I cannot seem to find how to create pages with properties. Is there a way to?
Also I have a list of block templates but I don’t want them to be blocks anymore, I want every block like - book, project, program, person - to be pages instead. Can I apply templates there?
Also currently I distinguish blocks by tags, e.g books go with #r/book tag, programs - with #r/program. Now if I start making pages for them, how to organize them structurally the same way, using this hierarchy? Should I type manually something like r/program/The full name of a program I'm writing about?
I’m designing a new database for notes taking. I started with enumerating entities that I’m gonna comment on. All of them were blocks initially.
For example:
resources (short: r)
book
program
projects (short: p)
article
program
I could have have type-properties to distinguish them, but I opted to just tags: #r/book, #p/program. They are much easier to enter, they don’t allocate additional line i.e. don’t make blocks taller. I also don’t have problems with learning what is what: r - resources, p - projects, that’s fine.
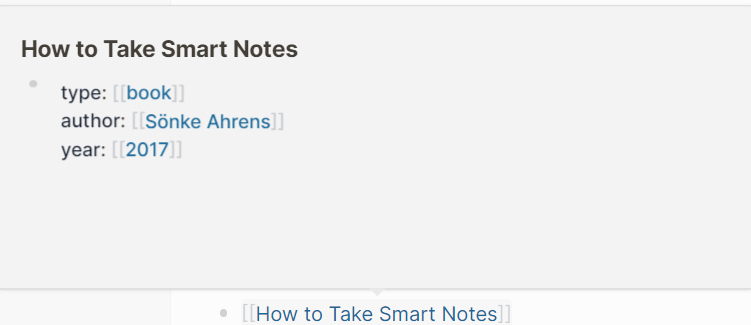
I place those type-tags right before the title, e.g.:
#r/book **Sönke Ahrens - How to Take Smart Notes - 2017**
I was quite happy with blocks until I realized that all such entities are better to be pages.
So now I’m thinking about placing those pages on disk.
A block like the one I just provided would turn into a page:
r/book/Sönke Ahrens - How to Take Smart Notes - 2017
So as you see I have to keep the path (the type) inside the title.
In Logseq I cannot create two pages with the identical title
If I enter [[page title]] - it will just link the existing page.
If I use Ctrl-K search and select “create page” from there, it anyway just opens the existing page.
So I will have to make titles unique anyway, say by prefixing them
which implies the existence of a workflow of adding those prefixes, as this must not be random
one possible example I described earlier - prefixes by entity types that reduce the probability of titles clashes
Linking entities becomes difficult as when I start type - a lot of unrelated stuff will be suggested
Say if I want to write a Dune book note I don’t want to see Dune movie, whatever prefix of postfix it might have to workaround the obvious conflict in this case.
Using queries to output additional information from the field is fine, but I wouldn’t like to start writing queries just every time I need to learn what Dune is - a book or a movie.
if the mix is valid, should either / filter them / This is easy with queries, thanks to the properties.
If real folders were not sort of ignored, they could serve a good service for base pages classification.
Consider a page “Dune” located in r/books.
It could add an auto-property like $path with the value of r/books/.
We could have then used them in the queries.
We could opt to seeing those properties in lists of objects: r/booksDune
It could also be used in autocompletion: the pages could be separated/grouped by those paths in the suggestion list.
If I place movies and books in different graphs, how can I then reflect on both movies and books?
Is it possible to reference different external graphs from another graph?
Continuing with the example, how to reference both “Dune” book and “Dune” movie while writing a review in this case?
More generally, I consume:
articles
books
courses
lessons
movies
lectures
and produce:
articles
books
programs
systems
podcasts
audiobooks
videos
Currently I imagine all those be in one graph.
Going back to the initial question of page properties: I see now how props get applied in the “first block” — which is actually the root frontmatter block (though not YAML, but anyway). Another smart architectural finding!
My current take on this:
1. Use templates like this:
type: r/book
template: r/book
OR
template: r/book
#r/book
2. Use this template to make book pages.
Title: r/book/Frank Herbert — Dune
type: r/book
So I’ll get a sort of double input which I should maintain manually: the type thing r/book is getting doubled (As I noted above, it could have been avoided if Logseq used folders.)
An argument for using tag #r/book instead of the type-field is that I don’t need to write queries to list all the books in my graph: I just need to click the tag.
One more point. A good way to reduce duplicates even further would be using authors, release years, editions in the titles.
