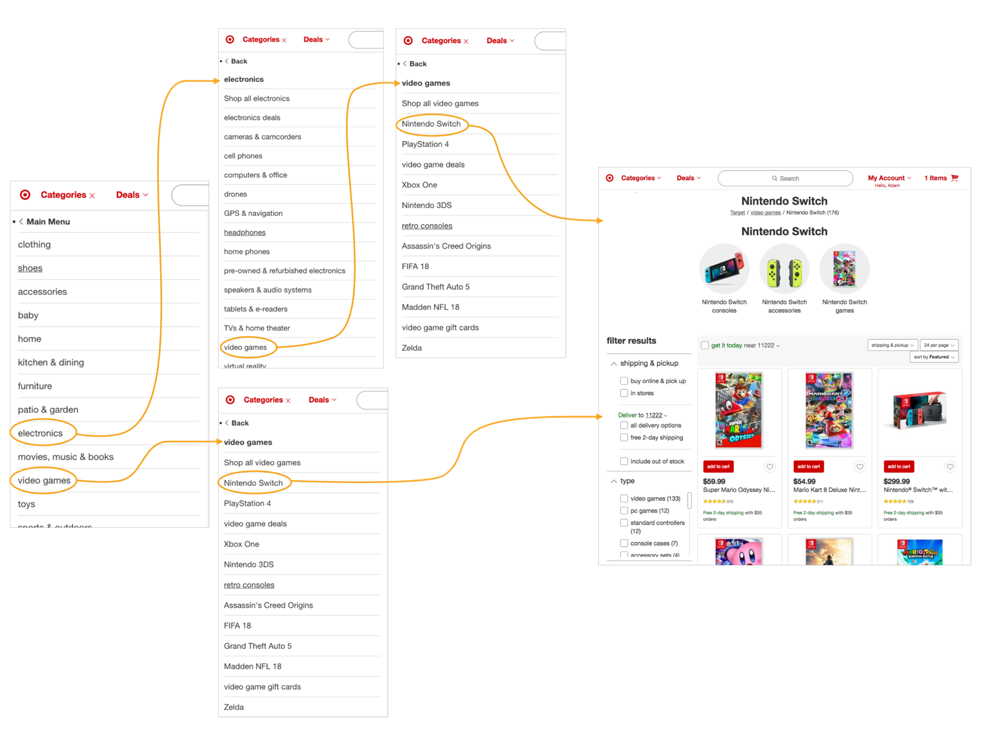
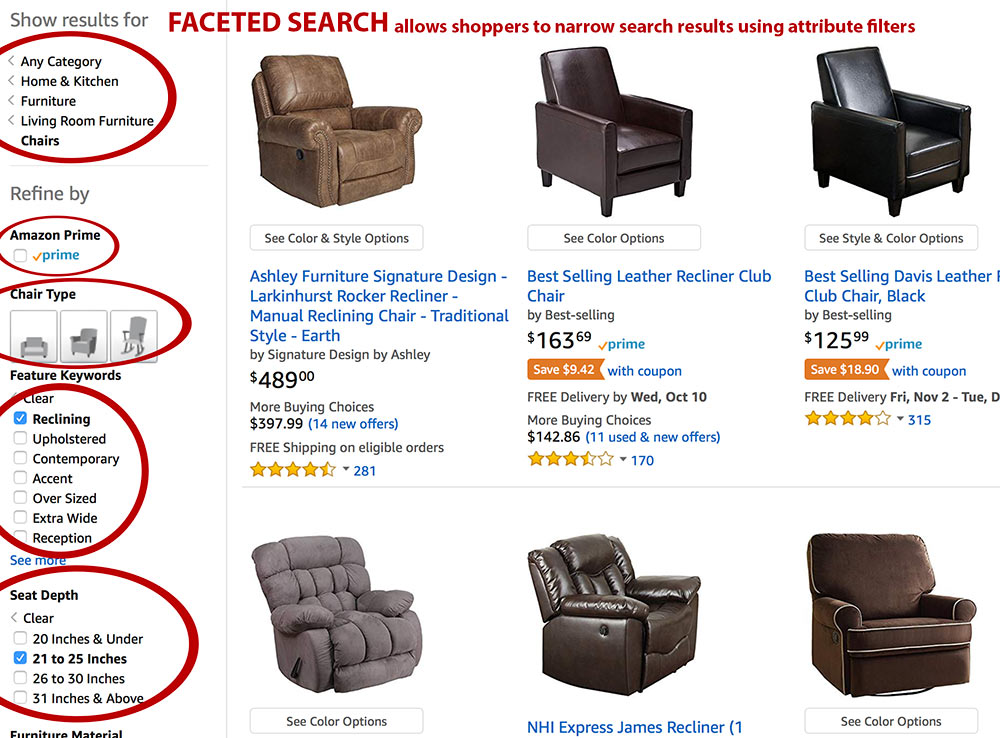
POSSIBLE REASON ONE: POLYHIERARCHY
One good reason would be to enable polyhierarchy - so a child can have multiple parents. This might be easier to implement over a flat file structure.
You could define one document tree, for example “Neuroscience”, to capture a growing collection of notes on various neuroscientific topics in something like a standard academic topic space (anatomy, physiology, perception, cognition etc). There might be a specific Page on perception in monkeys that matters to you there.
Then you could define another tree, like “Evolution”, and the same Logseq Page about perception in monkeys could appear in that tree as well. The same note could appear in two hierarchies.
This might be much easier to implement over files in a single directory than in a directory tree.
If files were moved into a directory tree used by the OS, they would probably be in a folder structure on the hard drive that matches the nesting order of the first hierarchy you define. The database would have to overlay additional hierarchies over those dispersed notes.
Maybe the database functions to allow polyhierarchy are less complicated if executed over a flat collection of files. That would be a good reason to just have a single Pages folder.
But I’m not sure this is actually the case. The database would have to map out which files are relevant to a hierarchy anyway.
I’ve been involved in discussing the idea of polyhierarchy in a few threads in the forum. It’s a rabbit hole, but may be of interest.
POSSIBLE REASON 2: REFACTORING
Another good reason would be to allow flexible hierarchy refactoring, like Dendron allows.
- What Hierarchy Refactoring Is
Hierarchy refactoring is a “Find and Replace” operation that works over the filenames (and hence namespace positions) of notes. In Logseq terminology, it would work over Page names, and thus transform Namespaces/Hierarchies.
This is a massive innovation in knowledge organization, I think - on par with the block and bidirectional link in terms of importance. A potential revolution in knowledge management.
Using my two topics of Neuroscience and Evolution, you could decide you want to situate all your biology topics within your Evolution hierarchy. Perhaps you’ve changed your mental schema for how all those things fit together. You now see Biology as a special case of a process that includes chemical evolution and computerized evolution simulations, and you want your namespacing to reflect your new organization of that knowledge.
In Dendron’s syntax, you could run a query for (Neuroscience)\.(.*), which would return all your notes (Pages) in your Neuroscience topic tree.
That’s the “Find” part of a “Find and Replace” over names in the Pages namespace for “Neuroscience”. Results of the “Find” operation are called the “capture group” for that query.
Then, for the “Replace” part, you could write something like (Evolution)\.(Biology)\.$1\(.*).
The “$1” symbol matches the first term of the capture group - so in this case it matches the term “Neuroscience”.
That would refactor your topic tree. So now if you traversed your graph from your Hierarchies root page, “Evolution” would be a top-level Name (like a folder), with disclosure triangles that would expose Biology, and within there, Neuroscience.
But then if you decide that organization of knowledge isn’t working for you anymore, you can refactor your Hierarchy again as easily as you Find and Replace text in a file.
- Refactoring Redeems Hierarchy
A criticism of hierarchy as an organizational structure is that it’s both rigid and fragile. Dendron’s flexible and scalable hierarchies are neither.
Dendron is built as a VS Code plugin and is very onerous to learn for a non-techie. It’s aimed at technical users. Logseq supports hierarchy as an organizing principle, and is aimed at a broader market. If Logseq combined the best of Roam Research and Dendron into a single PKM tool, that would be extremely powerful.
It’s possible that flexible, scalable, refactor-able hierarchy is also more easily implemented by renaming files in a flat folder directory than by moving them around an OS directory tree. The representation of file location in the database might be a lot easier.
I’m not a developer, so I’m not sure. Maybe “move” operations are as easy as “rename” ones here… but my sense is that to support both polyhierarchy and flexibility, a flat collection of files would be a lot easier to handle.