it functions like an element of its parent branch). Using a tag would force a page to be an element/leaf because it can’t continue the property chain, and a page {1} that points to a topic:: would also be a leaf until another page {2} points to topic:: [[page {1}]], at which point it becomes a branch.
@antintin I do not see a conflict between your’s and @alex0’s suggestion at all, yours is a very useful addition with the only difference on how to present the leaf nodes that use #tagging. That would just be an option in the {{tree …}} command. For example, in a family tree, we might not want to show the leaf nodes.
There are a lot of ways to present this in the UI, but I unfortunately I am not very familiar with the possibilities of the UI API.
The most basic approach would be to have a query somewhere on an extra index page. The output of the query will be rendered as a tree on that page @alex0 has some ideas on his “Specify and display relations…” proposal. The only requirement would be to add a {{tree …}} command and add the ability to render that output properly, which is most likely already possible.
A navigation sidebar would also be nice. The “Knowledge Management for Tags” proposal has some other ways the tree could be rendered, including icons or faceted searches.
Good point about pages tagging other leaf nodes. I didn’t think about these. Personally, I think they should just be ignored, because otherwise the tree gets too deep and at that point we could easily run into cycles.
We have “Tag” pages. They are pages that have a property set that points to other “Tag” pages. In this case, they point to pages that have a broader/part of topic relationship.
Tag pages are regular pages and also can have content.
“Normal” pages link to these “Tag” pages, using regular #tags.
“Normal” pages can also be tagged in other “Normal pages”, e.g. in RandomPage.md
So far, this is all conventional Logseq, but currently putting in the broader attributes isn’t helpful, as they can’t be traversed.
Our graph could be searched with the {{tree …} command for any property. Here is an example to search by broader::.
This would build the reverse tree on the broader:: attribute starting at node “Physics”. I added the option “reverse” because we have only a broader:: attribute, but start at the broadest node.
The output of the {{tree …}} command could be rendered Wikipedia-style. I have left out the nodes that tag the leaf nodes. In principle, they could also be shown, but I don’t think this makes sense. We can always click on a node and look at the backlinks.
Great, I think we have everything sorted out for the most part. Although I don’t think the hierarchy/tree structure should render the contents of the tag pages — that would quickly make the tree unreadable.
Another thing: you separate [[SomeArticle2]] and [[Tension]]. I think they should both fall under “Pages in category Mechanics,” because [[Tension]] right now is still an element of [[Mechanics]] and not a subcategory. That’s exactly the strength of pointing to broader:: [[Mechanics]] instead of tagging #Mechanics, because an element can become a subcategory as your use case becomes more specific.
Beyond that, there just isn’t any reason to separate properties from tags like that in Logseq. The user can create that structure on their own, if they prefer. Your tag is still implying broader::
It wouldn’t make sense for a page that points to e.g. a topic:: property to be considered a subcategory just because it’s a property rather than a tag. Page {1} with topic:: [[anything]] is at the bottom of the hierarchy and thus an element until Page {2} points to topic:: [[Page {1}]]
Really the biggest change that needs to happen is Logseq needs to be able to identify these property chains, both top-down and bottom-up. Bottom-up is easy, but I imagine there will be some performance issues with top-down.
It’ll be sort of like an exponential query:
a query for broader:: [[Physics]]
queries for broader:: [[all results from the previous query e.g. Mechanics, Electromagnetics, etc.]]
queries for broader:: [[all results from the previous query e.g. Tension etc. etc. etc.]]
and on and on down the hierarchy until the results are exhausted
With the tree command I intended to render an indented list like the one we get with {{namespace RootPage}}
Check replies on my proposal, it’s not a big feature as you think.
On Discord the UI/UX designer said his next focus after Sync and Whiteboards will be improving the general UI/UX and we discussed different way to visualize query results and references sections.
Here there is a mockup I draw about references sections for example:
You might be aware of this, but do note that when LogSeq determines matching conditions in queries, a block does inherits its parents tags/links (but does not inherit its parents properties).
E.g. consider these blocks:
parent #parentTag parent-property:: true
child #childTag child-property:: true
Queries:
(#parentTag AND #childTag)
matches the child block, since it inherits tags/links from further up in the hierarchy
([property parent-property] AND [property child-property])
no match
Matching links/tags in parents was a change made some year ago.
I’m not very fond of LogSeq treating tags/links different from properties in this way. Especially since it isn’t that well documented. For my taste, I wouldn’t mind if LogSeq would consider properties to be inherited as well. For consistency, other matching conditions such as task status should probably be inherited as well in that case.