After investigating this a bit, I have found solutions to some problems at least. Not all.
First, Zotero can be configured not to add tags automatically. This option can be set in the General settings tab. By default it is on (unless I set it on by myself and forgot it already).
Second, if some publications in existing Zotero collection contain some tags already, and if these were created automatically and you are not happy with them (having used Zotero for many years on a daily basis I have never found them useful but they just did not bother me too much), you can delete them, see the paragraph on Automatic Tags at the bottom of the page on Tags and Collections.
Third, surprisingly the previous procedure aimed at deleting the tags will (probably) leave some tags in the collection. Obviously not all tags qualify as automatic and the procedure only deletes those tags that were created automatically. Honestly, I do not understand this issue at all because I have never created a single tag in Zotero manually. But obviously Zotero makes some further distinction among the tags (I do not know, maybe tags extracted from the PDF and tags obtained from the web page). Anyway, those remaining tags can be deleted manually. This procedure is also described in the above linked page. But it is as simple as right-clicking on the tag and chosing Delete Tag from the context menu.
Fourth, the annoying limitation of the above procedure is that it only works on a single tag. With a few hundred tags in the whole collection this would be a nightmare. And no, selecting all tags is not currently possible in pure Zotero. There is, however, an extension to Zotero called Zutilo, which enables choosing multiple tags. It is just that the corresponding functionality must be explicitly enabled (by default most functionalities are disabled or actually hidden). The functionality is called Remove Tags. Select all papers in the Zotero collection, right-click and choose Remove all tags… Done.
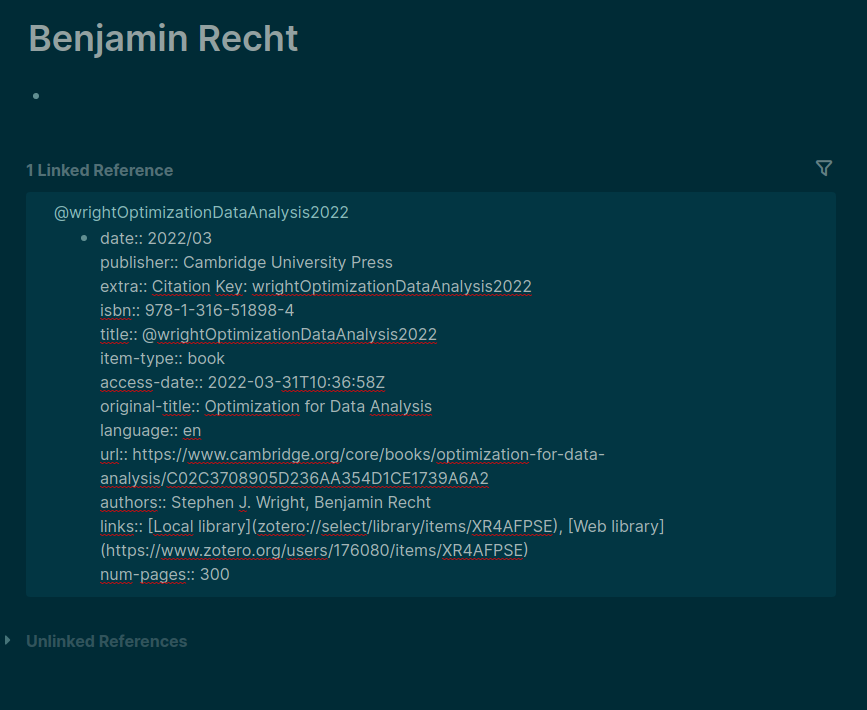
So, all these are steps on the Zotero side, before you actually import some reference using /Zotero command. But what if you have already imported quite a few Zotero references into your graph (as I did), which cluttered the space with all those pages such as Attachments and Abstract and paper and alike? Here, on the contrary I only have questions.
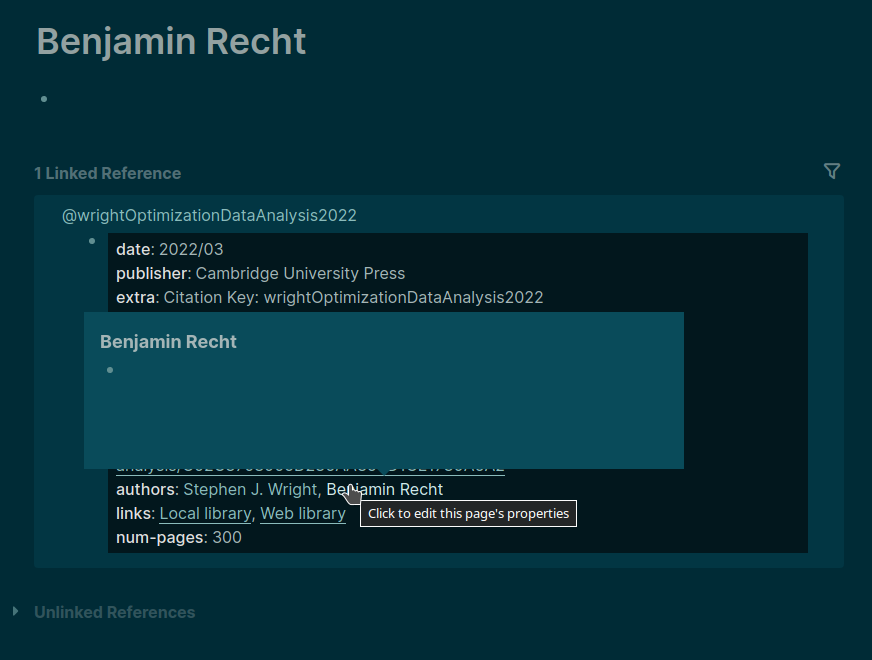
Will it suffice to remove the double square brackets from the pages created for the imported publications? For example, instead of [[Abstract]] leave just Abstract? Is this all that needs to be done?
I am tempted to automate the process of stripping all those files started with @ (corresponding to the pages created for the imported references) of the left and right double brackets (using sed). A single-line code and I am done. But cannot I destroy my Logseq graph/database when editing these files directly using an external tool? In particular, I do not quite understand what the role of pages-metada.edn file is. But certainly with a few dozens of imported references I prefer avoiding the need to edit all those pages manually in Logseq.