I understand, that it’s gonna be more difficult to fetch those different bits. But that depends on a goal of the database. Say if I don’t need to capture all the real-world dependencies of all possible objects then I wouldn’t probably be bothered with allocating field storages for things I don’t care.
@mentaloid I decided to move all type-tags to frontmatter, as you advised. It was not clear to me why it was a bad thing to use tags in the text until I started writing queries.
The problem with “just tags” is that they’re read from the entire document, including nested blocks. So if a block is marked with a #note tag, then all its parents are as well! Which of course makes querying by tags ineffective.
This will also affect references (links). Before, I was going to use linking “unconstrainedly” i.e. just put links where they are better fit to. But it blurs the dependencies as well. So I’ll switch to a field instead, like refs, which I’ll be using to put essential links. E.g: link to a book (or books) being commented.
How do you mean this? Because that’s not technically true.
The reverse is (sort of) true. That is, a child inherits the links of its parent.
If we query for references to note.
Then something like
a book [[note]]
details
Will have in the parent block :block/refs to the note page
And in the child block :block/refs will not have this, but in :block/path-refs it does.
In reverse then,
some header
a book [[note]]
Will have no :block/refs for its parent block, but will have :block/refs in its child block to the note page.
(I’m use :block/refs specifically here, so as to say what is actually stored in the back end, not so much what Logseq shows. Because what Logseq shows vs. what is stored has led to confusion in the past I noticed.)
Sorry, I read it several times but still the whole thing is not clear for me.
The query language is very strange for me, I cannot grasp the basics (and not really sure where I can read about it)
If we query for references to note.
What does this mean: querying references to note?
And in the child block :block/refs will not have this, but in :block/path-refs it does.
Which child block? Do you mean the one you provided:
a book [[note]]
details
or some different block?
Is there a visually represented model somewhere to look at?
We want to have block that have a link either through [[ ]] or # to the page note.
Sorry that my sentence was unclear!
Yes!
No… This is because the model is… Quite simple.
Think of all the data as living in one giant table. Each record in the table will have 3 things.
An entity identifier
An attribute
A value belonging to that entity attribute combination
We call these tuples and they look like: [entity attribute value]
This is most of what advanced queries are made up of. A series of tuples to define what data we are looking for.
In the query language when we don’t know what something is we can replace that with a variable to be filled in, this is anything starting with ? followed by letters, not sure about other symbols.
Generally we have no idea what identifier a block has in the big table. So we use a variable like ?b or ?block.
:block/refs is the name of a specific attribute available to the entity of type block.
The value for this attribute will be a list of one or more other entities in the big table.
These entities can be either blocks or pages themselves, with their own set of attributes.
So when you query for blocks which are tagged with #note, you are looking for tuples of [?block :block/refs ?note] (we don’t know the entity identifier of note)
Then we have to specify what ?note we want, else we get everything.
In this case we want the page with the name note.
The tuple for that would be [?note :block/name "note"]. In this case the attribute :block/name is always the lowercase name of a page.
So we want entities who’s name is “note”. As pages need unique names in Logseq, this is only 1 result.
Therefore with those two tuples we get all blocks that have a reference/link of either [[note]] or #note.
@onkeltem My note taking usage pattern is similar to yours (many inputs to many different outputs), although in a different setting. I also started working namespaces, which seemed more logical at the time, until I started posting questions here and watching tutorials and I concluded that namespaces are not the optimal way to go, given the different meaning of certain tags i was using (e.g., a company name can be my employer, a technology vendor that builds a product for which I want to capture information for, etc.)
Even though I didn’t read the entire post, my suggestion is this:
You will be able to design the optimal schema for your note taking db if and only if you fully understand how that db is going to be used for (i.e., the types of questions you want to ask) and how that can be accomplished with queries.
Queries can do extraordinary things - from building indexes, filtering for information etc. Just look at @Siferiax’s posts and the incredible things she has built over time)
Queries are extremely powerful, but very difficult to master; only the simple ones are trivial but they are not that useful (polite way to say - almost worthless)
Once you have figured out the queries you need ask, then identifying the right metadata (i.e., properties) is easy.
The only challenge is that you are tackling the problem with the very specific requirements you have today that will definitely change in the future
Looking at what others have built is always useful (Youtube, articles etc.)
I don’t have anything to share, as I am in the process of implementing the steps above. A good starting point for defining properties: