But it’s not what we are discussing here, it would be another huge topic.
If automatic all pages are edited to reflect the change in name of page being referenced that automatic change is an edit while I did not edit that file. So you’re recent changes are incorrect now.
Yes, intention is to just have blocks as atomic thought unit in the user interface.
It starts with the terminology: Instead of tag (which is only optical nature), page, page reference, block, block reference etc, I really would like to just simplify terms to “block” and “block reference” aka link to a block.
Btw: wouldn’t it be a great idea to call this app “Blocks”? Nice and simple to remember. Drifting off here… ![]()
Main points in this request are to remove page-tags, page-property ambiguity and fix the link reference filter (bug reports). It also would be cool to use it as umbrella post for further discussion about general page-block-unification ideas.
@alex0 Option to treat specific blocks as pages reads like you are only proposing changes to the GUI graph widget by displaying blocks with their title:: property. Having read ongoing discussion, I think, you also mean to have block references as first-class citizens in the app in general, don’t you? So querying block references similar to pages now, displaying blocks by ::title as node in the UI graph, etc.
That indeed would be nice - and probably more far-reaching long-term - request. In a first step we could keep status quo, and consider only “root blocks” (former pages) to be queryable and displayable in the UI graph widget.
Also: As logical consequence, wouldn’t that imply, that we could have one syntax [[]] (or (())) instead of two for block references? If everything in UI becomes a block, we don’t need to differentiate between page references [[]] and block references (()) anymore - would appreciate that!
IMO this is an internal implementation detail of how to provide technical IDs for blocks in the storage. I.e. it shouldn’t matter too much from UX point?
Without going into too much detail I would prefer:
All relevant blocks get technical IDs in form of UUIDs (including root blocks aka todays page, which currently have their title as ID). Hence no worries about duplicate titles when referencing blocks.
The first line of a block is its default title, with reference to following comment:
::title could be a replacement for default block title. But I wouldn’t see it as flag for whether to display the block in the UI graph widget. What about a block property display-in-graph: true?
I could have made it more clear, but I didn’t mention the graph view but the graph i.e. the structure of pages/tags as a concept.
I don’t see a good reason to change it and at this point there should be a very good one to make such a change.
Maybe a general purpose menu that appears using @, that search through pages, blocks, commands, templates etc and that paste the right syntax would be better.
I don’t like this idea of unifying pages and blocks because they are elements of two very different structures:
- Pages are connected together in a graph, there is no hierarchy.
- Blocks have a hierachical structure, they are trees and each tree has a page as its root.
We cannot have all blocks as nodes in the graph, I hope it’s clear how much inconvenient it would be…
Here there is why Tana is different:
- In Tana the nodes are generally short strings, like records of a database. Long paragraphs, though possible, don’t take advantage of Tana.
- Tana is basically a database with short strings of text as records but those records are also into a tree structure.
- In Logseq it is common to place whole paragraphs of text in a block.
- In Logseq there are multiple trees starting from each page.
So, if we want to be able to organize nodes in trees like Tana does, we have to be able to instantiate a node from a block and not only by creating a page.
Instead, if the issue is inconsistencies between pages and blocks when it comes to queries and other features I totally agree that pages and blocks should be treated in a more consistent way in the UI.
But I’m totally against unifying blocks and pages as concepts to enable a more Tana-like approach in an application like Logseq that among the other thing handles long paragraphs of text.
That said, I suggest to close this feature request since it seems confusing and instead focus of two things:
- Discuss how to enable a more Tana-like approach, including my proposal of using
title::properties. - Find the inconsistencies between how pages and blocks are handled in the UI and discuss them one by one.
1 Like
No, I disagree - they are the same structure.
A page is the top block of a blocks’ hierarchy. Other blocks are intermediate or leaf nodes of this tree. Every page spans its own tree of blocks. These trees are connected through their contained links/references. A page can link to another page or block (via page-tags for example). But same goes for all contained blocks! It’s just that block references are currently not nearly as powerful as page references with queries, UI filter and graph widget (and that’s OK for me).
I am sure, nobody meant that.
It’s about reducing software complexity and reusing common functionality, not imitating Tana.
Agreed.
