Yes and you can also decide the order of each block, you can format them with highlight for example, you can compose hierarchies using embedded blocks, you can use as element of the hierarchy not only pages but also block references, links to blocks (with the syntax [Label](((block-id)))), plain text to emulate folders, URLs, queries, images etc.
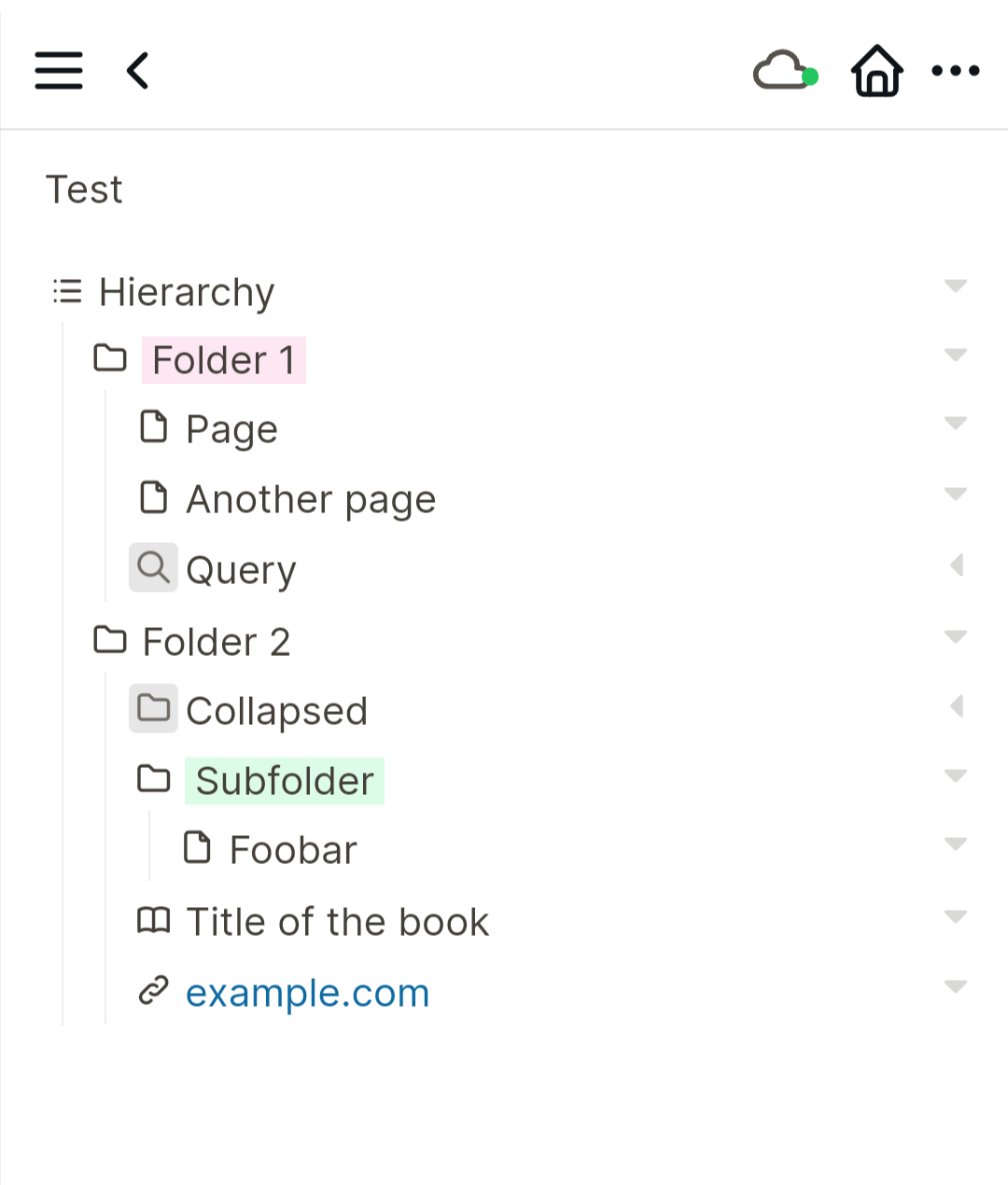
Of course, with your approach we keep all the native functionalities LogSeq’s yields in the management of our indexes or hierarchies (here synonyms) (hadn’t thought of applying the embedding capability to indexes which you pointed, thanks a lot).
I for one came to LogSeq lured by the thinking-resemblance approach to blocks and pages (which are blocks as well, as you have insisted): bidirectional linking and immediate retrieval of previous concepts (here “tags” or better “pages”) at your fingertips, mimicking natural memory connections. But knowledge is that and structure as well. I was becoming suspicious that LogSeq would be useful for me in the long run, since there appears to be no section or plugin to manage hierarchy between pages, but after reading and understanding your posts (the epiphany came with this one Different ways to structure data - #49 by alex0), it now comes clear to me how unwise it is to suppose that a program whose basic building-block is hierarchy (structured blocks) wouldn’t have in its nature a way to bring structure into the bigger ideas (the page-blocks here).
Whether explicitly intended or not (second my guess), granting complex intertwined polyhierarchies to your pages is possible and managable in LogSeq at a very reasonable cost, and, once you’re on, it does feel like playing (in reference to what a fellow posted here earlier). All you have to do is to use the basic LogSeq’s linking, blocking and database query capabilities. You’ve just been showing the way in different threads of this forum. Thanks for that.
1 Like
I’m struggeling with this as well.
I agree with previous points that there seem to be some convergence in the note-taking field to a “mixed strategy” including
- bidirectional
[[wikitextlike-links]] - categorization hierarchy
- tagging
I have observed this particularly within the Obsidian community.
Goal, desired properties
One way to frame the problem would be: With an increasing number of notes, it’s not that easy to find a convention or structure that
- is low friction
- fights duplication
- e.g. “do I already have a note related to what I’m about to write now?”
- relates to entity linking, single point of truth, linked data vocabulary
- allows heavy linking
- e.g. in LogSeq, linking to blocks has many drawbacks vs. using ordinary
[[page links]]
- e.g. in LogSeq, linking to blocks has many drawbacks vs. using ordinary
- allows some rudimentary (at least) strategy for invariant enforcement/schema adherence/integrity checks (be it, to a part or fully, manual)
…this list goes on and on…
…and here, far down - with regards to short-term feasibility, definitely not desirability! - we’re approaching holy grails such as
- connecting our personal knowledge base, with full structure and semantics, to a global, distributed one
- prototype example: https://graph.global (by Mek of Open Library/Internet Archive)
- implemented, somewhat messy, example: https://anagora.org
- applying machine reasoning to our knowledge base
This is elaborated on further in the closing section - but first: LogSeq.
LogSeq functionality considerations
I’m not sure more “special features” of LogSeq would take us further in this regard. As has already been pointed out: structure is a very personal preference.
I think the best LogSeq can do right now is providing as much general, use case-agnostic, capabilities as possible, and doing it as well as possible - e.g. allowing user customization through general and stable querying functionality, properties:: implementation, and also of importance: customizable interface (example feature request).
That would allow experimentation. Among the user base, various strategies for structure could evolve, and the community as a whole can get inspiration and gain knowledge. Some converge could be expected with time.
My current LogSeq schema
Implemented only to a part, and in no way a perfect solution.
It consists basically of the following:
A hierarchy of categories
encodes: is-a relation
through: namespaces
example: [[vehicle/boat/submarine]]
The above page has a
alias:: submarine
for allowing shorter [[submarine]] link names.
I have chosen not to adhere to strict subtyping for my category taxonomies. Yes, Barbara is left unsatisfied as a consequence. The opposite choice here probably could allow for some clever tricks on how page properties could be utilized. But how the possible LogSeq queries that could perhaps make use of that would look… I don’t even want to think about. Even less, debug them.
Instance-to-category assignment
encodes: instance-of relation
through: a type:: page property with the category as target
example: page [[Boaty McBoatface]] has a page property
type:: [[vehicle/boat/submarine]]
Then, each category page has a query that lists all its instances.
example: page [[vehicle/boat/submarine]] page has a query
{{query (page-property type <% current page %>)}}
which will list all submarines:
- Boaty McBoatface
- HSwMS Östergötland
- …
drawbacks:
- refactoring is very tedious
- the LogSeq bug of not resolving
<% current page %>when page is opened in the right sidepane is a great nuisance
I use faceted classification:
- meaning: we can have multiple, distinct, hierarchical taxonomies, and the final classification of the page will be the intersection of the assigned category node for each taxonomy hierarchy
- this is possible in LogSeq since properties can have multiple values, we get optional support for
- example: page
[[HSwMS Östergötland]]hastype:: [[vehicle/boat/submarine]], [[military_thing/naval_vessel]] - in the field of information science, faceted classification is generally considered a very good thing - and it does brings a lot of benefits to my LogSeq classification system
I don’t use polyhierarchies:
- (and it wouldn’t be possible if using LogSeq namespaces for the category tree)
- meaning: every category node has at most 1 parent node
- a beneficial consequence is that it allows short, pragmatic node/category names, while we’re still conforming to the all-some rule: it’s generally easy to append an additional hierarchical level, with a short name, in order allow further refinement/specificity
- example: a category path
/military_thing/naval_vessel/can, because of no polyhierarchies, be read equivalently as/military_thing/military_thing--naval_vessel/. Allmilitary_thing--naval_vessels aremilitary_things - so/military_thing/naval_vessel/conforms to the all-some rule.
Leaning towards fewer and longer pages
benefits:
- hierarchy enforcement
- faster entry
- faster re-factoring
- moving stuff around within the block hierarchy of a page is easy and fast
drabacks:
- linking to blocks is inferior vs. to pages (and the nead increases as we reduce page granularity)
- the target of a tag can’t be a block - it can only be a page, so this is a a general drawback of less fine-grained pages
- the still-present, much-too-old LogSeq UI bug of sometimes not displaying the full page is a terrible friction point (…this bug manifests itself both in the main pane and side pane!)
extensively using, for better overview within a page:
- headings (# …, ## …, ### …)
- folding
Tagging
i.e. page tags
through
tags:: myTagpage property- tagging individual
- blocks
#myTag
- blocks
used for: less formal, sometimes add-hoc, additional structure, such as marking a page as belonging to some bigger area, or collecting a number of related pages (instances or categories) together
benefit:
- easy to tag not just pages, but also individual blocks
“Authority control”
For each page, I try to add some page property where the value is some URL pointing to some external reference for the intended scope of the page. Usually this is a link toa Wikipedia article. The purpose is to attach an identifier to the page that I can use if, at some later point in time, the page name isn’t enough for me to quickly determine what the intended scope of the page is. This can be seen as some rudimentary/poor-mans linked data vocabulary or autority file connection.
Example: When re-visiting the page [[grammar]] I might ask: does it refer to my internal LogSeq grammar? To grammar in natural language? To database grammars? To help comes the page property wikipedia:: https://en.wikipedia.org/wiki/Formal_grammar which answers the question.
Further comments
-
this system is most of all just a convention I have for myself, in order to have an established standard for how to enter and structure information in LogSeq. Its intention is not to allow a lot of “implementation” such as using a lot of clever queries etc. I use queries very sparingly. I’ve gone down that route a few times, but the unstable state of LogSeq is just too prohibitive (bugs, and to a part incomplete documentation)
-
about is-a and instance-of relations
- difference betwee the two: the type-token distinction
- I don’t use “category” pages differently from “instance” pages, e.g. pages of both kinds can contain contents, and can be used as tags
-
I make heavy use of aliases
- often I want contents for similar but perhaps not distinct concepts on the same page, so terms for those concepts would be alias-ed to the same page
- I usually provide aliases for alternative spellings, for singular+plural forms, and for both abbreviated
and unabbreviated versions (yes, due to combinatorics this can indeed end up with a page having a lot of aliases) - this makes linking easier
- I can just add
[[..]]'s around all occurences in various texts to get linking - I can easily find the pages to link by using the “Unlinked References” section
- I can just add
-
I avoid page names/aliases that are too general, and that are often used in the general language
- example: for the concept of frames in symbolic AI I don’t have a page name/alias “frame”, but stick to a qualified page name such as
[[frame (AI)]]
- example: for the concept of frames in symbolic AI I don’t have a page name/alias “frame”, but stick to a qualified page name such as
My current graph has:
- ~500 pages
- ~18k lines
- ~123k words
- (for pages/*.md, so excluding journals - but I don’t use them much)
The ultimate, non-existing, note-taking system
Here, I’m leaving the LogSeq domain. This section is on note-taking systems in general.
A possible ultimate goal: a note taking system that is formal, fully semantic, fully linked (internally and externally), type-safe and invariant-enforced.
There is currently no such note-taking tool.
I regard the quest for a total knowledge representation system, as in the general information science sense, with full structure and semantics, as a perhaps unsolved problem.
“Note-taking system” might sound innocent, but would probably rather be one of the harder domains to model. It would need to be so all-encompassing: we take notes on facts, ideas, thoughts, beliefs, possibilities, to mention a few. It includes relations that are, e.g.: temporal, probabilistic, causal, conditional. Sometimes a connection/link would need to be specified along all of these dimensions in order to be fully described. Any of these relationship types are not unlikely to send shivers to a practicing ontologist. That’s about link/relationship types. Another link/relationship strata would be arity - bi-directional links only would be a limitation (relates to hypergraphs further down). Yet another would be the posibility of linking not only to notes/nodes/entities - but also to some set of such (relates to meteagraphs further down).
One direction would be some complete and fully-specified ontology. It would need to include all possible link relationships as well. To grasp the vastness of such a potential ontology, we can have a look at a published ontology for cultural heritage sites. That’s a 240-page pdf - for a reasonably narrow domain.
Another, but partially overlapping, perspective would be to see our data as a knowledge graph or graph database. Well, LogSeq could possibly be described as a knowledge graph. But if we want a knowledge graph that is fully-semantic and fully-typesafe it starts getting complicated. For full generality and expressivity the graph model won’t suffice. Probably not even its generalization, hypergraphs. Probably rather the generalization of those - metagraphs. This is following the lines of thinking of Ben Goertzel - see further down.
One obvious inspiration in the graph-based realm is the Semantic Web, with its roots in the early 2000s. Unpractical, never really fully realized, and using the much-dreaded XML for everything - but, it is impressively rigorous, extensively researched, and very well specified. Within technology, it probably has a world-record in the (no. of published papers)/(actual practical use) category. The intersection of Semantic Web technology and personal note-taking has seen several product attempts, and not surprisingly: even more academic papers. See for exampke Max Völkel’s thesis (alt.) or his later papers. These are the best sources I have found so far on formalizing link relationships and their types in the area of personal note-taking. For a lighter take on the subject, see for example Jonathan Reeves blog post.
Among initiatives along other but related routes, and more recently, we have e.g. Hode by Jeff Brown. Hode can be described as a note-taking DSL in the form of a hypergraph editor (text+GUI). It is implemented in Haskell, so a checkmark on “type safe” would probably be an understatement. It is/was a single-developer tool, or prototype. It is now abandoned.
An interesting approach, that has not been tried yet as far as I know, would be to implement a note taking system in TypeDB: a fully type safe graph database with built-in schema. That’s a good start, and it gets even better as we encounter such gems as an included inference engine and hypergraph capabilities. The TypeDB+note-taking idea has been mentioned by the creator of Hode, and also by e.g. by Robert Haisfield.
One could also take a category theory approach, e.g. with ologs (“knowledge representation with category theory”). Or - one step closer to note-taking, utilizing the Categorical Query Language (CQL) (my understanding: “a graph database language with category theory”). It is created by David Spivak et al., who were also behind the ologs. Ologs has been mentioned before on the forum, e.g. in A meta-graph as a set of linked graphs by @gax, who also briefly mentions CQL. He also presents a take on LogSeq vs graph databases.
For completeness we should also mention frames (my understanding: “knowledge representation inspired by Objective-oriented modeling”) as a possible note-taking data model.
This section should end with what is perhaps currently the pinnacle of formal, graph-based knowledge representation: Ben Goertzel’s knowledge representation model ([2]). It has its home within his OpenCog symbolic AI system. This model, and implementation, has (my understanding:) very far-reaching expressivity, is fully formalized, totally type-safe, total invariance/schema enforcement, includes its own ontology, includes/allows all the relationship types I mentioned previously, allows inference (and includes the inference engine), and relationship expressivity is on the metagraph level: they have arbitrary arity, and can point not only to entities but to arbitrary sets of entities.
Other links
ScalingSynthesis.com is a goldmine for any and all ideas and initiatives for bringin structure and semantics to note-taking. A project by Joel Chan and said Robert Haisfield.
Ivo Veltichkov has developed a semantic ontology-based Roam PKM system:
Transferring it to LogSeq is perhaps not impossible. At least not if some of the most restraining LogSeq bugs would be fixed.
changelog
2023-05-09: significant edits and additions
12 Likes
@and_yet_it_moves This is an incredibly thorough post, thanks!
This is the most important point for me. Build the core first, then add cherries on top.
Core/basics: Organizing and tagging features, block-scope, usability, solve common bugs
Cherry: Whiteboard1, Flashcard, AI assisted inference, Sharing of knowledge graphs, and others
1: Don’t get me wrong: Whiteboard is a beautifully crafted feature! Only talking about how to invest project time constraints here.
In this regard I’d like to emphasize
and tried to express some of the needed block features:
- Allow to reference blocks in three ways: by ID, name, namespace
- Improve query: Searching for [[page x]] should consider references to blocks inside this page
Current strategy - my take
Just to highlight importance of personal preference in organizing systems, here are examples how I am structuring notes. Basically it’s all about properties.
is-a relation
Boat.md:
extends:: [[Vehicle]]
- boat notes
- ...
Submarine.md:
extends:: [[Boat]]
- Submarine notes
- ...
I value concise, natural page names and rather dislike these long “term trains” from Namespaces. Instead trying to keep it simple and prefering Wikipedia styles: Page name (distinguishing context).
instance relation
Similar to @and_yet_it_moves , I named it instanceof.
Boat McBoatface.md
instanceof:: [[Submarine]]
part-of relation
I also tend to use the part-of relations extensively:
Wheel.md
partof:: [[Car]]
Car.md
extends:: [[Vehicle]]
All in all the properties’ approach allows to dynamically browse through page relations iteratively by looking at linked references, clicking on some link and continuing from here. What currently is lacking:
- graph queries - search through page relations as part of knowledge graph (relations expressed with properties)
- being able to sort linked references of pages, e.g. to give page links in properties higher precedence, to have better overview of relations
- Flexible page layout - and being able to have per-page default queries
6 Likes
Check this request as one of the most important missing pieces for me:
1 Like
A note to the returning thread-reader: I just made some significant edits and additions to my post/comment above, Different ways to structure data - #63 by and_yet_it_moves
1 Like
Also being able to express these relationships at the block level would help avoiding creating a nearly empty file for each tag (potentially tens of thousands to millions, in case someone wants to import the taxonomy of animals).
@and_yet_it_moves, thank you for your detailed post! [quote=“and_yet_it_moves, post:63, topic:8819”]
- about is-a and instance-of relations
- difference betwee the two: the type-token distinction
- I don’t use “category” pages differently from “instance” pages, e.g. pages of both kinds can contain contents, and can be used as tags
[/quote]
We had a discussion on elements vs subclasses a while ago:
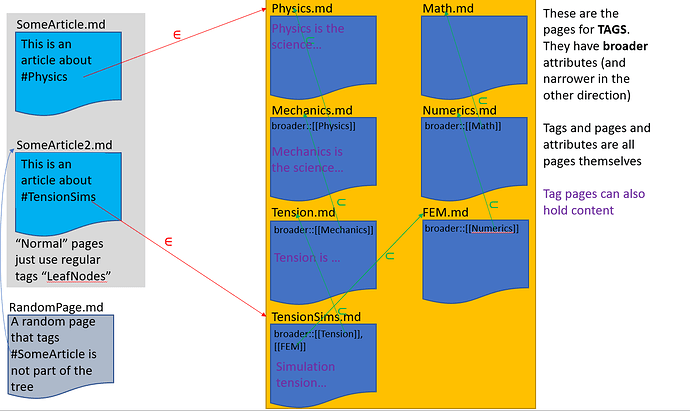
More details in the thread: Create multiple levels of hierarchy with property chains (similar to Breadcrumbs in Obsidian) - #15 by gax
I am not an expert in classification, but I don’t have a good feeling merging the two concepts. I would not be surprised if this caused subtle issues later.
@alex0’s proposal would cover both, with options for the search function to display results either way. A question that remains is how to deal with namespaces. If one were to import multiple taxonomies, e.g. LCC, one would get lots of collisions. I think we could use Logseq’s namespaces for this purpose without any problems. Thanks to the fuzzy search for tagging this already works.
All of this is already supported by Logseq’s data model, what we are lacking are efficient ways to manage hierarchies other than editing every single page, as well as a proper way to display them.
Another possibly relevant thread on what is missing to make Logseq a better graph database: A meta-graph as a set of linked graphs
I would love to see inline properties.
Well put. That is absolutely central - I just hope LogSeq will change its strategy to prioritizing that way.
That is clearly more general and allowing.
I chose namespaces for the category/is-a tree mostly to be able to easily view the actual hierarchy.
You don’t find it limiting that you can’t visualize the hiearchy?
1 Like
My attempt to make hierarchies with types with CSS:

3 Likes
@and_yet_it_moves: Do you have a solution for keeping multiple taxonomies apart if you already use namespaces for categories? E.g. there is a category “Vehicles” in LCSH
Yes, tbh. But thinking in namespaces as one-dimensional hierarchy is too restrictive and limits organizing ability for me. I just can’t get used to it - the properties’ alternative feels like the most ideal way. It needs to get some more feature love though. I consciously did not suggest any graph visualizations here (of course theses would be very nice), as from my experience time-consuming to implement.
Instead harvest low-hanging fruits. Example: per-page default queries. These might provide a quick answer, how to visualize hierarchy/relations. Let’s stay with the boats - browsing for relations in link reference currently is cumbersome:
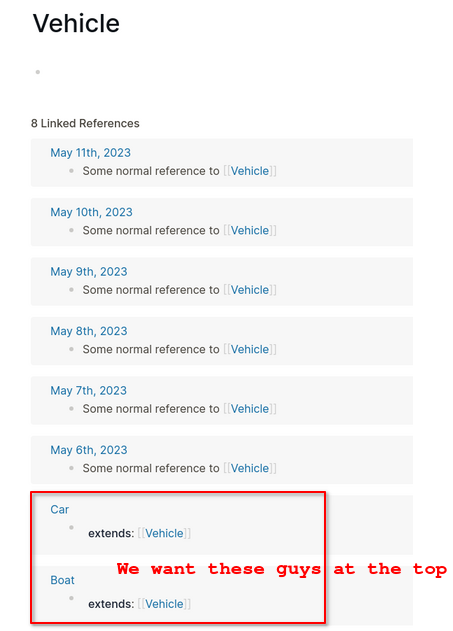
Instead we could define one or more default queries per-page by using :current-page (dynamic variable) and place it either at page header or foot above linked references or hiearchy (position customizable):
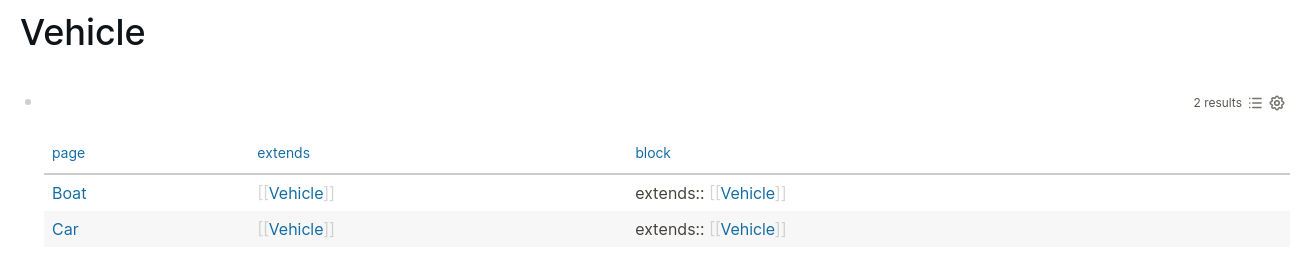
This probably is much easier to implement, as there already exist journal default queries. Just as an example, curious there are better ideas.
(This is above query, if interested)
#+BEGIN_QUERY
{
:query [
:find (pull ?b[*])
:in $ ?cp
:where
; these two lines are just to optimize performance
[?p :block/name ?cp]
[?b :block/refs ?p]
; the actual work - filter by link in :extends
[?p :block/original-name ?po]
[?b :block/properties ?props]
[(get ?props :extends) ?prop_extends]
[(contains? ?prop_extends ?po)]
]
:inputs [:current-page]
}
#+END_QUERY
1 Like
Loved reading this topic today. Very inspiring even though I don’t follow all of the terminology used ![]()
I currently use some namespaces but I’d rather not.
Any good ideas for these?
video/films; video/series; video/youtube
cycling/electric; cycling/citybike; cycling/roadbike
I currently use the namespaces to group these activities so I can not only count when I did an individual activity, but also a total count of the group as a whole.
Thanks guys!
@Siferiax I’ve tried this kind of scheme, I call it “foldering”, it failed really badly for me and wasted a lot of time. Typically one thing is in multiple groups (how about a youtube film series on road and electric bikes), and single hierarchies just can’t capture these kinds of relationships.
Personally I think it makes more sense to tag blocks with properties, which themselves have some sort of relationship between themselves. For example you could tag something with “roadbike”, and the page for “roadbike” has a property that says that it is a special case of “cycling”.
Now we run into a problem if we want to tag something “electric”, because maybe there is also a category “stove/electric”. The proper way would be to have each taxonomy live in a different naming space, so that e.g. vehicles and cooking_appliances both can have a category “electric”.
That’s a problem solved by namespaces, but it conflicts with the use namespaces to implement hierarchies. Maybe @and_yet_it_moves has a solution?
Another problem of using namespaces for hierarchies is the impossibility of efficient knowledge management. Once the knowledge has been entered, it still needs to be curated.
Let’s say you start off using Logseq to catalogue bike stuff. You tag with “electric”, “roadbike”, “citybike” etc. Eventually you have so many pages that some hierarchy makes sense. If you use namespaces, you have to edit every single occurrence of every single tag on every page. That is not a good solution. What is really needed is the ability to take e.g. the tag “roadbike” and put it under a newly created category “cycling” and have this work automatically for every page tagged “roadbike”. This doesn’t work with namespaces, but it works when you use properties (such as “broader”, “narrower”) on the tags themselves. The only downside is that there is no good search support to hierarchically display the results, but given your query skills you’d be the person to get it done.
Maybe it is possible to develop a query that, given the block ID of an indented index, treat it like namespaces i.e. looks for page references in the children and include them in the query.
For my purposes not really. It’s one of the problems I run into honestly lol.
I have cycling/roadbike and roadbike for example. The first is to tag entries to indicate I did the thing. So I did a ride on my roadbike. The second is to tag articles with roadbike related information.
I like the suggestion of using wiki style names for that distinction maybe.
Something like roadbike (info) and eh, roadbike (ride).
I do like that idea. Querying properties is annoying though.
I would name it as electric bike so that’s fine.
I’ve totally done this before ![]()
But I believe Logseq is now better at actually cascading this when you change the page name. Having said this I haven’t tried it.
(I went from work/project to project to work/project. My graph is personal only, but there was some personal/work overlap)
Edit: can confirm this works now, changed my cycling/electric to electric bike and all linked references got updated appropriately.
![]() Thanks! You’re probably right, though as said querying properties is difficult.
Thanks! You’re probably right, though as said querying properties is difficult.
It’s why I went from using things like area:: [[finance]] to area:: finance and added area as a property with page references in the config. (Can’t remember what the setting is called exactly)
I guess I’ll have to experiment ![]()
1 Like
Yes that should be possible. There is recursive search capability.
Here’s an example related to tasks:
So that would also be a solution for me I think ![]()
Define an index as
- [[cycling]]
- [[road bike]]
- [[electric bike]]
- [[city bike]]
And then query for all references to pages based on child block below cycling in the index.
It is a little inconvenient I must admit.
Old where for my queries:
[?r :block/name ?current]
[?b :block/refs ?r]
[?b :block/page ?p]
[?p :block/journal? true]
New where:
[?v :block/name ?current]
[?h :block/name "hobby"]
[?i :block/page ?h]
[?i :block/refs ?v]
[?c :block/parent ?i]
[?c :block/refs ?r]
[?b :block/refs ?r]
[?b :block/page ?p]
[?p :block/journal? true]
I’m now using the Hobby page for the index only, instead of having other info there as well. That would make the where even bigger lol.
Further edit, as I’m experimenting, here’s the above where, but for the use of properties. (I figured out how to actually use the property value, still dislike it)
[?g :block/name ?current]
[?g :block/original-name ?naam]
[?r :block/properties ?prop]
[(get ?prop :groep) ?groep]
[(contains? ?groep ?naam)]
[?b :block/refs ?r]
[?b :block/page ?p]
[?p :block/journal? true]
I feel like I have completely butchered my graph at this point in time lol. I do like the experiment and ideas though.
The only thing I see against the use of properties is that one would need files for all pages. Most of those files only have a properties blocks. This feels like a lot of overhead. I just need to tag blocks with an activity and the activity itself doesn’t necessarily need a page.
Using namespaces I would only have need of a page for the group to bundle my queries on.
However using indexes I actually only need Hobby to be a page and can put the queries for each Hobby there.
![]() I notice this is giving me quite some things to ponder about
I notice this is giving me quite some things to ponder about ![]()
2 Likes
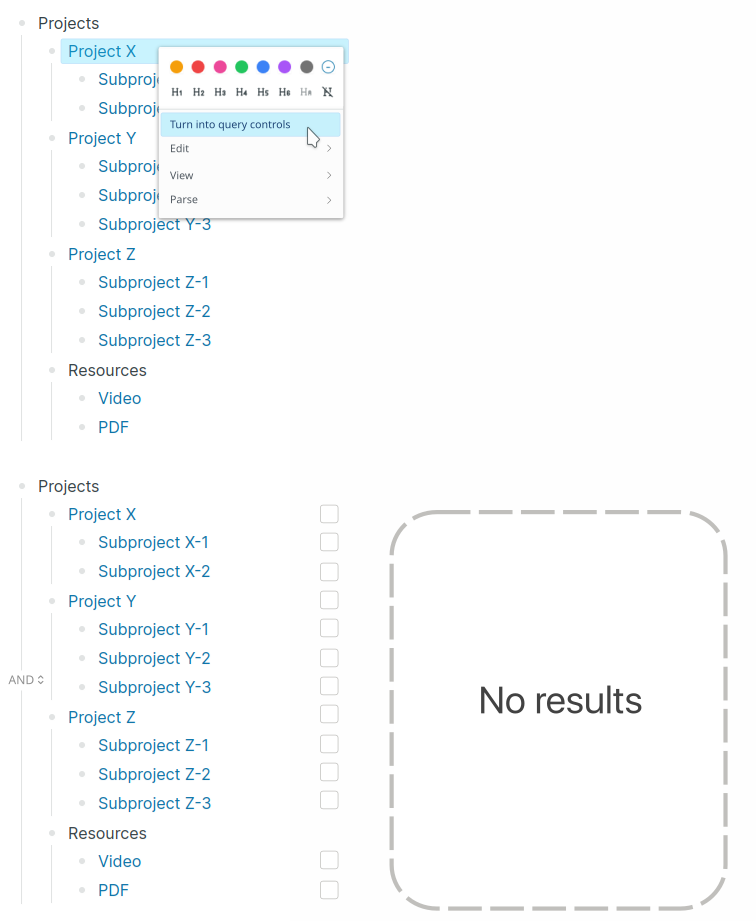


3 Likes
@alex0 I like that idea! It looks really neat.