As long as a block has a technical identifier and a title (default first line), it should not matter, whether there are longer paragraphs appended.
I suggest to keep this open for now, until further action is taken by developers for the two concrete issues and it’s clear, whether this is a bug or feature request in context of pages vs. blocks.
What I mean is that each page and its blocks are a tree and the connections are “being child/parent”. Additionally, blocks have an order inside a page.
Instead you can see pages like a graph where the connections are “referenced by”. References are placed inside blocks, but you can ignore this and get what we have in Graph View.
Alternatively, you can see every blocks as a node in another graph where connections are both page and block references, but this ignores the hierachical structure of blocks inside pages and their order. You may include the relations “being child/parent” and “being next/previous to” in this graph, but it wouldn’t reflect the fact that a block can have only one block/page as parent, only one previous and only one next block.
This is why I mentioned trees for blocks and a graph for pages.
To me, this is exactly what “unify pages and blocks” means. The verb “unify” is etymologically “turn into one”. Instead, it seems you mean just making them more similar.
So maybe you could rename this thread to something like “make pages and blocks more consistent”?
I think we agree that it’s just a matter of UI that doesn’t handle pages and blocks well, and not about the data structure discussed above.
Alternatively, you can see every blocks as a node in another graph where connections are both page and block references, but this ignores the hierachical structure of blocks inside pages and their order. You may include the relations “being child/parent” and “being next/previous to” in this graph, but it wouldn’t reflect the fact that a block can have only one block/page as parent, only one previous and only one next block.
But doesn’t this dualism already exist with current concept of pages?
A page is connected in a graph, and is also the root block in a block tree.
Constraints like “a page cannot have any block/page as parent” need to be enforced in the tree, and are not possible with graph relations.
So maybe you could rename this thread to something like “make pages and blocks more consistent”?
I think we agree that it’s just a matter of UI that doesn’t handle pages and blocks well, and not about the data structure discussed above.
Let me think about this. But in general I exactly meant, that pages and blocks are to be treated as same entity the user interface. If a page is a (root) block, there is no reason to have page-tags and page-properties in the query for example. There wouldn’t be inconsistencies in the filter.
I think, that I made it quite clear in OP to have written from user interface (UI) perspective.
Btw: Thanks for the discussion! I found myself to get a deeper understanding of all these structures.
For me the current pages are also blocks … that have a parent/child relation with the vault (which can be seen as a block. So all pages are childs of the 1 vault block. If you see it like that all current pages and blocks are the same and should be treated the samen.
The only difference would be that the blocks that are direct childs from the vault block generate files in the OS file system. But that is out of need and is not by design. You could bypass that by using SQLITE or something where everything is a records in a table but then you miss the simplicity of files we all like so much.
Concerning the graph, I have like 1300 notes currently and I never ever use the graph. Why?, because it is to big. The local graph can be interesting but then you miss a function like obsidian has where you can define the depth of relation level.
Continuing on the graphg view … something like TheBrain’s plex would be great. Where the current notes is always in the center with defined relations at specific locations. So pages with links to this block/page would be shown above the current note and links from this page/block to other pages are shown below the current note. TheBrain also has cousin relations (share a incoming link) and so on. Navigation your notes like that would met great. Triy TheBrain (you can use it in a free modus) and you will quickly understand what I mean.
3 Likes
Mathematically speaking, a graph is such a general structure that it can contains all the others (like a tree). A graph (or network) is made by two sets, the vertices (aka nodes) and edges (links).
As soon as you can model your entities as nodes or links you can just have an all-encompassing graph. But to better reflect the structure in Logseq, where “referenced by” and “being child/parent/previous/next” are very different relations, I came up with that trees of blocks + a graph of pages model.
I’m pretty sure “unify” would be intended as “make them one, indistinguishable” like nodes in Tana.
That is not the only difference, because the references made more often are [[wikilinks]] to pages, while in Tana you reference nodes from anywhere in the tree.
Do you mean the graph view, right? Be aware that:
- Logseq internally uses a graph database that is much better suited for this application than a RDB like Sqlite. This database stores everythings, pages, blocks, properties etc.
- Logseq decided to expose this partially in the UX but only a portion of the graph, i.e. the one where pages are nodes and references are links.
- So in Logseq terminology the set of Markdown/Org files in your selected folder is called “a graph” like Obsidian’s “vault”.
- Additionally Logseq shows this graph of pages as “Graph view” in its UI: there is a global version that provide a cool overview of your knowledge graph and a page-specific version that you can use to browse pages, much more useful than the global one.
Yeah I am also missing this variable relation depth level in the local page graph.
Totally agree with you here. A graph structure cannot appropriately reflect the hierarchical nature of trees - that’s why we have trees in the first place and not only graphs.
Conceptually I like to think of pages and blocks as follows:
A page participates in the graph via page references like [[page B]]. But it’s also the root block of the contained block tree. So wanting to treat a page like a normal block is very reasonable.
It also means the block tree is hidden from queries:
- Querying a block is not possible
- Querying for
[[page B]]does not findpage A, ifpage Ajust has a block reference to some block inpage B
And to come to the original request like page-tags for queries:
If querying for [[page B]], everything that directly connects to page B in the graph is returned, if I am not mistaken. page A needs to look at all links in its block structure. If a reference to [[page B]] is somewhere found, page A is returned as query result. But If this reference is in the very first block of page A, it’s not found. Hence there is an unneeded discrimination between page and block in the UI query, which leads to inconsistencies - probably similar to the UI filter, but I don’t know the implementation. I hope this makes sense.
Btw: Renamed the title to “Discussion: Unify pages and blocks”, as probably too wide-scoped for an atomic feature request. The most important issues for me are captured in the bug reports.
1 Like
This is because pages and blocks are different entities in Logseq internal database and with Advanced Queries you can use the same Datalog language Logseq is using to query its database.
Instead Simple Queries do some abstractions, they are processed and turned into Datalog queries. The rules on how to turn Simple Queries to Datalog are arbitrary and I think they were designed in a hurry to provide a simple query interface to the average user.
So your issue is much more superficial than you think, it’s about Simple Queries only and doesn’t require much change to Logseq as a whole.
Yes, exactly. You can make it more tidy by arranging pages on a circle and draw links as chords, like in this image:
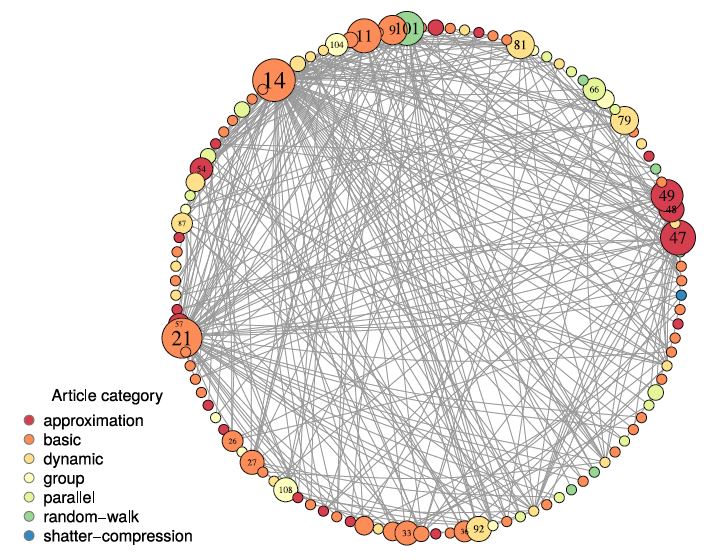
And the trees of blocks spawn from each page to the outside of the circle.
As a metaphor, let’s think of the circle as the “pages hall” and pages as doors with their name displayed on them.
Let’s say we want to represent the process of referencing a page using [[wikilinks]] in a block:
Imagine a person that has the indication of going from a block to the referenced page. The person would go from the starting block to the “pages hall” and then enter the door of the target page. But who is in the hall can just see from which door the person came and to which door it went, , and that’s our “link”.
It’s a link between pages, despite the person started from a block inside a page. The pages hall is unaware of blocks and their hierarchical structure.
1 Like
Yes, this makes sense. But there probably another issue with the filter then.
In the longer term it would be awesome to “unify” pages and blocks even more, being able to connect blocks in a graph in the same way as we do now with pages - while retaining block hierarchy in the outliner. For example:
page A
- ((1234))
page B
- some block title
id:1234
Currently I need to create an additional link [[page B]] inside page A, in order to get page A as query result from query {{query [[page B]]}} (and to see their connection in UI graph widget).
It would be nice, if a query recognizes that the block referenced via ((1234)) already “belongs to”/inherits from page B.
Looks awesome! Combine this with features “drill in”, “drill out”, “highlight chords of focused pages”, “follow next link” & Co and you have a nice top/down view of your knowledge graph (even more compact than current widget).
Do you know the Graph Analysis plugin? It has more feature than built in Graph View.
And for blocks there is the Markmap plugin.
Imagine if the two types of view were combined, maybe showing the trees of blocks of the selected pages and links that goes from block to parent page to referenced page are visualized.
Still a vanilla guy in terms of plugins ![]() (with a bit of custom CSS). Trying to capture the essence of an app before packing additional functionality on top of it. I also think, core features like pages/blocks concept should go directly into Logseq in longer term.
(with a bit of custom CSS). Trying to capture the essence of an app before packing additional functionality on top of it. I also think, core features like pages/blocks concept should go directly into Logseq in longer term.
Thanks for the names, I will definitely try these and other plugins next.
To summarize above concept, current approach in Logseq is:
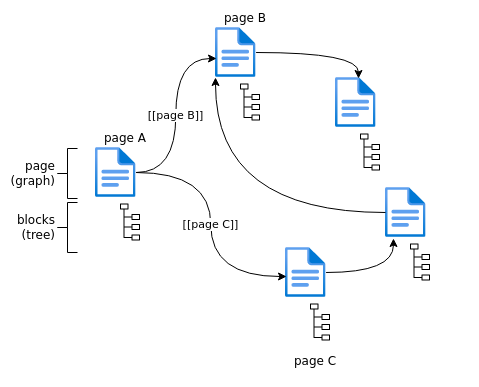
Here is how I would like logseq to be in general. Granularity now is block-level:
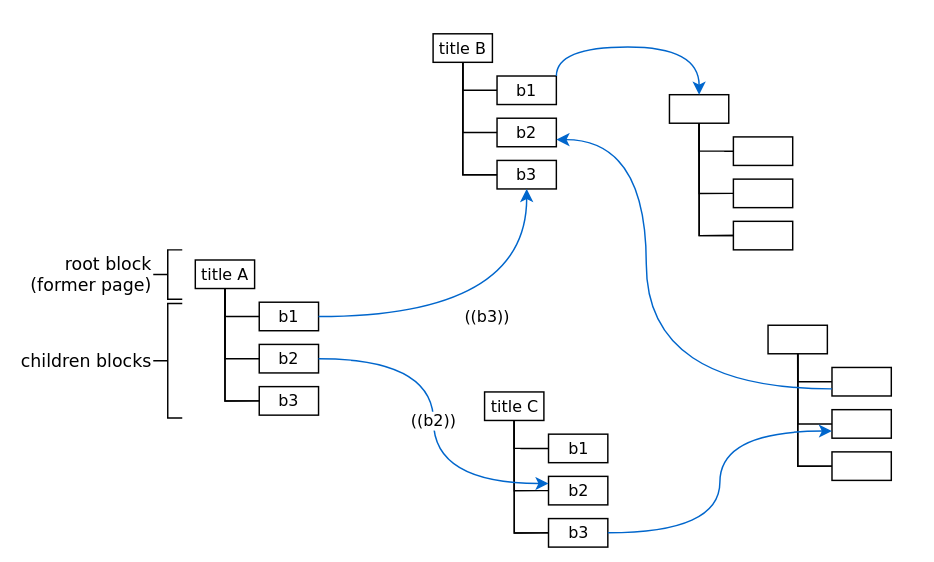
Then say we want to get every block that has a link to block title B or its children as query result, by writing something like:
{{query ((title B))}}
(title B would need to be unique or some sort of ID)
Root block title A knows, one of its children blocks b1 has a link to b3. b3 is child of block title B. Hence b1 is returned as query result. We would still store all root blocks as Markdown files in the filesystem, no changes. But “page” as concept is completely isolated in the persistence layer architecture-wise. And users/core app just use the concept of “block”.