Here’s my solution so far for my hierarchy.
I may or may not have gone a little overboard with the index thing ![]()
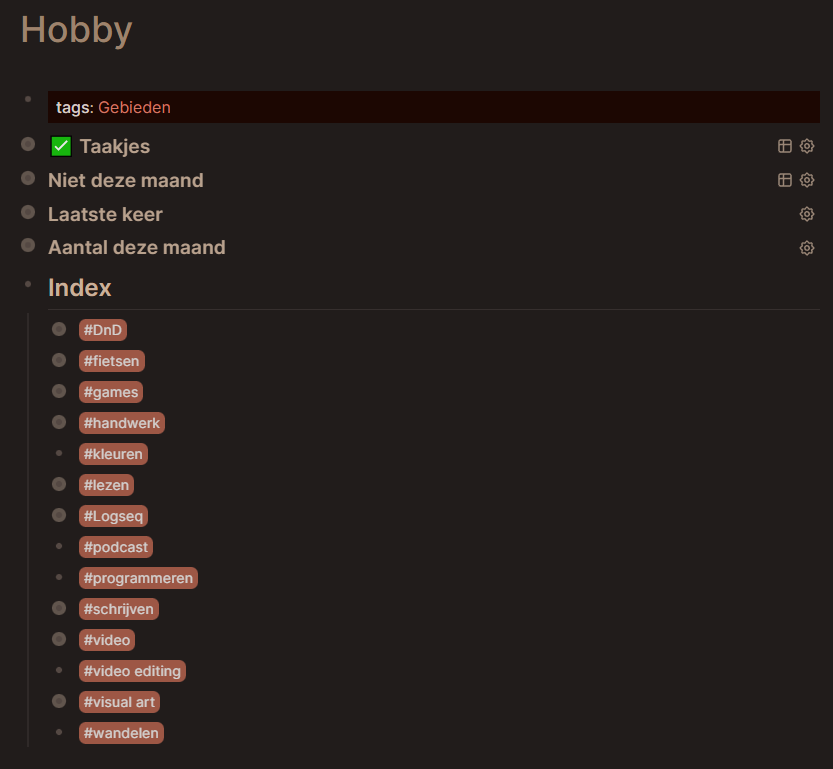
Taakjes (tasks), Niet deze maand (not this month), Laatste keer (last time) and Aantal deze maand (number of time this month) all use the index for data retrieval.
:where
[?h :block/name ?current]
[?i :block/content "## Index"]
[?g :block/parent ?i]
[?g :block/refs ?a]
[?a :block/original-name ?act]
(or-join [?b ?a ?g]
[?b :block/refs ?a]
(and
[?c :block/parent ?g]
[?c :block/refs ?r]
[?b :block/refs ?r]
)
)
The or-join makes sure that the top level and children are being considered.
(below that the actual query spec for each of the questions, this is just to get the right blocks as the input for that)
Cycling has been done like this now.
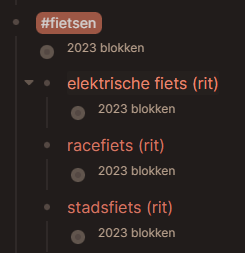
And video like so.

(the 2023 blokken is a query to get all blocks that reference that page)
Still some namespaces left to reconsider, but it’s only a few. I’m quite pleased with this new way of doing things.
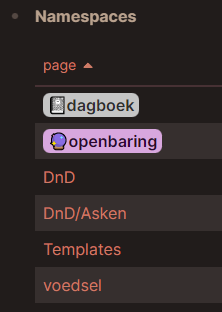
(FYI I use properties for a P.A.R.A. hierarchy actually. As you can see Hobby is an area (Gebieden = areas). All entries in the index then have the property gebied with value Hobby)
4 Likes
I am looking for a toggle button to include/exclude refs from a query (like in the mockup I shared). Do you think it would be possible to use TODO and DONE for each entry of the index to include/exclude that block reference from the query?