I am not sure, how capable Logseq is already under the hood to operate on a block level. For example pages already have block attributes like :block/name, :block/properties etc., when clicking on “Show dev data”.
1 Like
Would you like if this was accomplished by only improving the UI? For example:
- Press @ to search through blocks, pages, commands etc.
- When selecting a block a reference with ((ID)) appears
- Referenced blocks, once rendered, could present an option, for example a button apperaring on hovering, that let you quickly replace them by performing the search again
- In the future query builder you could use blocks to filter results, not only pages; you would just search for a block, insert it and an Advanced Query is created; you would see the block ID only in the query code; the UI would hide block IDs completely
1 Like
Yes, these are great examples. Most parts of the UI can deal with just blocks. Some ideas:
- Show references in “Linked References” on block-level (not only page references)
- Filter
 “Linked References” on block-level (not only page references)
“Linked References” on block-level (not only page references) - Create block via
((title B/b1/b11)): would create
in- b1 - b11title B.md, similar to creating pages with[[foo]], but now block-level. - Link to block via
((title B/b1/b11))besides todays free text block search.
You type((title B/)), it suggests((title B/b1)),((title B/b2))and so on. You type((title B/b1/))and auto-complete suggests((title B/b1/b11)). This is similar to syntax for page namespaces and would unify them on a block-level. - Simple query or query builder for block references
{{query ((title B))}}or{{query ((title B/b1))}}(see above example) - Place blocks in Favorites
- Extend UI graph widget to display block relations
There are still some valid edge case for page like file stats, getting or opening the file of selected block in external editor etc.
Sounds good. This would need some sort of query implementation change I guess. Filters or searches of parent blocks should also retrieve children blocks (child block “extends”/“is-part-of” parent block). Currently blocks seem to inherit only page references from parent blocks.
Basically UI and core logic see all data as one big tree of blocks that can be connected freely as graph:
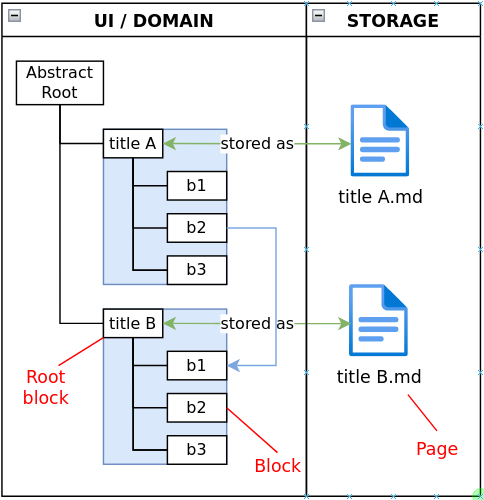
(don’t want to be too spammy with the sketches. But It sometimes can describe more than words)
1 Like
As I said some posts ago, I don’t see how ((title)) could work to reference blocks. Only ((id)) can work and this is why I mentioned changes only in the UI.
The point is that you don’t want to be prompted by a dialog (as it happens when editing a page title) everytime you edit a block that was reference somewhere. Also it is hard to guarantee that no blocks have the same title when you move Markdown files around (I already have to check that no Markdown files have the same name, doing the same with blocks would be impossible).
Also, [[Parent/Child]] syntax is used for namespaces, that are a different concept from referencing path like your ((Parent/Child)).
Maybe, what could work is being able to manually assign aliases to block IDs:
- This is a block
id: 12345-67890-12345
alias: People/Alice
Then when mentioning [[People/Alice]] it would point to that block instead of a page.
Yup. But If title B/b1/b11 doesn’t exist, you wouldn’t get any popup dialog. And every referenced block gets an UUID, same as today. Only if path is redundant, you there is a choice dialog, which block is meant. I would find this to be a cool feature to quickly navigate through the blocks structure.
Is it so different?
- foo
- qux
- bar
- qux
foo and bar might be seen as block-scope namespaces to separate equally titled blocks qux and remove ambiguity. Of course you still need identifiers, when referencing a unique path.